728x90
반응형
데이터 분석을 위해선 먼저 분석을 할 수 있는 환경을 만들어야 하고, 그다음엔 분석을 할 데이터를 가지고 와야 한다. 이번 포스트에선 R에서 데이터를 가지고 오는 방법에 대해 학습해보도록 하겠다.
데이터 가져오기(Data Import)
- R은 일반적으로 csv 파일, R 전용 데이터 파일인 RData(확장자: .rda 또는 .rdata), 엑셀 파일 등으로 데이터를 입출력한다.
- 이외에도 DB, Json, SPSS 파일 등 다양한 형태로 데이터 입출력 관리를 한다.
- 이번 포스트에서는 csv, RData, SPSS, 엑셀 파일로 데이터를 관리하는 방법에 대해 학습해보도록 하겠다.
- DB를 통해 데이터를 관리하는 것은 추후 RMySQL 코드를 다루면서 짚고 넘어가도록 하겠다.
디렉터리(Directory) 확인하기.
- 디렉터리란, 다른 말로 폴더(Folder), 카탈로그(Catalog)라고도 하는데, 디렉터리라는 이 말보다 디렉터리를 부르는 다른 용어인 폴더라는 단어가 더 이해하기 쉬울 수 있다.
- 디렉터리는 상위 디렉토리(부모 디렉토리)와 하위 디렉토리(자녀 디렉토리)로 구성된 트리 형태의 구조를 가지고 있다.
- R에서 당신이 확인할 디렉터리는 바로 워킹 디렉토리(Working Directory)이다.
- 워킹 디렉토리는 R에서 작업하는 파일들이 기본적으로 읽고 쓰이는 공간이다.
- 디렉토리 관련 기본 코드
- getwd()
: 현재 워킹 디렉터리를 확인한다. - setwd("폴더 주소")
: "폴더 주소"로 워킹 디렉토리를 잡아준다.
※ 만약 당신이 워킹 디렉터리의 주소를 폴더의 url 주소를 복사 붙여 넣기 한다면, 슬래쉬(/) 역 슬래쉬로(\) 잡혀서 들어가므로, 이를 바꿔주어야 한다.
- getwd()
setwd("D:/Rworkspace")
getwd()## [1] "D:/Rworkspace"
파일을 가지고 와보자.
- 파일 경로에 한글이 들어가 있는 경우, 오류가 발생할 수 있으므로, 경로와 대상 파일의 명칭을 반드시 영어로 바꿔주자.
- list.file()
: 워킹 디렉터리에 있는 파일 리스트를 가지고 온다.
(만약 괄호 안에 다른 경로를 넣는다고 하면, 그 경로에 있는 파일 리스트를 가지고 온다.) - 파일을 가지고 오는 방법은 다음과 같다.
(csv, excel, spss, txt, rdata 파일 모두 함수 안에서 파라미터로 불러오고자 하는 파일의 경로나, file.choose()로 파일을 클릭해서 가져올 수 있다. 아래 내용이 잘 이해가 안 될 수 있는데, 일단 넘기고 따라서 학습해보자)
- 워킹 디렉터리 내 파일을 가지고 오는 경우: "파일명.확장자"
- 가져오려는 파일의 위치가 가변적인 경우, "파일위치/파일명.확장자"로 불러오기
- file.choose()를 사용하여 파일을 선택하여 불러오기
- R은 기본적으로 제공하는 데이터셋이 있으며, 해당 목록은 data() 함수를 통해서 볼 수 있다.
csv 파일을 가지고 와보자.
- CSV(Comma-separated Values)는 말 그대로 쉼표(Comma)로 값들이 구분된 형태이다.
- csv 파일은 엑셀, SAS, SPSS, R, Python 등 데이터를 다루는 대부분의 프로그램에서 읽고 쓰기가 가능한 범용 데이터 파일이다.
