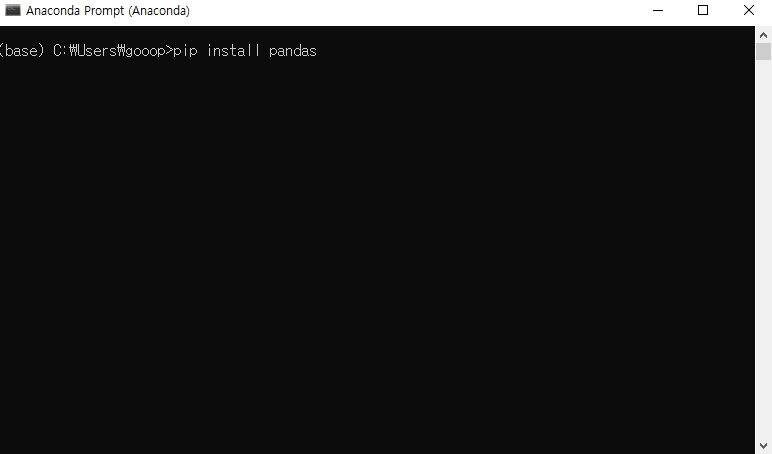
728x90
반응형

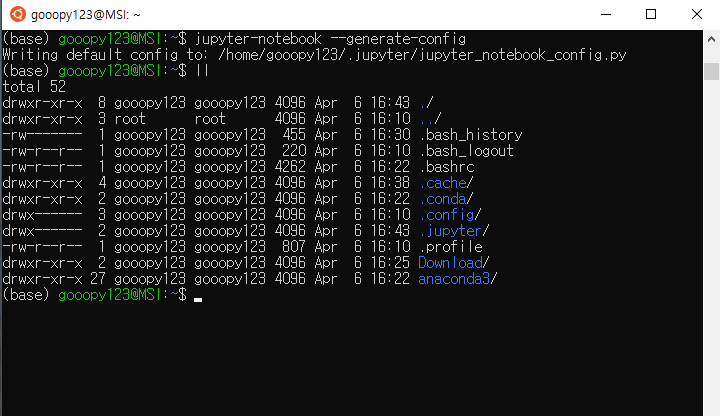
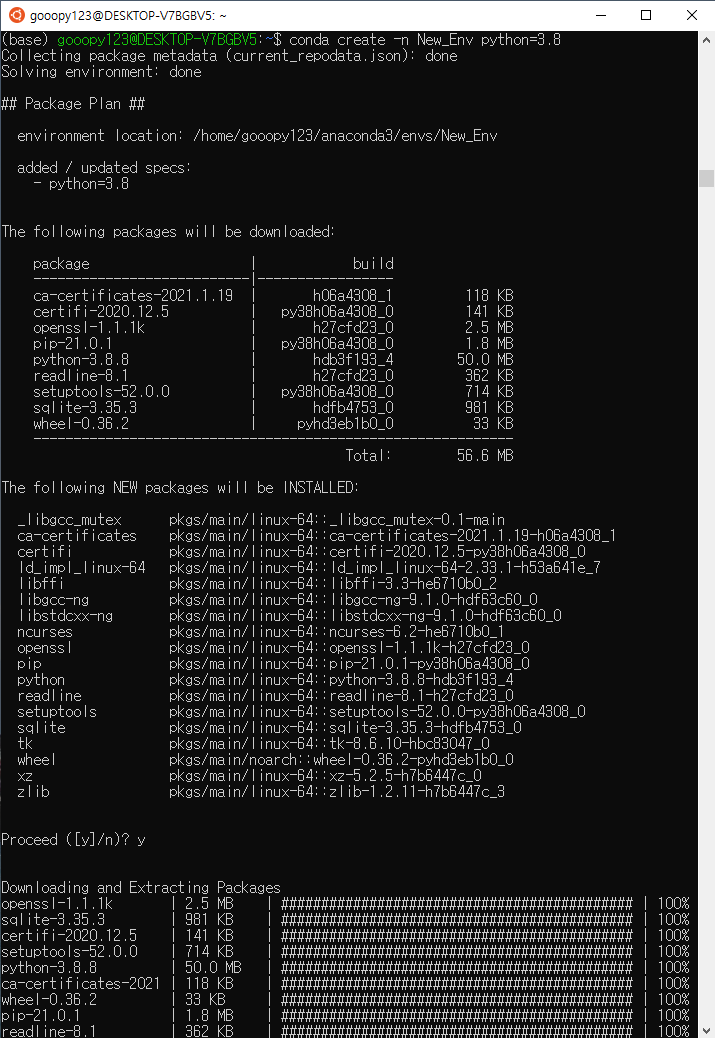
리눅스 서버에 CUDA 세팅하기
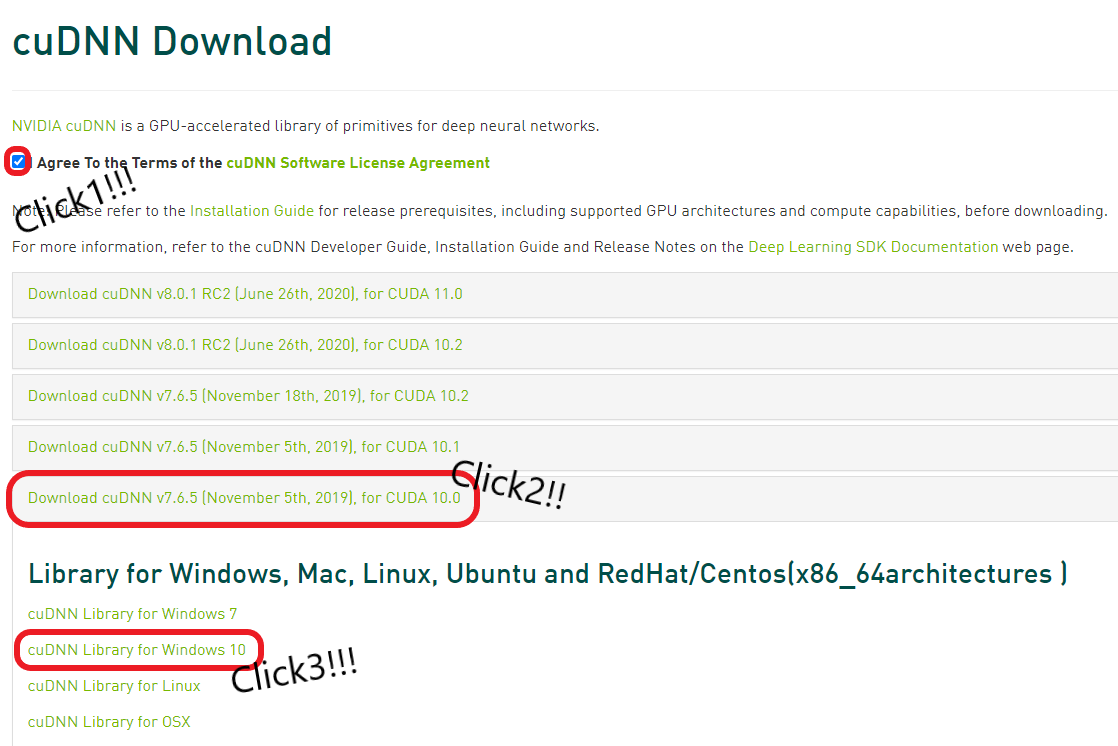
이전 포스트에서 CUDA 세팅에 필요한 CUDA와 cuDNN을 다운로드하였다. 이번 포스트에서는 CUDA를 설치해보도록 하겠다.
0. 다른 버전의 CUDA가 설치되어 있는지 확인하기
