
얼마만의 포스팅인지... 가장 최근에 한 포스팅이 2021년 05월 17일이니, 반년 조금 넘는 기간 동안 포스팅을 안 했다.
나름의 변명이라면 올해 4월에 새로운 직장에 가고, 프로젝트를 하나 둘 맡아서 하다 보니 정신이 없기도 했고, 프로젝트를 어느 정도 마무리 짓고 여유가 나자 그놈의 디아블로 2가 나와버리는 바람에 시간이 슉 지나가버렸다.
너무도 감사하고, 죄송스럽게도 많은 분들께서 찾아와 주셔서, 미약한 실력이나마 도움이 될 수 있기를 바라며 다시 한번 포스팅을 해보고자 한다. 과연, 포스팅하고자 했던 것들을 전부 올리고, 새로운 영역을 파헤쳐 갈 수 있을까?
데이터 프레임, 데이터 조회하기
Python을 사용하는 데이터 분석가에게 가장 기초가 되는 Pandas를 다룬 것이 올해 초인 2021.02.24일이었으니, 다음에 뭘 다루려 했었는지 가물가물하다. 앞서 DataFrame의 Index와 Column명을 가지고 노는 법에 대해 알아봤으니, 이번 포스팅에서는 Index와 Column명을 이용해서 내가 원하는 데이터만 가지고 오는 법에 대해 알아보도록 하겠다.
데이터 프레임의 가장 큰 장점은 누구든지 이해하기 쉬운 형태로 데이터를 볼 수 있다는 것이지만, 데이터의 양이 많아질수록 한눈에 들어오지 않을 정도로 데이터가 거대해지기 때문에, 내게 필요한 데이터만 조회하는 법을 알아야 한다.
데이터 프레임의 조회 방식은 크게 index와 column 명으로 조회하는 방법, 데이터의 순서를 기반으로 조회하는 방법, Boolean으로 조회하는 방법이 있는데, 이를 찬찬히 알아보도록 하자.
내가 원하는 데이터를 가지고 오기
- 내가 원하는 데이터를 가지고 오는 방법은 크게 3 가지가 있다.
- 내가 원하는 행을 가지고 오기
- 내가 원하는 열을 가지고 오기
- 내가 원하는 행과 열을 가지고 오기
- 여기서 내가 원하는 행을 가지고 오는 방법이 비교적 복잡하며, 원하는 행을 가지고 온 후 내가 필요한 열을 설정해주면, 문제는 쉽게 해결된다.
- 그러므로, 행을 가지고 오는 방법을 위주로 다뤄보도록 하자.
- Pandas의 DataFrame에서 내가 원하는 행을 가지고 오는 방법도 크게 3가지가 있다.
- Index를 이용해서 가지고 오기(loc)
- 위치를 이용해서 가지고 오기(슬라이싱, iloc)
- 조건을 이용해서 가지고 오기(Boolean)
- 이번 포스트에서는 Index를 이용해 내가 원하는 데이터를 가지고 오는 방법에 대해 다뤄보도록 하자.
1. 예제 데이터 가지고 오기
※ 예제 데이터
해당 예제 데이터는 이름, 성별, 학년, 반, 국어, 수학, 영어, 사회, 과학 총 9개의 열(Column)과 80개의 행(Row)으로 구성된 csv파일이다. 당분간 이 데이터로 학습을 진행해보도록 하자.
- 다운로드 받은 위 예제 데이터("시험점수.csv")파일을 내 워킹 디렉토리(Working Directory)로 이동시키거나, 파일의 경로를 이용해서 불러와보도록 하자.
>>> import pandas as pd
>>> import numpy as np
>>> FILE_PATH = "시험점수.csv">>> 시험점수 = pd.read_csv(FILE_PATH, encoding="euckr")
>>> 시험점수
- R과 비교되는 파이썬의 가장 큰 장점은 한글 사용이 비교적 자유롭다는 것이다.
- 파이썬은 utf-8 기반으로 만들어져 있기 때문에 데이터뿐만 아니라 변수명을 한글로 써도 큰 문제가 없다.
- 혹시 모르는 에러가 발생할 위험이 있으므로, 그래도 영어를 사용하는 것을 추천한다!!
