이전 포스트에서는 DataFrame의 Index를 기반으로 데이터를 조회하는 방법에 대해 알아보았다. 이번 포스트에서는 위치를 기반으로 데이터를 조회하는 슬라이싱(Slicing)과 iloc[]함수에 대해 알아보도록 하겠다.
슬라이싱(Slicing)을 이용한 데이터 조회
이전 포스트에서 데이터를 조회하는 방법으로 다음과 같은 방법이 있다고 소개하였다.
- 행의 고유한 key인 Index를 이용하여 내가 원하는 데이터 조회
- 데이터의 위치를 이용해서 데이터 조회(Slicing)
- 조건을 이용한 데이터 조회(Boolean)
이번 포스트에서는 "2. 데이터의 위치를 이용한 데이터 조회(Slicing)"에 대해 다뤄보도록 하겠다.
경우에 따라선 데이터의 위치가 조회에 있어 중요한 key로 작동하기도 한다. 그 예는 다음과 같다.
- 고등학교 중간고사 전교 30등까지의 데이터를 조회
- 30명이 있는 반에서 6 ~ 12번째 주번이 누구인지 조회
- 월 소득의 상위 10% 데이터 조회 또는 하위 10% 조회
위와 같은 위치를 이용한 조회를 하려면 기본적으로 행의 순서가 일정한 규칙에 따라 나열되어 있어야 한다. 데이터가 아무런 규칙 없이 위치해 있다면 사용하기 힘들다. 때문에 규칙대로 데이터를 나열하는 정렬(Sort)과 함께 쓰이는 경우가 잦다.
Pandas의 DataFrame은 기본적으로 0부터 n까지의 index를 순서대로 자동 생성하므로, Index를 기반으로 한 조회와 위치를 이용한 조회의 차이를 알기 어려울 수 있으나 Index와 위치는 다음과 같은 차이를 갖는다.
- Index는 단순 행의 위치뿐만 아니라 다양한 정보를 담은 특정한 key로 만들 수 있다.
- 위치 기반 조회는 Index로부터 자유롭게 단순 위치로 데이터를 조회할 수 있다.
예제를 통해 위치를 이용한 데이터 조회를 해보도록 하자.
1. 예제 데이터 가지고 오기
※ 예제 데이터
이번 포스트에서도 저번 포스트에서 사용한 예제 데이터를 그대로 사용해보도록 하겠다.
>>> import pandas as pd
>>> import numpy as np
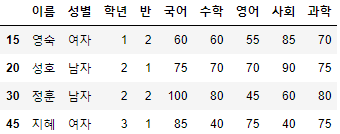
>>> FILE_PATH = "시험점수.csv">>> 시험점수 = pd.read_csv(FILE_PATH, encoding="euckr")
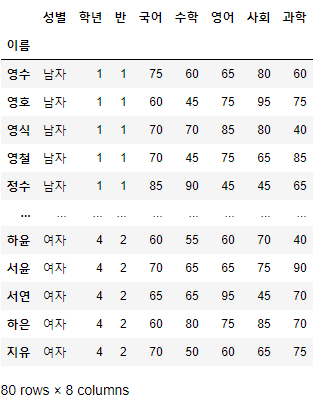
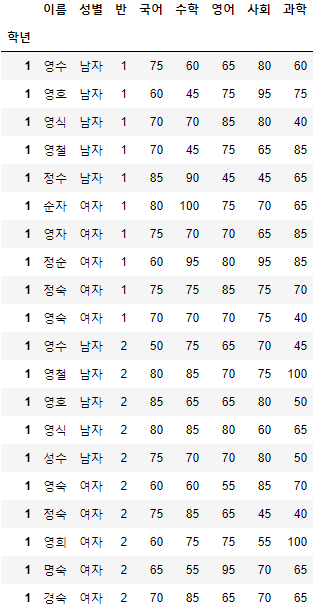
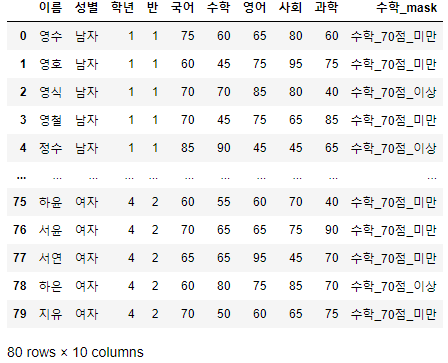
>>> 시험점수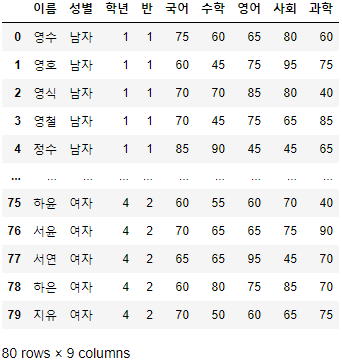
- 해당 예제 데이터는 이름, 성별, 학년, 반, 국어, 수학, 영어, 사회, 과학 총 9개의 열과 80개의 행으로 구성되어 있다.
