728x90
반응형

이전 포스트에서 R의 기본 함수를 사용해 결측 값을 다뤄보았다. 이번에는 결측 값 문제를 해결하는데 특화된 패키지인 naniar, VIM 패키지를 사용해서 결측 값을 보다 체계적으로 다뤄보도록 하자.
외부 패키지를 이용해서 결측 값을 다뤄보자.
- R 기본 함수만으로도 결측 값을 파악하는데 큰 지장이 없긴 하지만, 결측 값을 위해 특화된 패키지들을 이용해서, 보다 단순하게 결측 값을 파악할 수도 있다.
- 사용할 패키지들을 설치하고, library 하여 분석 준비를 해보자.
- 학습에 사용할 데이터는 mlbench 패키지에 있는 BostonHousing 데이터와 moonBook 패키지의 acs 데이터다
- mlbench 패키지의 BostonHousing: 다양한 기계 학습 벤치마킹을 위한 데이터가 있는 패키지로, BostonHousing은 보스턴의 주택 가격에 대한 데이터다.
- moonBook 패키지의 acs: 의료 데이터가 주로 들어 있으며, acs는 환자의 데이터로, 요골동맥의 혈관 내 초음파 데이터인 radial 등이 있다.
# naniar 패키지 설치
>>> install.packages("naniar")
>>> install.packages("VIM")
# 학습용 데이터가 담긴 Packge
>>> install.packages("mlbench")
>>> install.packages("moonBook")
# 사용할 패키지 library
>>> library("naniar")
>>> library("VIM")
>>> library("moonBook")
>>> library("mlbench")
# 데이터 생성
>>> data("BostonHousing")
>>> data("acs")
# 원본 유지를 위해 사용할 변수에 Data를 담아놓음.
>>> Boston_df = BostonHousing
>>> acs_df = acs
1. naniar 패키지의 결측 값 기술 통계량
- naniar 패키지를 사용하면, 결측 값의 기술 통계량을 보다 편하게 구할 수 있다.
- 대상 데이터에 임의로 결측 값을 부여해보자.
# sample 함수를 사용하여 ptratio, rad 변수의 임의의 위치에 결측값을 생성하였다.
Boston_df[sample(1:nrow(Boston_df), 30, replace = FALSE), "ptratio"] <- NA
Boston_df[sample(1:nrow(Boston_df), 50, replace = FALSE), "rad"] <- NA- sample(x, size, replace = FALSE): 데이터의 전체 수만큼의 연속된 벡터(index와 동일한 벡터)에 원하는 크기만큼 sample을 랜덤 하게 추출했다. replace = FALSE로 두어 비 복원 추출을 실시했다.
# 0.대상 데이터 안에 결측값이 존재하는지 확인
>>> any_na(Boston_df)
[1] TRUE
>>> any_na(Boston_df$zn)
[1] FALSE
>>> any_na(Boston_df$ptratio)
[1] TRUE
# 1.대상 데이터의 결측값에 대한 Boolean값 반환
>>> are_na(Boston_df[1:30,"ptratio"])
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE
[14] FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
[27] FALSE FALSE FALSE FALSE
# 2.대상 데이터 안에 결측값의 갯수 반환
>>> n_miss(Boston_df)
[1] 80
>>> n_miss(Boston_df$ptratio)
[1] 30
# 3.대상 데이터 안에 결측값의 비율 반환
>>> prop_miss(Boston_df)
[1] 0.01129305
>>> prop_miss(Boston_df$ptratio)
[1] 0.05928854
# 4.대상 데이터에서 결측값이 아닌 값의 수
>>> n_complete(Boston_df)
[1] 7004
>>> n_complete(Boston_df$ptratio)
[1] 476
# 5. 데이터 프레임 내 결측값의 빈도표 출력
>>> miss_var_summary(Boston_df)
# A tibble: 14 x 3
variable n_miss pct_miss
<chr> <int> <dbl>
1 rad 50 9.88
2 ptratio 30 5.93
3 crim 0 0
4 zn 0 0
5 indus 0 0
6 chas 0 0
7 nox 0 0
8 rm 0 0
9 age 0 0
10 dis 0 0
11 tax 0 0
12 b 0 0
13 lstat 0 0
14 medv 0 0
# 6. 데이터 프레임 내 결측값의 누적 빈도 출력
>>> miss_var_cumsum(Boston_df)
# A tibble: 14 x 3
variable n_miss n_miss_cumsum
<chr> <int> <int>
1 crim 0 0
2 zn 0 0
3 indus 0 0
4 chas 0 0
5 nox 0 0
6 rm 0 0
7 age 0 0
8 dis 0 0
9 rad 50 50
10 tax 0 50
11 ptratio 30 80
12 b 0 80
13 lstat 0 80
14 medv 0 80- any_na(x): 데이터에 결측 값이 존재하는지 Boolean으로 출력
- are_na(x): 데이터 내 결측 값은 TRUE로 결측 값이 아닌 값은 FALSE로 출력
- prop_miss(x): 데이터 내 결측 값의 비율
- n_complete(x): 데이터 내 결측 값이 아닌 데이터의 수
- miss_var_summary(x): 데이터 프레임의 결측 값 빈도표 출력
- miss_var_sumsum(x): 데이터 프레임의 결측 값 누적 빈도 표 출력
2. 중복 결측 값 보기
- 각 변수 당, 결측 값의 양이 적다할지라도, 한 데이터 셋 안에 있는 결측 값의 양은 굉장히 많을 수 있다.