- 한글이 들어 있는 파일이라면 파일의 경로만을 이용해서 데이터를 가져오는 경우, 한글이 깨지는 경우가 있는데, 이는 대부분 Encoding 문제로, pd.read_csv() 함수의 encoding 파라미터를 "euckr"로 지정하면 거의 해결된다.
2. Index를 이용해서 데이터를 가지고 오기.
- 데이터 프레임에서 내가 원하는 행을 조회하는 가장 빠른 방법은 Index를 이용하는 것이다.
- Index는 유일하게 존재하는 고유한 값일 수도 있으나, 중복된 값일 수도 있다.
- Index를 이용한다면, 데이터 조회뿐만 아니라 데이터 병합(Merging)도 쉽게 할 수 있다.
- Index로 조회하는 방법은 다음과 같다.
- df.loc[index]: index에 해당하는 DataFrame의 행을 가지고 온다.
2.1. 하나의 index를 가지고 와보자.
- index 60번을 가지고 와보자.
>>> 시험점수.loc[60]
이름 민준
성별 남자
학년 4
반 1
국어 90
수학 75
영어 80
사회 70
과학 60
Name: 60, dtype: object
>>> type(시험점수.loc[60])
pandas.core.series.Series- 하나의 index를 조회하자, Series Type으로 해당 index 정보가 조회되는 것을 볼 수 있다.
- 이 시리즈에서 이름을 하나의 값으로 가지고 와보도록 하자.
>>> Index60_Sr = 시험점수.loc[60]
>>> Index60_Sr["이름"]
'민준'- 파이썬의 딕셔너리(Dictionary) 객체처럼 내가 원하는 변수명을 key로 주니, 내가 원하는 값이 반환되는 것을 볼 수 있다.
2.2. 여러 개의 index를 가지고 와보자.
- 이번에는 여러 개의 index를 한 번에 가지고 와보도록 하자.
- 15, 20, 30, 45번의 Row를 가지고 와보도록 하겠다.
- 여러개의 index를 한번에 조회는 내가 원하는 index들이 들어있는 list를 만들어 loc에 넣으면 된다.
>>> 시험점수.loc[[15,20,30,45]]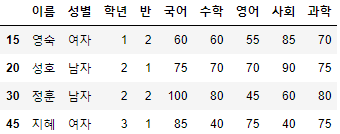
- 이전과 다르게 이번에는 index에 해당하는 데이터 프레임으로 결과가 조회되는 것을 볼 수 있다.
- 위 방법을 응용하면 Index A부터 Index B까지 조회도 가능하다.
>>> index_range = range(15,20)
>>> 시험점수.loc[index_range]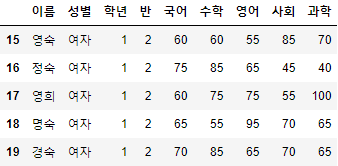
>>> 시험점수.loc[15:20]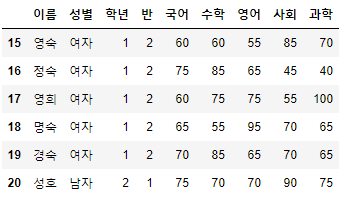
- 다만 Index의 범위를 이용하여 탐색하는 방법은 위 방법보다 다음에 다룰 Slicing이 더 많이 사용되므로, 이런 것도 있구나~ 하고 넘어가도록 하자.
※ 주의 사항
- 일반적인 파이썬 슬라이싱 방식은 start:end 일 경우, start부터 end-1까지의 연속된 값을 반환하나, .loc[start:end]는 start 부터 end 까지의 연속된 index를 조회한다.
시험점수[15:20]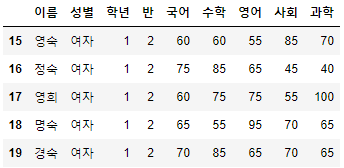
- 일반적인 슬라이싱 방식은 위 방식으로 하며, DataFrame.loc[Index]는 Index에 속해 있는 모든 index의 행을 가지고 온다.
2.3. index와 column으로 조회해보자.
- 해당 Index에서 특정 Column의 데이터만 보고 싶다면, index와 column을 동시에 넣어 조회하면 된다.
- 앞서 소개한 df.loc[index]를 아래와 같이 쓰면 된다.