- 한글이 깨지는 경우, 위 코드처럼 pd.read_csv(File_path, encoding='euckr')로 불러오면 된다.
2. 순서를 이용해서 데이터를 가지고 오기
- 순서를 이용해서 데이터를 가지고 오는 방법은 크게 2가지로 다음과 같은 코드를 사용할 수 있다.
- df[start:end]
- df.iloc[]
- 두 함수는 기능은 거의 동일하나, 엄밀히 따지면 첫 번째 코드인 df[start:end]를 슬라이싱(Slicing)이라 하며, df.iloc[]는 어려운 말로 명시적 포지션 검색이라 한다.
- 간단하게 말해서 첫 번째 녀석은 start부터 end까지를 잘라서 보여주는 것이고, 두 번째 녀석은 해당 위치에 있는 것을 가져오는 것으로 이전 포스팅에서 소개한 df.loc[]와 성격이 유사하다.
2.1. 슬라이싱을 통한 데이터 조회
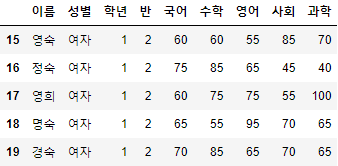
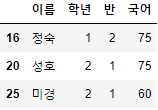
- 예제 데이터인 "시험점수"의 10번부터 20번까지 데이터를 조회해보도록 하자.
- df[start:end]
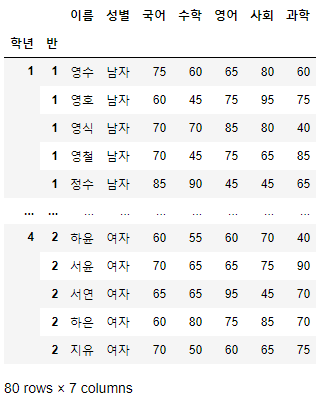
시험점수[10:20]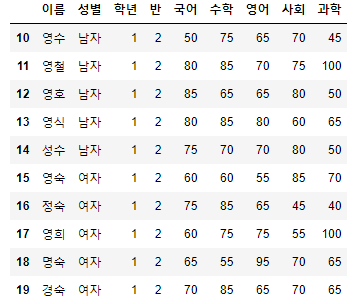
- 아주 간단한 코드를 통해 데이터를 자를 수 있다.
- 슬라이싱을 통해 가지고 오는 행의 번호는 start 이상, end 미만이다.
- 슬라이싱은 단순히 처음과 끝만 설정할 수 있는 것이 아니라 간격도 설정해줄 수 있다.
- DataFrame 시험점수의 10번부터 20번까지를 2를 간격으로 조회해보도록 하자.