- csv 형식은 다양한 프로그램에서 지원하고 엑셀 파일에 비해 용량이 매우 적기 때문에 데이터를 주고받는 경우 자주 사용된다.
- 단점으로는, csv파일은 쉼표로 구분자가 들어가 있으므로, 데이터 자체에 쉼표가 들어가 있는 경우, 데이터 취급이 곤란해진다(구분자를 탭 문자로 바꾼 TSV 등을 사용한다.)
- read.csv()
: csv 파일을 가지고 온다. - 주요 Parameter
: read.csv(file, header = FALSE, sep = ",", na.strings = "NA", stringsAsFactors = TRUE, fileEncoding = "", encoding = "unknown")
# 파일 이름 / 첫 행을 헤더로 처리하여, 컬럼의 이름으로 할지 여부 / 구분자 / 데이터에 결측 값이 있는 경우 대응시킬 값 지정 / 문자열을 펙터로 가지고 올지 여부 / 가지고 오는 파일의 인코딩 / 문자열을 표시할 때의 인코딩 - stringsAsFactors는 가능한 FALSE로 하여 가지고 오자(Default = TRUE)이다. 만약, 디폴트 값 그대로 가지고 온다면, 모든 문자형이 Factor로 들어오기 때문에, 텍스트 데이터를 조작하기가 꽤 어려워진다. 만약, 텍스트 데이터가 단순한 범주형 척도로써 존재한다면, TRUE로 가지고 와도 큰 문제가 없다.
- write.csv()
: csv 파일로 저장한다. - 주요 Parameter
: write.csv(data, file="", row.names=TRUE, encoding = "unknown")
# 파일로 저장할 데이터 / 데이터를 저장할 파일명(경로) / 행 이름을 csv 파일에 포함하여 저장할지 여부 / 파일을 어떤 인코딩으로 저장할지 - 먼저 list.files()를 실시하여, 워킹 디렉터리에 위치한 파일의 정확한 이름을 확인하자.
워킹 디렉터리에서 파일 이름으로 파일을 가지고 와보자.
- list.files()를 보고 직접 타이핑해서 가지고 오자.
# 워킹 디렉토리에 있는 파일을 리스트업 해보자.
list.files()##[1] "asdfsadf.html" "asdfsadf.Rmd" "exam_csv.csv" "exam_exl.xlsx" "exam_spss.sav" "kyrbs2016.sav"
##[7] "old_2011.csv" "sda.html" "sda.Rmd" "ypdata_new_w10.sav"- 위 파일들에서 exam_csv.csv라는 csv 파일을 가지고 와보자.
- 해당 csv 파일은 Office 365의 Excel을 이용해서 만든 파일이며, 파일의 구조는 아래 사진과 같다.
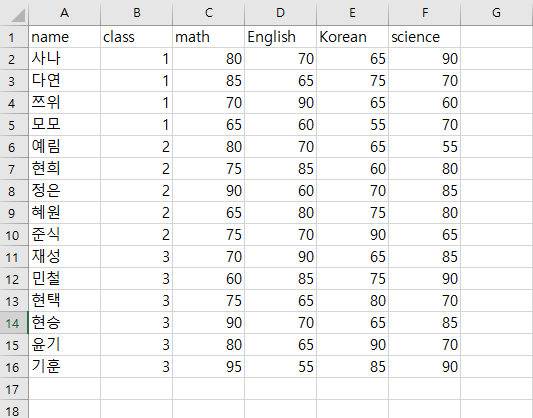
- 해당 파일을 불러와보자.
read.csv("exam_csv.csv", header = TRUE, sep = ",", na.strings = "NA", stringsAsFactors = TRUE)##Error in type.convert.default(data[[i]], as.is = as.is[i], dec = dec, : '<82><82><98>'에서 유효하지 않은 멀티바이트 문자열이 있습니다- 자 아주 간단한 파일이지만, 갑자기 "Error in type.convet.default(data[[i]], as.is = as.is[i], dec = dec, : '<ec><82><ac><eb><82><98>' 에서 유효하지 않은 멀티바이트 문자열이 있습니다."라며 오류가 뜬다!