- 현재 CUDA를 세팅하는 환경은 wsl2를 이용하여 만들어진 가상 환경이기 때문에 엔비디아 드라이버가 설치되어 CUDA가 꼬일 문제가 없지만, 윈도우 PC나 사용하려는 텐서플로우 버전과 기존 서버에 세팅된 CUDA 버전이 다른 경우, 기존 NVIDIA 파일과 CUDA를 제거해줘야 한다.
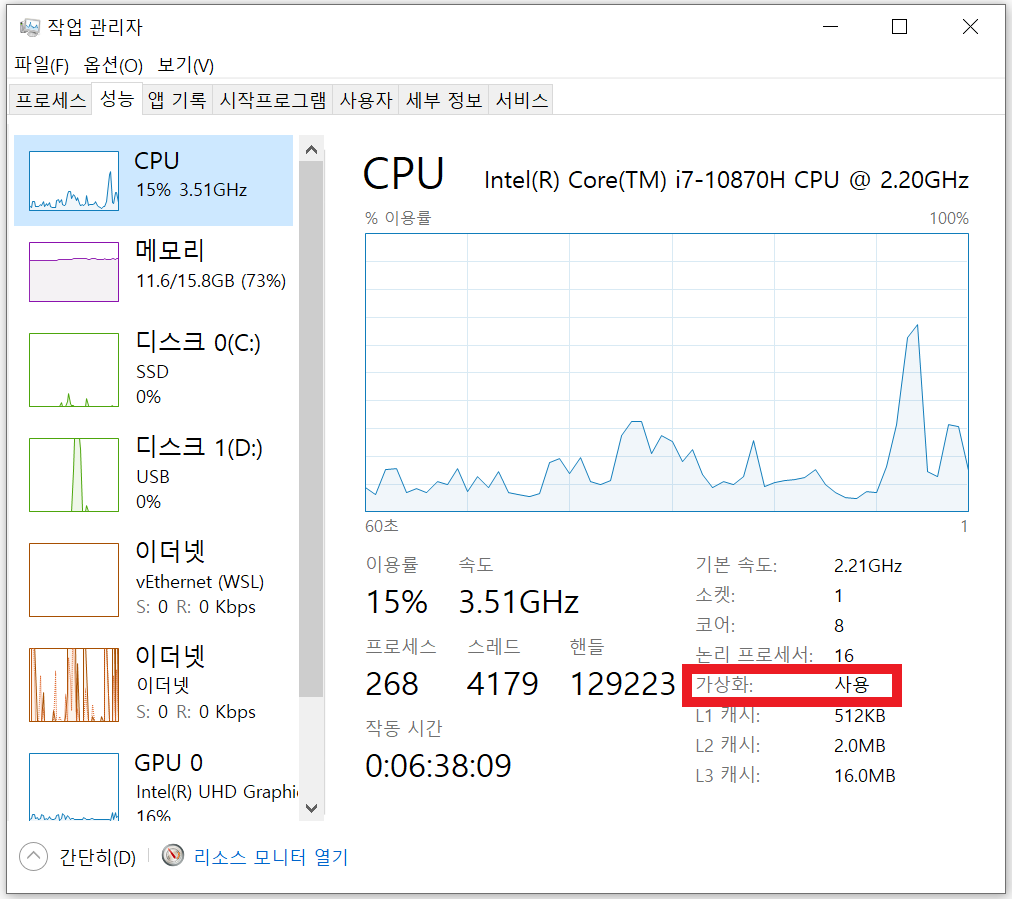
- 현재 환경에 엔비디아 드라이버가 설치되어 있다면, 다음과 같은 방법으로 그래픽 드라이버 정보를 얻을 수 있다.