- df.loc[index, column]
- 16번 index의 국어 점수를 조회해보자.
>>> 시험점수.loc[16, "국어"]
75- 해당 방법을 통해 내가 필요한 값을 하나의 원소로 출력하였다.
- 이번에는 index 16의 이름, 학년, 반, 국어 점수를 동시에 출력해보도록 하자.
>>> 시험점수.loc[16, ["이름", "학년", "반", "국어"]]
이름 정숙
학년 1
반 2
국어 75
Name: 16, dtype: object- 내가 필요한 index들을 list에 담아 조회하였듯, 조회하고자 하는 column들을 list에 넣어 조회하면 해결된다.
- 이번엔 index를 16, 20, 25로 column을 이름, 학년, 반, 국어로 조회해보자.
>>> 시험점수.loc[[16, 20, 25], ["이름", "학년", "반", "국어"]]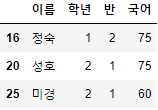
2.4. 값을 Index에 넣어 조회해보자.
- 앞서 다뤘던 방법들은 내가 원하는 Index를 알고 있다는 전제하에 유용하지만, 대부분 Index는 자동으로 설정되는 0~n 사이의 값이므로 이를 활용하는 것은 쉽지 않다.
- 이럴 땐, 특정 열을 Index로 만들어 조회하는 것으로 이 문제를 해결할 수 있다.
- "이름" column을 Index로 만들어보자.
- df.set_index(column, drop=True, inplace=False): column을 df의 index로 설정한다.
>>> 시험점수.set_index("이름", inplace=True)
>>> 시험점수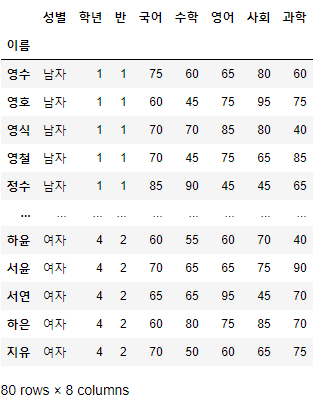
- inplace = True로 설정하면, df.set_index의 대상인 df에 바로 이를 적용할 수 있다.
- default인 inplace를 False로 하면 df.set_index의 결과만 출력한다.
- drop=False로 설정하면, 기존 index를 제거하지 않고 데이터 프레임의 열로 추가한다.
- index를 "영철"로 조회해보자.
>>> 시험점수.loc["영철"]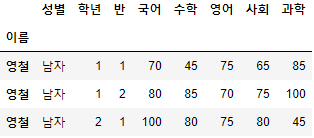
- DataFrame의 Index는 고유한 값이 아니어도 설정 가능하므로, 위와 같이 "이름"이 "영철"에 해당하는 Row를 모두 가지고 오는 것을 볼 수 있다.
- Index를 초기 상태로 돌려보자.
>>> 시험점수.reset_index(drop=False, inplace=True)
>>> 시험점수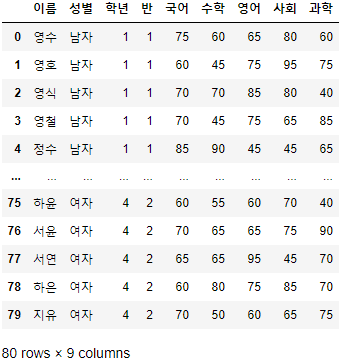
- 이번에는 학년이 1학년인 사람들만 조회해보도록 하자.
>>> 시험점수.set_index("학년", inplace=True)
>>> 시험점수.loc[1]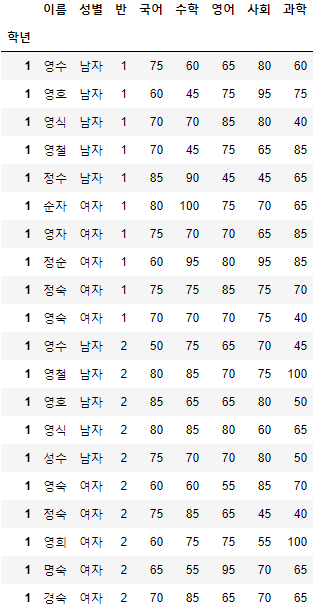
2.5. 다중 값을 Index로 조회해보자.