- 위 오류가 발생한 이유는, office 365 엑셀의 인코딩 문제인데, 일반적으로는 fileEncoding과 encoding 파라미터를 손봐주면 된다.
- 한글에 관련된 인코딩은 크게 3개가 있다.
- utf-8
- CP949
- euc-kr
- 아래와 같이 인코딩 파라미터를 잡아줘서 해결해보자.
- 엑셀 파일을 저장할 때, CSV UTF-8(쉼표로 분리)(*.csv)로 해주었다.
read.csv("exam_csv.csv", header = TRUE, stringsAsFactors = TRUE, fileEncoding = "UTF-8", encoding = "CP949")## Error in read.table(file = file, header = header, sep = sep, quote = quote, : 입력에 가능한 라인들이 없습니다- 위와 같은 또 다른 에러가 뜨면서 읽어오질 못하였다.
- 위 문제 해결 방법은 아주 단순 무식하지만 확실한 방법과 약간 고급진 방법 2가지가 있다.
단순한 방법으로 해결해보자.
- 위 문제는 오피스 365 엑셀에서만 발생하는 문제인데, 오피스 365를 쓰지 않으면, 애초에 발생하지 않는다.
- csv는 ","가 구분자로 작용하여, 단어와 단어를 구분하는 형태이다.
- 그렇다면 엑셀에서 만든 csv 파일을 txt에서 가져와서 인코딩 형태를 바꿔서 저장해보자.
- 리눅스 환경이라면
- "file -bi 파일명"으로 파일의 인코딩을 확인하고
- "iconv -c -f 원래 인코딩 -t 바꿀 인코딩 파일명 > 새로운 파일명"으로 인코딩을 쉽게 바꿔줄 수 있다
- 윈도우 환경이라면 "마우스 오른쪽 클릭 > 연결 프로그램 > 메모장"을 사용하면, csv 파일을 메모장으로 열 수 있다.
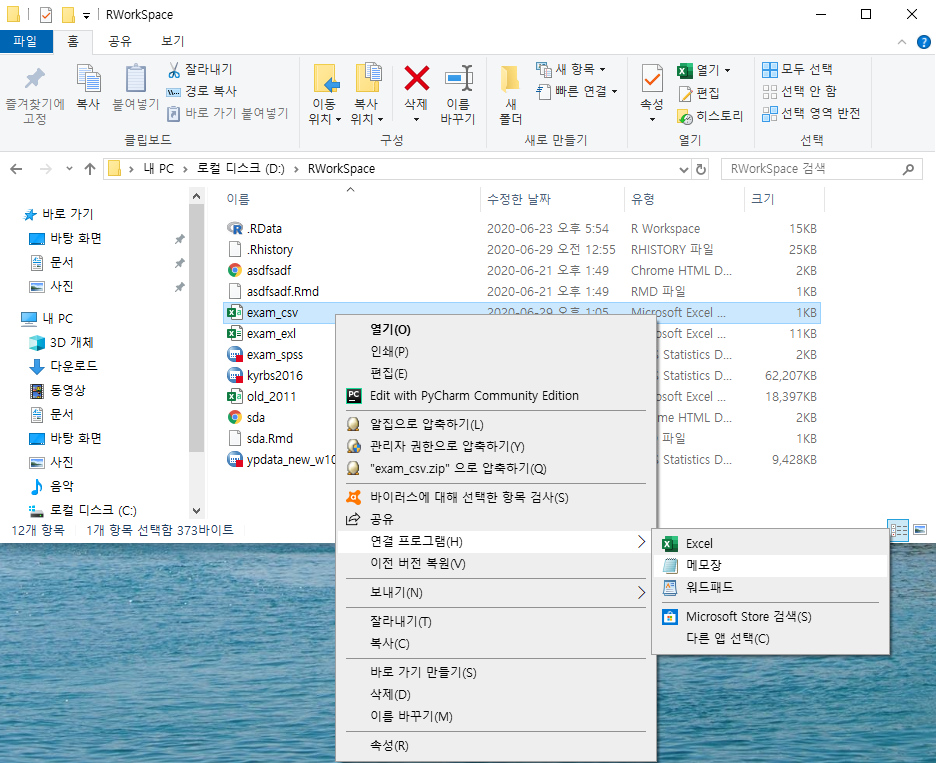
- "파일 > 다른 이름으로 저장"으로 들어가서 인코딩을 확인해보자!