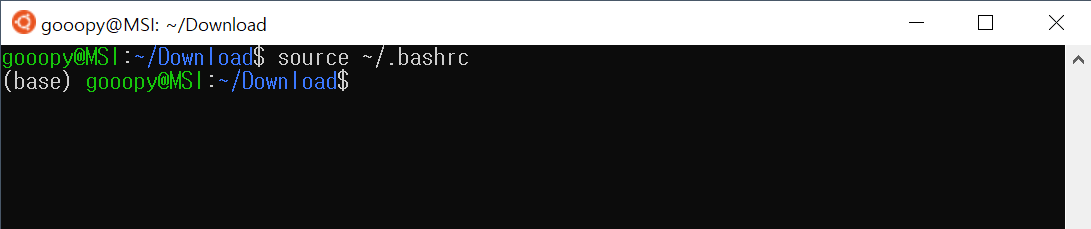
nvidia-smi
nvcc -V- CUDA가 설치되어 있다면, nvcc -V를 확인하면 된다.
- 경우에 따라 nvcc -V에서 출력되는 쿠다와 nvidia-smi에서 출력되는 CUDA Version이 다른 경우가 있는데, 이는 CUDA가 꼬여 있는 것일 수 있기 때문에 이후에 Tensorflow 사용 시, 충돌이 일어날 수 있다. 때문에 CUDA 파일과 nvidia 관련 파일을 완전히 제거하여, CUDA를 맞춰주는 것이 좋다.
- nvidia-smi 입력 시 출력되는 화면은 다음과 같다.
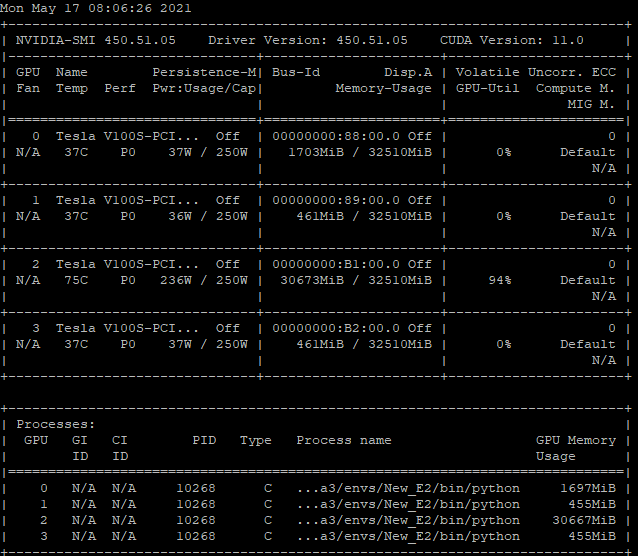
- nvcc -V 입력 시 출력되는 화면은 다음과 같다.
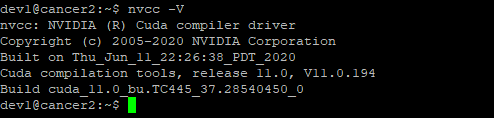
- 엔비디아 드라이버와 쿠다를 제거하는 방법은 다음과 같다.
# nvidia driver 삭제
sudo apt-get remove --purge '^nvidia-.*'
# CUDA 삭제
sudo apt-get --purge remove 'cuda*'
sudo apt-get autoremove --purge 'cuda*'
# CUDA 남은 파일 삭제
sudo rm -rf /usr/local/cuda
sudo rm -rf /usr/local/cuda-10.1- 엔비디아 드라이버와 쿠다 제거 후, 성공적으로 제거되었는지 확인하기 위해, nvidia-smi, nvcc -V와 같은 코드를 입력하여, 제대로 제거되었는지 확인하자.
- 그러나, CUDA가 여러 개 깔려 있거나, 여러 개의 GPU 서버의 GPU가 연결 되어 있는 경우, 위 방법대로 제거하더라도, nvidia-smi나 nvcc -V가 다시 출력될 수 있다.
1. CUDA 설치하기
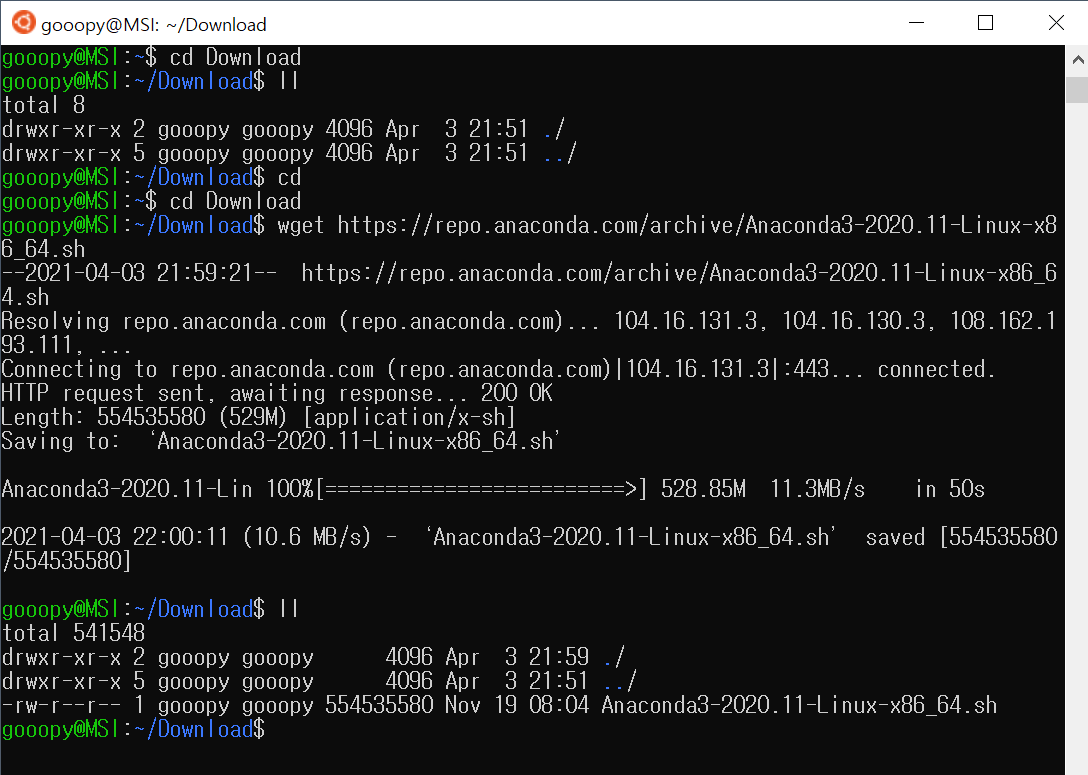
- 이전 포스트에서 다운로드하였던 CUDA 파일을 실행하기 전에 권한을 부여하도록 하자.