- df[start:end:step]
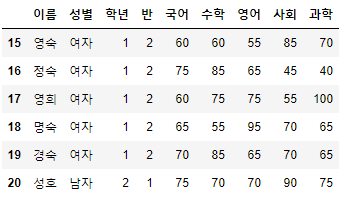
>>> 시험점수[10:20:2]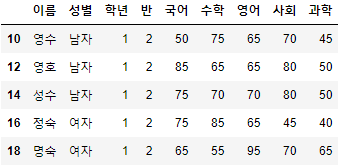
- start나 end 둘 중 하나를 지정해주지 않으면, "start부터 끝까지" 또는 "처음부터 end"까지로 슬라이싱할 수도 있다.
- 68번째 이후의 데이터를 전부 조회해보고, 처음부터 15번째까지의 데이터를 조회해보도록 하자.
>>> 시험점수[68:]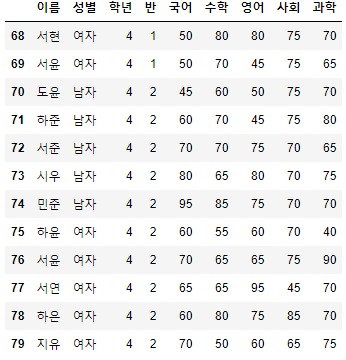
>>> 시험점수[:15]
- 여기서도 간격을 설정해줄 수 있다.
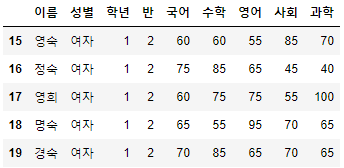
>>> 시험점수[:15:2]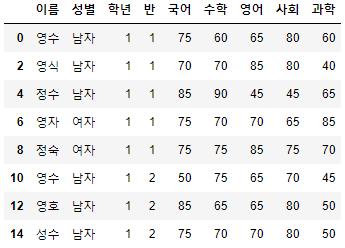
2.2. 슬라이싱을 이용한 역순 조회
2.2.1. Step을 이용한 역순 조회
- 슬라이싱의 각 인자들을 음수로 부여하면 역순으로 조회할 수 있다.
- 전체 데이터를 역순으로 조회하려면 step을 -1로 지정하면 된다.
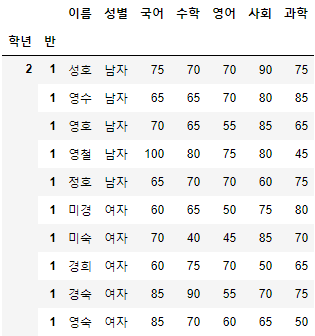
>>> 시험점수[::-1]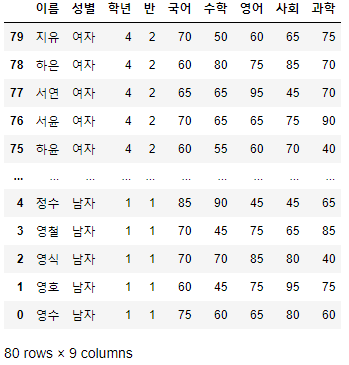
- step을 -1로 설정하고 start를 지정해주면 start부터 역순 조회도 가능하다.
>>> 시험점수[4::-1]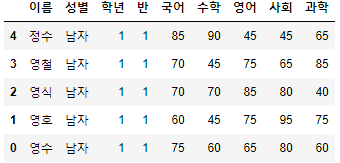
- step을 -1로 설정하고 end를 설정하면, 맨 뒤에서부터 시작하여 end까지로 조회된다.
>>> 시험점수[:4:-1]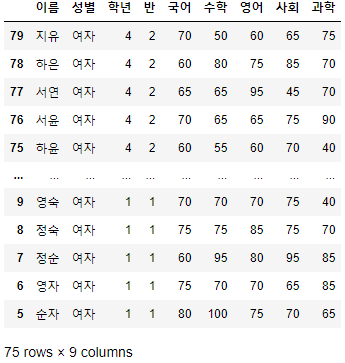
- step을 음수로 지정해주면, DataFrame의 순서를 깔끔히 뒤집어 조회하는 것을 볼 수 있다.