- 보면 UTF-8(BOM)으로 돼있는데, 이 BOM이 문제다!
- 인코딩을 UTF-8 또는 ANSI로 바꿔보자
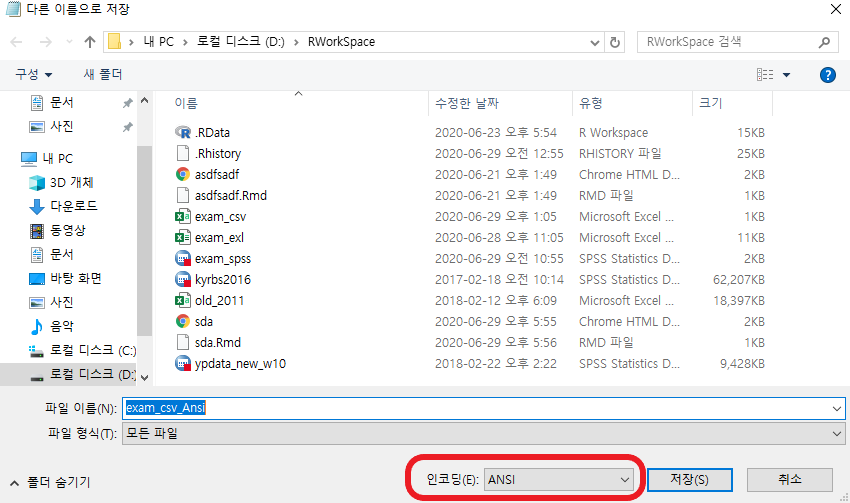
- 인코딩을 UTF-8로 한다면, fileEncoding 파라미터를 "UTF-8"로 바꾸면 된다.
- 인코딩을 ANSI로 한다면, 따로 파라미터를 잡아주지 않아도 된다(CP949나 euc-kr)로 잡아줘도 된다.
(인코딩에 대해서는 개념으로 추후 다시 한번 다루도록 하겠다.)
list.files()## [1] "asdfsadf.html" "asdfsadf.Rmd" "exam_csv.csv"
## [4] "exam_csv_ANSI.txt" "exam_csv_encoding.txt" "exam_exl.xlsx"
## [7] "exam_spss.sav" "kyrbs2016.sav" "old_2011.csv"
## [10] "sda.html" "sda.Rmd" "ypdata_new_w10.sav"read.csv("exam_csv_ANSI.txt", header = TRUE, stringsAsFactors = TRUE)## name class math English Korean science
## 1 사나 1 80 70 65 90
## 2 다연 1 85 65 75 70
## 3 쯔위 1 70 90 65 60
## 4 모모 1 65 60 55 70
## 5 예림 2 80 70 65 55
## 6 현희 2 75 85 60 80
## 7 정은 2 90 60 70 85
## 8 혜원 2 65 80 75 80
## 9 준식 2 75 70 90 65
## 10 재성 3 70 90 65 85
## 11 민철 3 60 85 75 90
## 12 현택 3 75 65 80 70
## 13 현승 3 90 70 65 85
## 14 윤기 3 80 65 90 70
## 15 기훈 3 95 55 85 90- 위 방법이 가장 간단하면서도 조금 무식한 해결책이라고 할 수 있다.
- 데이터도 정상적으로 잘 출력되었다.