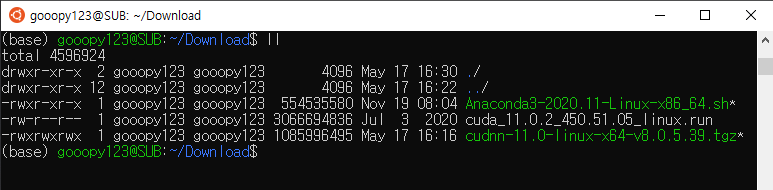
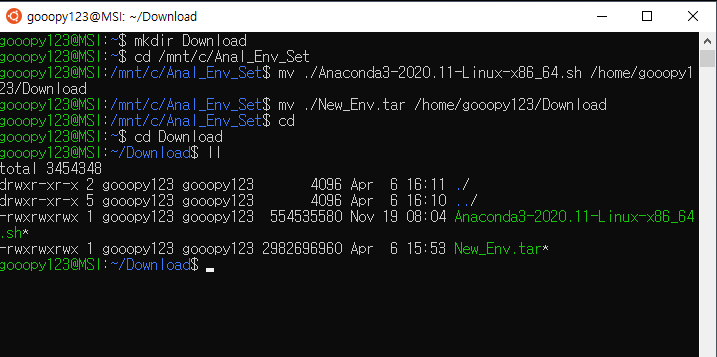
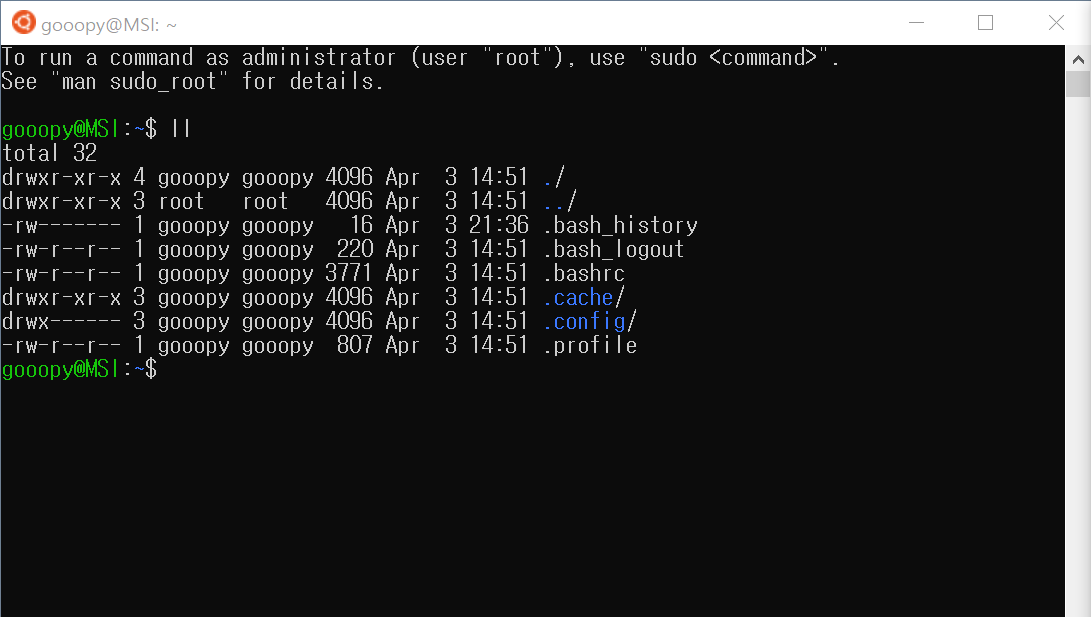
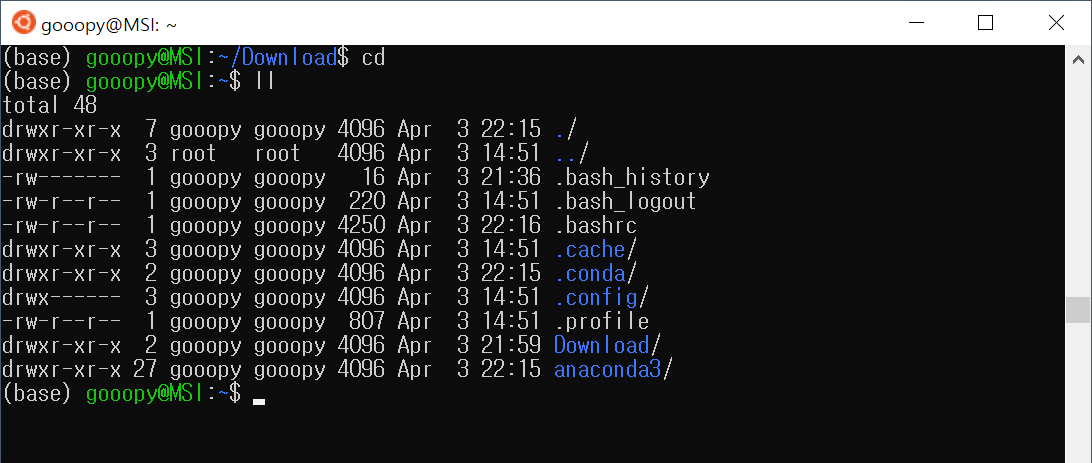
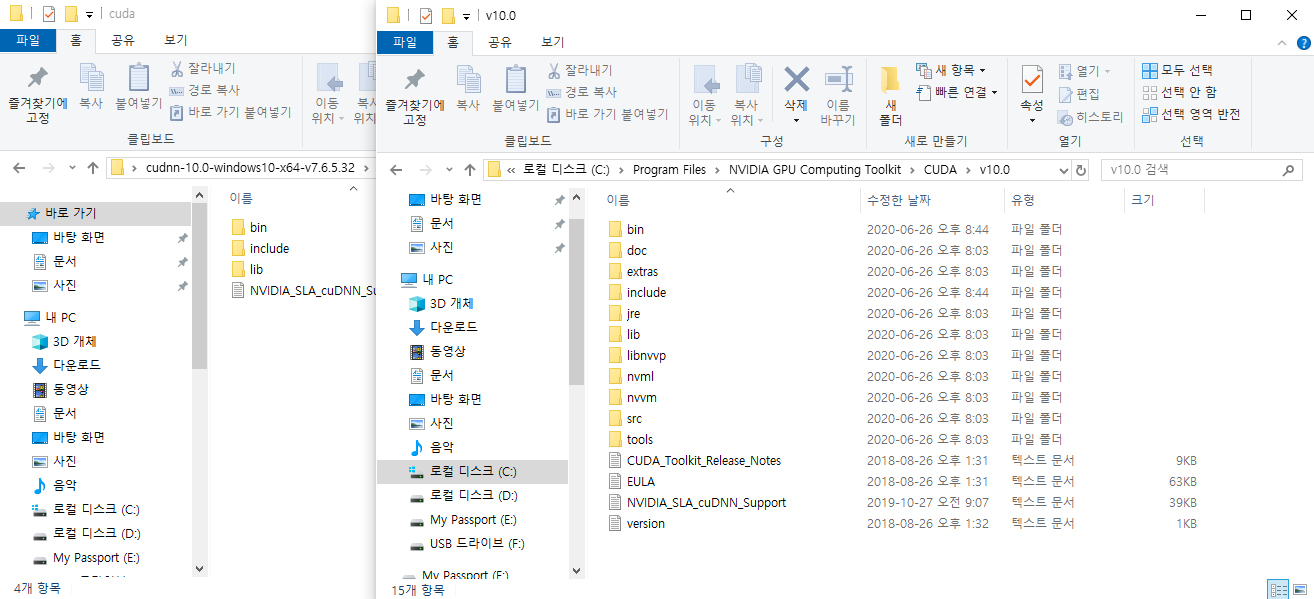