2.2.2. Step을 지정하지 않은 역순 조회
- step을 음수로 지정하고 조회하면 데이터가 반대로 뒤집혀서 조회되는 것을 보았다.
- step을 음수로 지정하지 않고 start나 end만 음수로 지정하면 데이터를 뒤집지 않은 본래의 상태에서 뒤에서부터 조회가 된다.
- start를 음수 m으로 지정하고 end를 지정하지 않으면 뒤에서부터 m개의 행을 반환한다.
>>> 시험점수[-4:]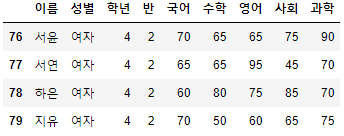
- start를 지정하지 않고 end를 음수 n으로 지정하면 뒤에서부터 n개의 행을 제외하고 반환한다.
>>> 시험점수[:-4]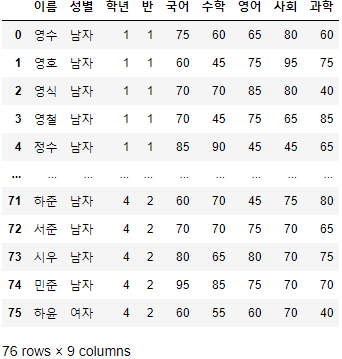
- start를 음수 m으로 end를 음수 n으로 입력 시 뒤에서부터 m:n의 행을 가지고 온다.
- 단, start의 음수 m이 end의 음수 n보다 커야 한다(그렇지 않다면, 행이 하나도 조회되지 않는다).
>>> 시험점수[-7:-4]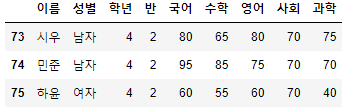
>>> 시험점수[-4:-4]
>>> 시험점수[-2:-4]
2.3. 슬라이싱과 인덱스
- 슬라이싱은 기본적으로 행의 순서를 기반으로 행을 조회하지만, 인덱스를 대상으로도 조회가 가능하긴 하다.
- 시험점수 DataFrame의 "이름"칼럼을 Index로 설정하고, "지원"부터 "민서"까지의 행을 조회해보자.
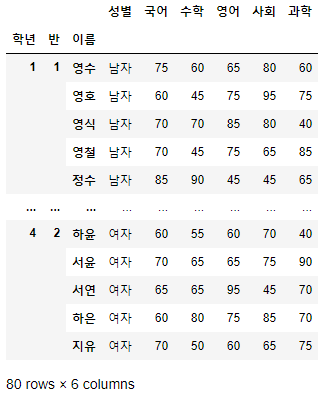
>>> 시험점수.set_index("이름", inplace=True)
>>> 시험점수["지원":"민서"]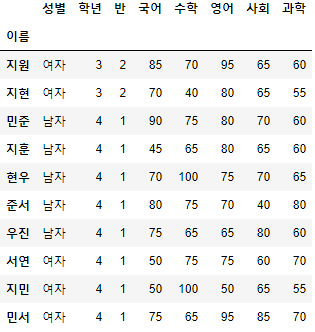
- 해당 기능은 앞서 다뤘던 Index의 범위를 이용한 조회와 유사하다.
>>> 시험점수.loc["지원":"민서"]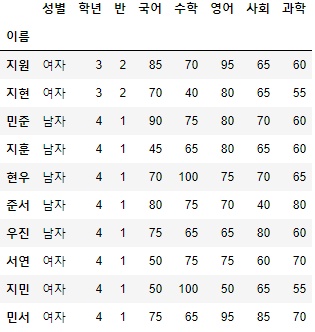
- 다만, 해당 방법은 중복이 있는 Index에 대해서 Slicing을 할 곳을 특정할 수 없으므로, 동작하지 않는다.