- 지금까지 하나의 열만 Index로 넣어 조회를 해보았다.
- 그렇다면, 여러 개의 열을 Index에 넣어 내가 원하는 행만 조회할 수는 없을까?
- 이때는 크게 2가지 방법이 있다.
- Multi Index를 만들어 조회하기
- 조회를 위한 열을 만들기
- 먼저 Multi index를 만드는 법부터 알아보도록 하자.
- Index를 다시 초기화하고 학년과 반으로 Multi index를 만들어보도록 하겠다.
>>> 시험점수.reset_index(drop=False, inplace=True)
>>> 시험점수.set_index(["학년", "반"], inplace=True)
>>> 시험점수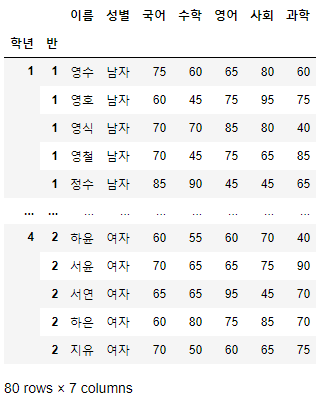
- 2학년 1반 사람들을 조회해보도록 하자.
- Multi Index는 Python의 Tuple로 생성되므로, Tuple로 조회하면 된다.
>>> 시험점수.loc[(2,1)]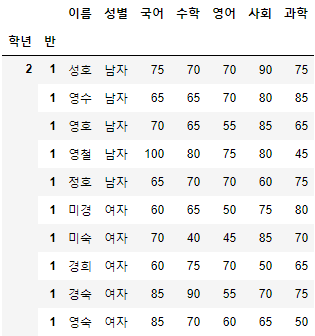
- 3개 이상의 열을 Multi Index로 만들어 조회도 가능하다.
- 이번에는 학년, 반, 이름으로 Multi Index를 만들어보자.
>>> 시험점수.reset_index(drop=False, inplace=True)
>>> 시험점수.set_index(["학년", "반", "이름"], inplace=True)
>>> 시험점수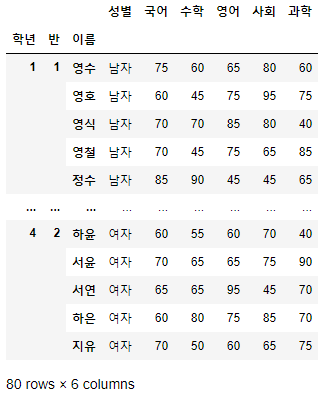
- 이번에는 2학년 1반의 영철을 조회해보도록 하자.
>>> 시험점수.loc[(2,1,"영철")]
성별 남자
국어 100
수학 80
영어 75
사회 80
과학 45
Name: (2, 1, 영철), dtype: object- 위와 같은 방법을 통해 내가 원하는 Column을 Index로 만들어 조회해보았다.
- 다만, 해당 방법의 한계점은 특정한 하나의 값만 조회가 가능하므로, 수학 점수와 같은 연속형 데이터의 범위에 대해서는 조회가 불가능하다는 단점이 있다.
- 물론, 이용해 우회하여 해결할 수 있기는 하다.
2.6. 새로운 열을 만들어 조회하기
- 지금까지는 기존에 존재하는 열을 그대로 Index로 만들어 조회를 하였다.
- 이번에는 내가 필요로 하는 값에 대한 변수를 만들고, 이 변수를 Index로 만들어 조회를 해보도록 하겠다.
- 수학 점수가 70점 이상인 사람들을 표시하는 새로운 변수를 만들어보자.
- 조건을 이용한 새로운 변수 만들기는 추후 자세히 다룰 테니 이번엔 단순 참고용으로 보도록 하자.
>>> 시험점수["수학_mask"] = np.where(시험점수["수학"] >=70, "수학_70점_이상", "수학_70점_미만")
>>> 시험점수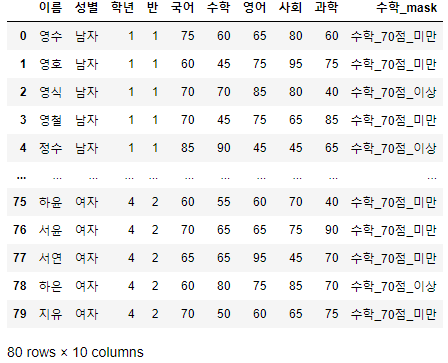
- 70점 이상은 "70점_이상", 70점 미만은 "70점_미만"인 수학_mask"라는 변수를 생성하였다.