- 이전 포스트까지 Download 디렉터리에 받았던 파일들은 다음과 같다.
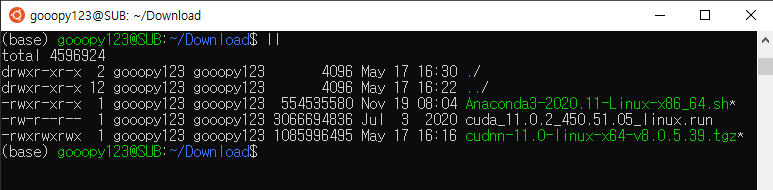
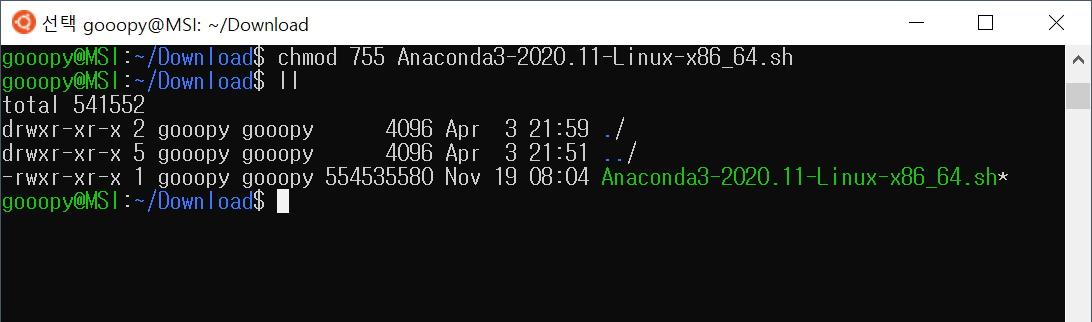
- 위 사진에서 cuda_11.0.2_450.51.05_linux.run에 chmod를 사용하여, 777 권한을 부여하자.