조금 고급진 방법으로 해결해보자.
- 개인적으로는 위의 방법을 추천하지만, 경우에 따라서 좀 더 고급진 방법을 써야 할 수도 있을 것이다.
- 위 인코딩 문제는 간단하게 말해서 Windows에서 한글이 제대로 인식이 안되고, RStudio에서도 한글이 인식이 제대로 안돼서 발생하는 문제라고 할 수 있는데, R의 System 설정을 손대는 함수 중 언어를 손대는 함수인 Sys.locale()을 이용해서 이를 해결할 수 있다.
- Sys.setlocale()
: 로케일을 설정하는 함수로, 로케일은 사용자의 언어, 사용자 인터페이스의 언어를 정해주는 함수이다. - 주요 Parameter
: Sys,setlocale(category = "LC_ALL", locale = "")
Sys.setlocale("LC_ALL", "C") # 언어를 제거해버리자data = read.csv("exam_csv.csv", header = TRUE, stringsAsFactors = TRUE, encoding = "UTF-8")
data## X.U.FEFF.name class math English Korean science
## 1 <U+C0AC><U+B098> 1 80 70 65 90
## 2 <U+B2E4><U+C5F0> 1 85 65 75 70
## 3 <U+CBD4><U+C704> 1 70 90 65 60
## 4 <U+BAA8><U+BAA8> 1 65 60 55 70
## 5 <U+C608><U+B9BC> 2 80 70 65 55
## 6 <U+D604><U+D76C> 2 75 85 60 80
## 7 <U+C815><U+C740> 2 90 60 70 85
## 8 <U+D61C><U+C6D0> 2 65 80 75 80
## 9 <U+C900><U+C2DD> 2 75 70 90 65
## 10 <U+C7AC><U+C131> 3 70 90 65 85
## 11 <U+BBFC><U+CCA0> 3 60 85 75 90
## 12 <U+D604><U+D0DD> 3 75 65 80 70
## 13 <U+D604><U+C2B9> 3 90 70 65 85
## 14 <U+C724><U+AE30> 3 80 65 90 70
## 15 <U+AE30><U+D6C8> 3 95 55 85 90Sys.setlocale("LC_ALL", "Korean") # 언어를 한글로 바꾸자.## [1] "LC_COLLATE=Korean_Korea.949;LC_CTYPE=Korean_Korea.949;LC_MONETARY=Korean_Korea.949;LC_NUMERIC=C;LC_TIME=Korean_Korea.949"data## X.U.FEFF.name class math English Korean science
## 1 사나 1 80 70 65 90
## 2 다연 1 85 65 75 70
## 3 쯔위 1 70 90 65 60
## 4 모모 1 65 60 55 70
## 5 예림 2 80 70 65 55
## 6 현희 2 75 85 60 80
## 7 정은 2 90 60 70 85
## 8 혜원 2 65 80 75 80
## 9 준식 2 75 70 90 65
## 10 재성 3 70 90 65 85
## 11 민철 3 60 85 75 90
## 12 현택 3 75 65 80 70
## 13 현승 3 90 70 65 85
## 14 윤기 3 80 65 90 70
## 15 기훈 3 95 55 85 90- 위 방법을 통하면, RStudio에서 출력되는 언어를 제거하고, 다시 한글로 출력시켜서, 우리가 원하는 결과가 도출되게 할 수 있다.
- 개인적으로는 텍스트 파일로 열어서 인코딩을 바꾸는 방법이 쉬우니, 해당 방법을 추천한다.
- 해당 오류는 오피스 365 버전에서만 발생하는 것으로 확인하였다(다른 버전에서도 발생하는 것은 아직까진 보지 못했다...)
이번엔 CSV 파일 형태로 내보 내보자.