>>> 시험점수.loc["영호":"하윤"]
- 또, 인덱스를 다른 숫자로 정의한다면, 인덱스를 무시하고 순서로 슬라이싱을 한다.
# 30에서 110까지의 정수를 새로운 인덱스로 정의하였다.
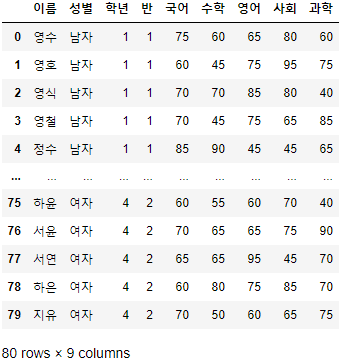
>>> 시험점수.reset_index(drop=False, inplace=True)
>>> 시험점수.index = range(30, 110)
>>> 시험점수
>>> 시험점수[30:40]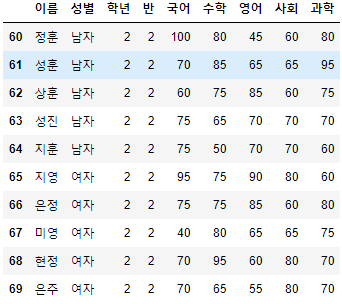
- 30에서 110으로 Index를 바꿨으므로, Index로 슬라이싱 되면 30에서 40까지의 Index로 출력되어야 하나, 30번째 행에서 40번째 행에 위치한 Index인 60~69가 출력되었다.
2.4. df.iloc[]를 이용한 조회
- 앞서 슬라이싱을 이용한 순서 기반 조회를 해보았다.
- 슬라이싱은 Pandas의 DataFrame, Series뿐만 아니라 list, numpy array 등 Python의 다양한 data type에서 지원하는 기능이지만, Pandas는 여기에 더해서 df.iloc[] 또는 Sr.iloc[] 함수를 통해 위치 기반 조회를 할 수 있다.
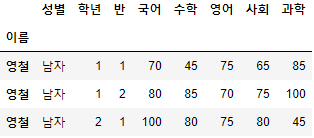
>>> 시험점수.reset_index(drop=True, inplace=True)
>>> 시험점수.loc[5]
이름 순자
성별 여자
학년 1
반 1
국어 80
수학 100
영어 75
사회 70
과학 65
Name: 5, dtype: object>>> 시험점수.loc[5:10]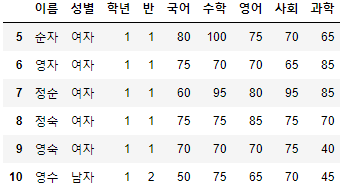
- iloc는 기본적으로 슬라이싱과 기능이 매우 유사하므로, 슬라이싱에서 다뤘던 기능들이 대부분 동일하게 실행된다.
- 단, iloc는 인덱스 기반 조회는 불가능하다.
>>> 시험점수.set_index("이름", inplace = True)
>>> 시험점수.iloc["지원":"민서"]
이번 포스트에서는 위치를 기반으로 필요한 행을 조회하는 슬라이싱과 iloc함수를 알아보았다. 다음 포스트에서는 특정 조건을 기반으로 행을 조회하는 Boolean 기반 행 조회 방법에 대해 알아보도록 하자.
'Python > Pandas' 카테고리의 다른 글
| Pandas-데이터 프레임, 데이터 조회하기-3. Boolean으로 조회하기. (3) | 2021.12.10 |
|---|---|
| Pandas-데이터 프레임, 데이터 조회하기-1. Index로 조회하기 (2) | 2021.12.09 |
| Pandas-데이터 프레임 컬럼명 가지고 놀기 (2) | 2021.02.24 |
| Pandas-데이터 프레임 Index 가지고 놀기 (0) | 2021.02.18 |
| Pandas-데이터 프레임의 구조와 용어 정리 (2) | 2021.02.17 |