chmod 777 cuda_11.0.2_450.51.05_linux.run
ll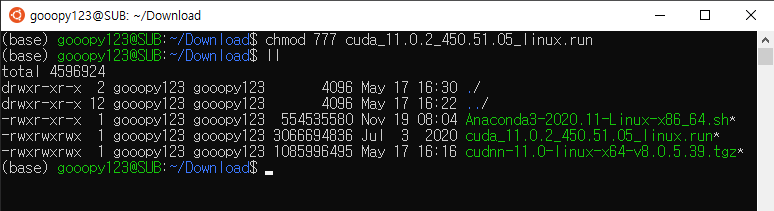
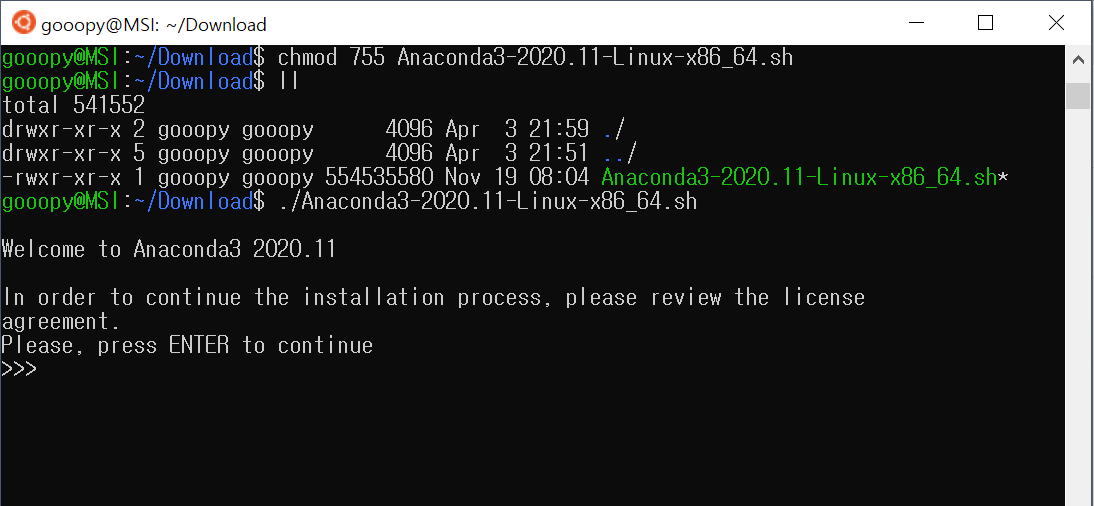
- 이제 cuda_11.0.2_450.51.05_linux.run을 실행하여 CUDA를 설치하도록 하자.
./cuda_11.0.2_450.51.05_linux.run
gcc 에러 발생
- CUDA 설치 시, 다음과 같은 에러가 뜰 수도 있다.
- Failed to verify gcc version. See log at /tmp/cuda-installer.log for details.
- 관련 로그를 확인하기 위해 위 에러가 말해준 위치로 이동해보자.
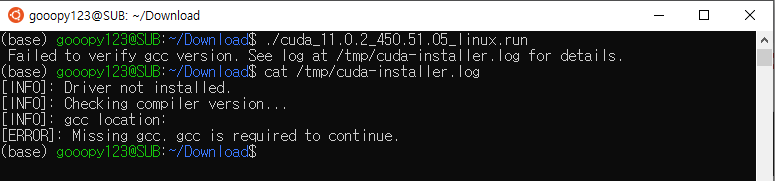
- 위 내용을 보니, gcc 가 없어서 발생한 문제임을 알 수 있다.
- gcc를 설치하여, 위 문제를 해결해줘야 한다.
- 위 문제가 뜬 경우 apt를 비롯한 가장 기본적인 세팅도 안되어 있는 것이므로, 가능한 위와 같은 상황에선 인터넷을 열어달라 하여, 위와 같은 기본적인 세팅은 해놓는 것을 추천한다.
- 위 문제의 해결 방안은 다음과 같다.
sudo apt update
sudo apt install build-essential
sudo apt-get install manpages-dev- 위 코드는 sudo 권한이 반드시 필요하기 때문에 지금까지와 달리 꼭 sudo를 입력해주도록 하자.
- 기본적으로 gcc는 7.5.0으로 설치되므로, 버전도 업그레이드하도록 하자.
sudo apt -y install gcc-8 g++-8
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 8
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-8 8
CUDA 설치 재진행
- 다시 CUDA 설치를 진행하도록 하겠다.
./cuda_11.0.2_450.51.05_linux.run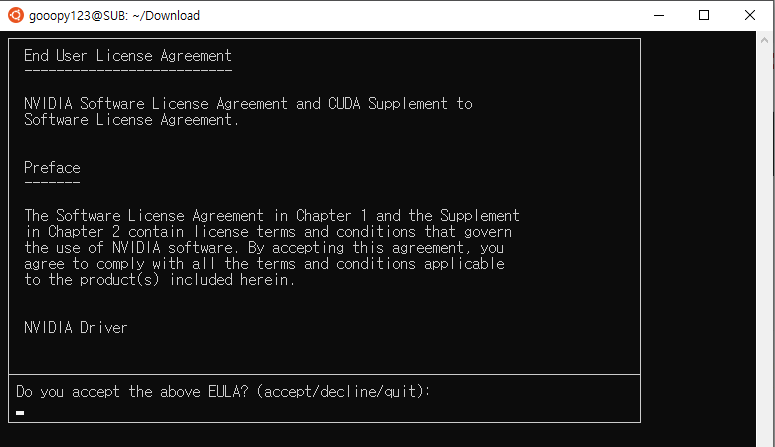
- accept를 입력하여 진행하자

- 위/아래 방향키로 이동, 왼쪽/오른쪽 방향키로 +가 있는 영역 세부 표시, 엔터 입력 시 X 체크 또는 해제를 실시할 수 있다.
- 지금 같이 CUDA, cuDNN 관련 사항이 완전히 없는 경우, 모두 체크하여 설치를 진행하도록 하자.
- Install을 눌러, 계속 진행해보자.