- write.csv()
: 데이터를 csv 형식으로 저장한다. - 주요 parameter
: write.csv(data, file = "파일 경로", quote = TRUE, row.names = TRUE, fileEncoding = "")
# 저장하고자 하는 데이터, 파일의 경로, 문자형 데이터에 ""따옴표를 넣는다, 행 이름을 넣는다, 저장하는 파일의 인코딩 - 위 parameter만 알아도 csv를 다루는데 큰 문제는 없으나, csv는 굉장히 자주 쓰게 될 파일 형식이므로, F1을 눌러서 자세한 설명을 보도록 하자.
data = data.frame(ID = c("A01", "A02", "A03", "A04", "A05"),
math = c(60, 80, 70, 90, 65))
write.csv(data, "test.csv", quote = TRUE, row.names = FALSE, fileEncoding = "CP949")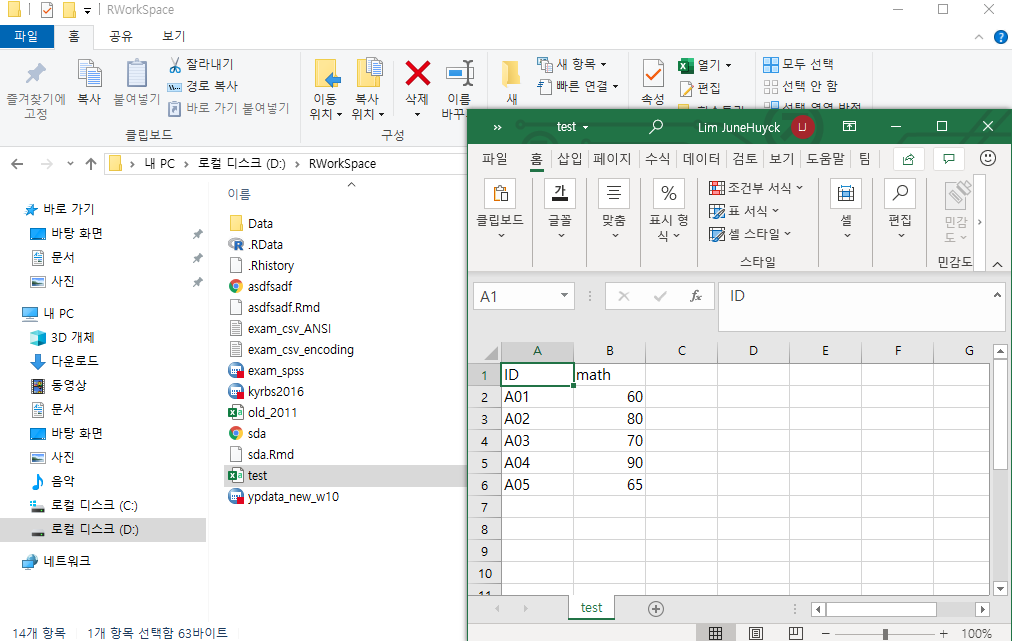
- 위 코드를 실행하면, 워크스페이스에 내가 원하는 data가 내보내진 것을 볼 수 있다.
이번 포스트에선 CSV 파일을 여는 방법과 인코딩 문제에 대해 학습해보았다. 인코딩 문제는 당신이 한국인이고, R을 다룬다면, 지겹게 마주할 수 있는 문제이며, 위의 방식에서 크게 벗어나질 않는다.
다음 포스트에선 엑셀 파일을 가지고 오는 방법과 파일 경로를 이용해서 파일 관리를 하는 법을 간략하게 다뤄보자.
728x90
반응형
'R > Basic' 카테고리의 다른 글
| R 데이터 가지고 오기(2부): 파일 경로 응용, 엑셀 파일 다루기 (0) | 2020.07.06 |
|---|---|
| R dplyr 패키지와 데이터 전처리 (0) | 2020.06.23 |
| R(기초) 패키지란? (0) | 2020.06.23 |
| R(기초) 데이터 타입 판별과 타입 변환 (0) | 2020.06.22 |
| R(기초) 리스트(List) (0) | 2020.06.22 |