- 새로 만든 "수학_mask"변수를 이용해서 70점 이상인 사람들만 출력해보도록 하자.
>>> 시험점수.set_index("수학_mask", inplace=True)
>>> 시험점수.loc["수학_70점_이상"]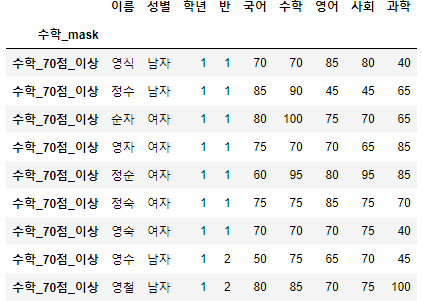
- 이미지가 너무 커서 일부만 표시해보았다. 길이가 48인 결과가 나왔다면, 제대로 나온 것이다.
>>> len(시험점수.loc["수학_70점_이상"])
48- 이번엔 영어 점수가 70점 이상인 사람을 추가해보자.
>>> 시험점수.reset_index(drop=False, inplace=True)
>>> 시험점수["영어_mask"] = np.where(시험점수["영어"] >=70, "영어_70점_이상", "영어_70점_미만")
>>> 시험점수
- 이번엔 수학 점수가 70점 이상이면서, 영어 점수도 70점 이상인 사람을 출력해보자.
- Multi Indexing을 사용할 수도 있으나, 이번에는 수학_mask와 영어_mask를 하나로 합쳐서 Index를 만들어보겠다.
>>> 시험점수["key"] = 시험점수["수학_mask"] + "&"+ 시험점수["영어_mask"]
>>> 시험점수.set_index("key", inplace=True)
>>> 시험점수.loc["수학_70점_이상&영어_70점_이상"]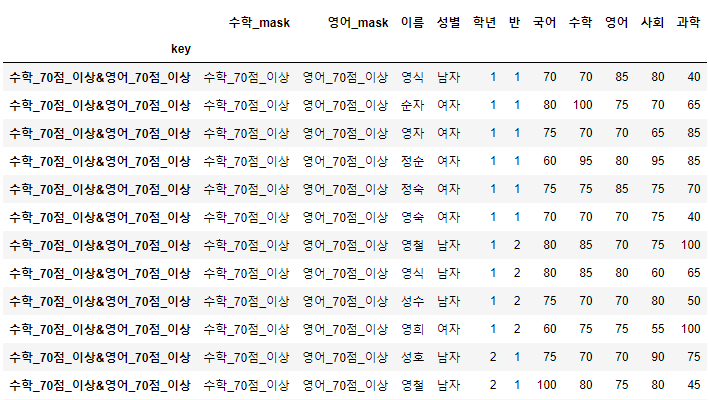
- 이미지가 너무 커서 일부만 표현하였으며, 길이가 35가 나오면 정상이다.
>>> len(시험점수.loc["수학_70점_이상&영어_70점_이상"])
35- 위와 같은 새로운 변수를 만들어 Index로 바꾸는 방법은 이해를 돕기 위해 변수를 지저분하게 만들었지만, 이보다 깔끔하게 할 수 있는 방법을 다음에 포스팅해보도록 하겠다.
지금까지 Index를 이용한 데이터 프레임 행 조회 방법에 대해 알아보았다. 다음 포스트에서는 위치를 이용한 행 조회에 대해 알아보도록 하겠다.
'Python > Pandas' 카테고리의 다른 글
| Pandas-데이터 프레임, 데이터 조회하기-3. Boolean으로 조회하기. (3) | 2021.12.10 |
|---|---|
| Pandas-데이터 프레임, 데이터 조회하기-2. 위치와 슬라이싱 (0) | 2021.12.10 |
| Pandas-데이터 프레임 컬럼명 가지고 놀기 (2) | 2021.02.24 |
| Pandas-데이터 프레임 Index 가지고 놀기 (0) | 2021.02.18 |
| Pandas-데이터 프레임의 구조와 용어 정리 (2) | 2021.02.17 |