컴파일러 에러 발생
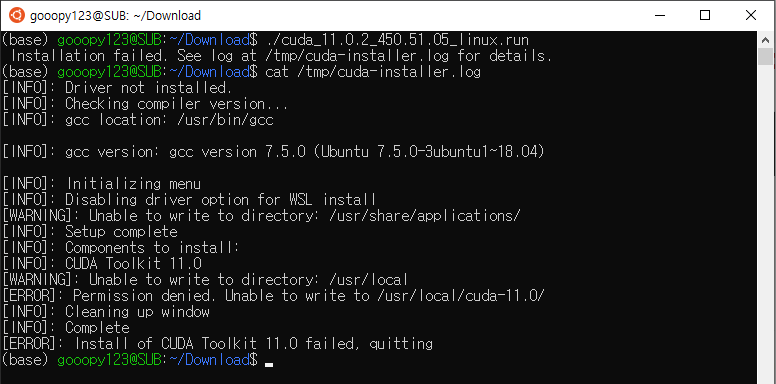
- 이번에는 컴파일러 버전이 맞지 않아, 컴파일러 에러가 발생하였다.
sudo apt-get install build-essential
경로 문제
- 위 명령어를 입력하여, 해당 오류 관련 패키지를 설치해주자.
- 이번에는 다음과 같은 에러가 등장하였다.
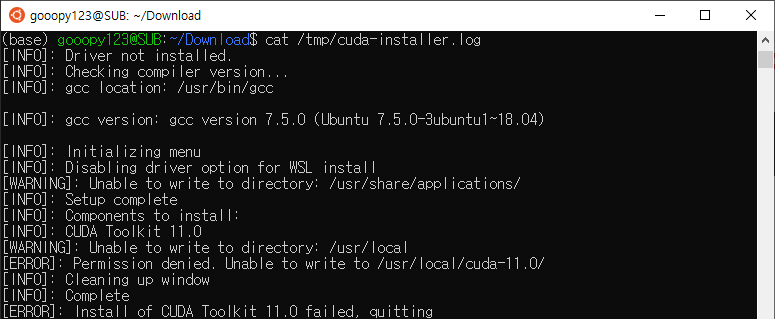
- 특정 디렉터리가 존재하지 않아 발생하는 에러로 보인다.
- sudo 권한을 주어 설치하도록 하자.
sudo ./cuda_11.0.2_450.51.05_linux.run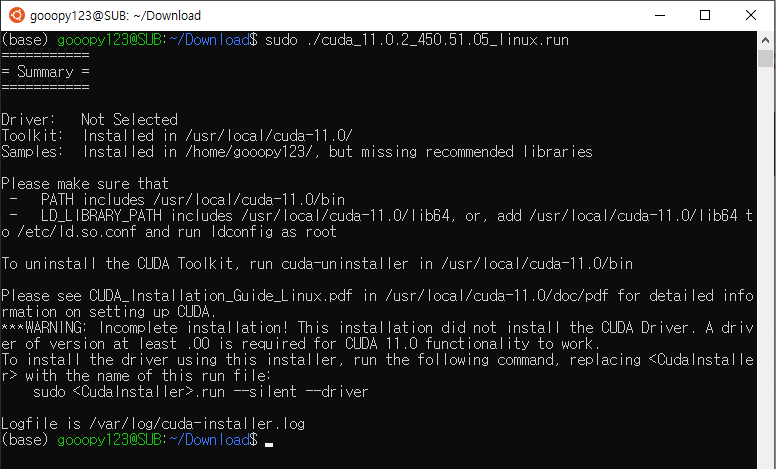
- 성공적으로 CUDA를 설치하였다.
- Toolkit과 Cuda Samples가 설치된 위치를 볼 수 있으며, 이제 cuda를 사용하기 위해 PATH 설정을 하도록 하자.
CUDA PATH 설정
- CUDA를 사용하기 위해선 전역 변수를 수정해줘야 한다.
- 만약 우분투 사용자마다 다른 CUDA를 사용하고자 하는 경우, 사용자의 home 디렉터리의 .bachrc를 수정하면 된다.
cd
sudo vim /etc/bash.bashrc- cd를 입력하여 최초 경로로 돌아가자.
- 위 명령어를 입력하여 출력된 화면의 맨 마지막에 위 CUDA 설치 후, 출력된 CUDA PATH를 다음과 같이 설정해주도록 하자.
export PATH=/usr/local/cuda-11.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.0/lib64:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.0/extras/CUPTI/lib64:$LD_LIBRARY_PATH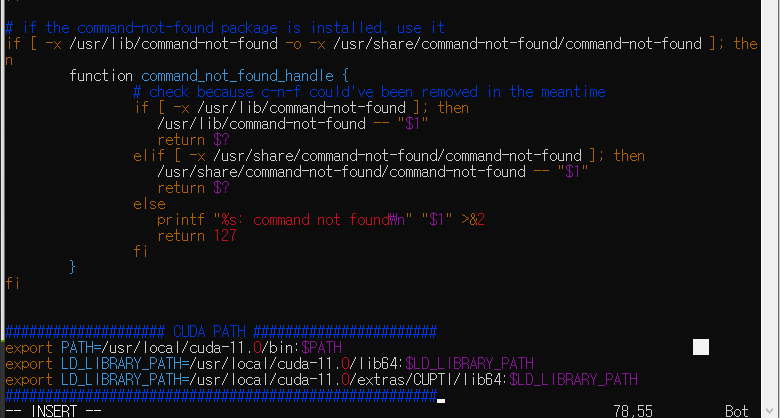
- 위 입력된 사항을 esc > :wq 를 입력하여 저장하도록 하자.
- PATH 지정 후, 위 사항을 터미널에 바로 적용해주도록 하자.
source /etc/bash.bashrc- nvcc -V를 입력하여 CUDA가 성공적으로 설치된 것을 확인하도록 하자.
nvcc -V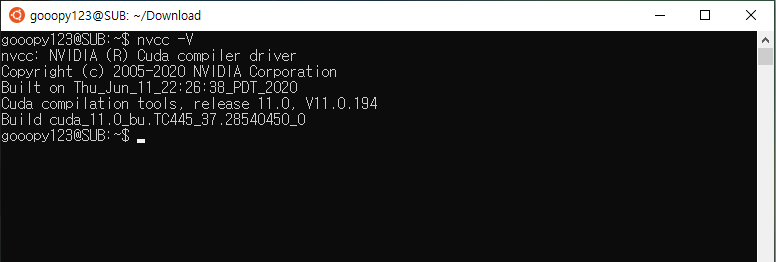
- 성공적으로 CUDA가 설정된 것을 볼 수 있다.
2. cuDNN 설치
- cuDNN 설치는 cuDNN 폴더의 압축해제 후, 그 안에 있는 파일들을 이전에 설치하였던 CUDA 파일의 안에 복사해서 옮겨줘야 한다.
- 그러므로, 이전에 cuda를 설치하였던 경로를 먼저 보도록 하자.
whereis cuda
- Download 디렉터리로 돌아가 이전에 다운로드하였던 cuDNN 파일의 압축을 풀도록 하자.
cd Download
ll
tar -xvf cudnn-11.0-linux-x64-v8.0.5.39.tgz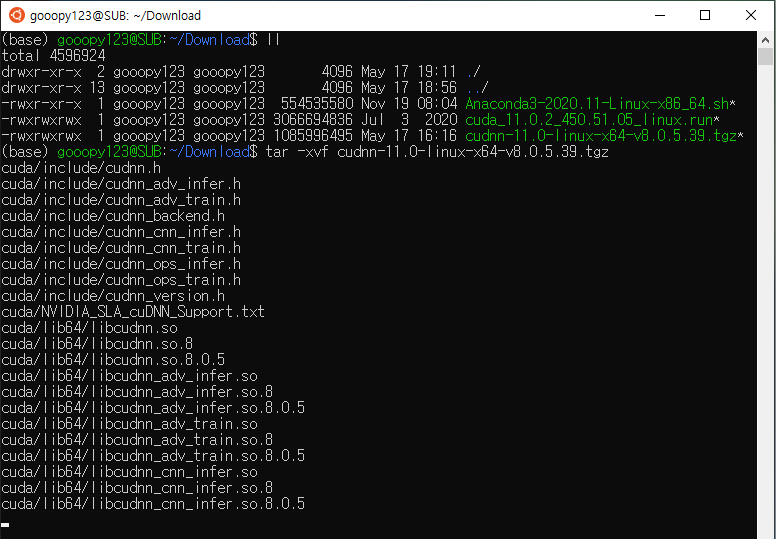
- 압축 해제 후, 생성된 파일을 확인해보자
ll
cd cuda
ll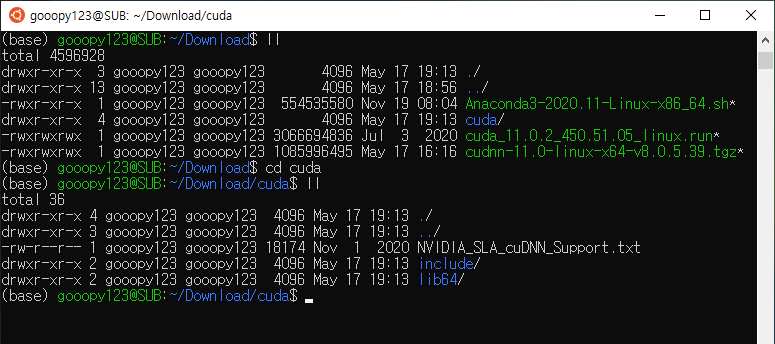
- cuda 디렉터리 안에 있는 include, lib64 폴더의 하위 파일들을 이전에 설치하였던 cuda의 include와 lib64 폴더로 복사하면 된다.
- 이전에 확인했던 cuda의 경로로 include의 하위 파일들 lib64 하위 파일들을 각각 해당하는 디렉터리로 이동시키자
sudo cp include/cudnn* /usr/local/cuda-11.0/include
sudo cp lib64/libcudnn* /usr/local/cuda-11.0/lib64/
sudo chmod a+r /usr/local/cuda-11.0/lib64/libcudnn*- cuDNN 설치가 제대로 되었는지 확인해보자
cat /usr/local/cuda-11.0/include/cudnn_version.h | grep CUDNN_MAJOR -A 2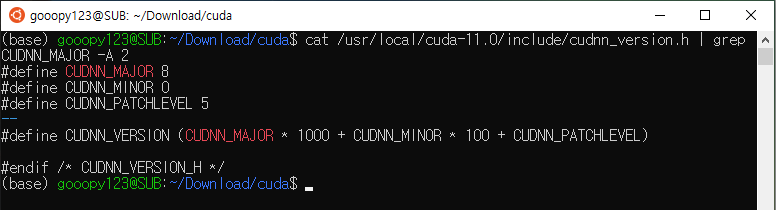
- 위 내용을 보면 cudnn 8.0.5가 성공적으로 설치된 것을 볼 수 있다.
728x90
반응형
'Python > 설치 및 환경설정' 카테고리의 다른 글
| Python 리눅스 서버에 분석 환경 구축4 - CUDA 세팅(1) (0) | 2021.05.17 |
|---|---|
| Python 리눅스 서버에 분석 환경 구축3 - 가상환경 활성화와 주피터 노트북 (0) | 2021.04.06 |
| Python 리눅스 서버에 분석 환경 구축2 - 가상환경 만들고 내보내기 (0) | 2021.04.05 |
| Python 리눅스 서버에 분석 환경 구축1 - 가상머신과 아나콘다 설치 (0) | 2021.04.03 |
| Python 텐서플로우(Tensorflow)와 tensorflow-gpu 설치(Windows) (2) | 2020.06.28 |