- 만약 한 모델 안에 m개(m≥2)의 변수가 들어가는 경우, 그 모델은 m개 변수의 결측 값을 모두 가정하지 않으면, 잘못된 결과를 도출할 위험이 있다.
- 때문에 원하는 변수에서 결측 값이 몇 개나 중복되는지를 알아야 한다.
- 결측 값의 중복량 파악은 Boolean을 이용하면 쉽게 할 수 있다.
# DataFrame 상태에서 apply, Boolean, sum의 성질을 이용
>>> table(apply(is.na.data.frame(Boston_df), MARGIN = 1, sum))
0 1 2
431 70 5
# Matrix로 변환하여 행의 합인 rowSums() 사용.
>>> table(rowSums(as.matrix(is.na.data.frame(Boston_df))))
0 1 2
431 70 5 - 위 방법을 통해 쉽게 중복된 결측 값의 수를 알 수 있고, 그로 인해 최대로 제거될 변수의 수를 알 수 있다.
- 그러나, 어떤 변수들에서 결측 값이 중복되는지를 파악하긴 어렵다.
- 때문에 결측 값 시각화를 통해, 변수별 결측 값의 분포를 볼 필요가 있다.
3. 간단한 결측값 시각화
- 데이터의 크기가 크고, 결측 값의 양이 많다면, 결측 값의 분포를 파악하기 힘들다.
- 시각화를 통해 결측 값 데이터가 어떻게 생겼는지 본다면, 어떠한 데이터들에 결측 값이 모여있는지를 보기 쉽고, 그로 인해 결측 값을 감안한 표본 축소나
- moonBook의 acs 데이터는 본래 결측 값이 존재하는 데이터이므로, 이 데이터를 사용하여, 결측 값 분포를 보도록 하자.
- naniar 패키지 설치 시, 함께 설치되는 패키지인 visdat에는 vis_miss()라는 결측 값 시각화 함수가 있다.
# 시각화
vis_miss(acs_df)
- vis_miss(x) 함수를 이용하면, 쉽게 데이터 안에 결측 값이 어떻게 분포해있는지 알 수 있다.
- 그러나, 결측 값이 있는 행이 흩어진 상태로 나오므로, 보기 조금 어려울 수 있다.
# 시각화
vis_miss(acs_df, cluster = TRUE)
- vis_miss(x, cluster = TRUE): cluster 파라미터를 TRUE로 잡으면, 공통된 결측 값이 있는 행들을 Cluster로 잡아주므로, 더 쉽게 데이터를 파악할 수 있다.
4. VIM 패키지를 사용한 결측 값 시각화
- vis_miss()는 코드가 매우 쉽지만, 기능이 많지 않다는 단점이 있다.
- 만약, 데이터의 결측 값을 보다 심도 깊게 보고자 한다면, VIM 패키지를 사용하면 된다.
- VIM은 Visualization and Imputation of Missing Values의 약자로, 말 그대로 결측 값의 시각화와 결측값 대체에 특화된 패키지라고 할 수 있다.
4.1. 중복된 결측 값의 분포
# VIM을 사용한 시각화
aggr(acs, col=c("white", "red"), prop=FALSE, number=TRUE, sortVars = TRUE,
cex.axis=.8, gap=1, ylab=c("Histogram of NA", "Pattern"))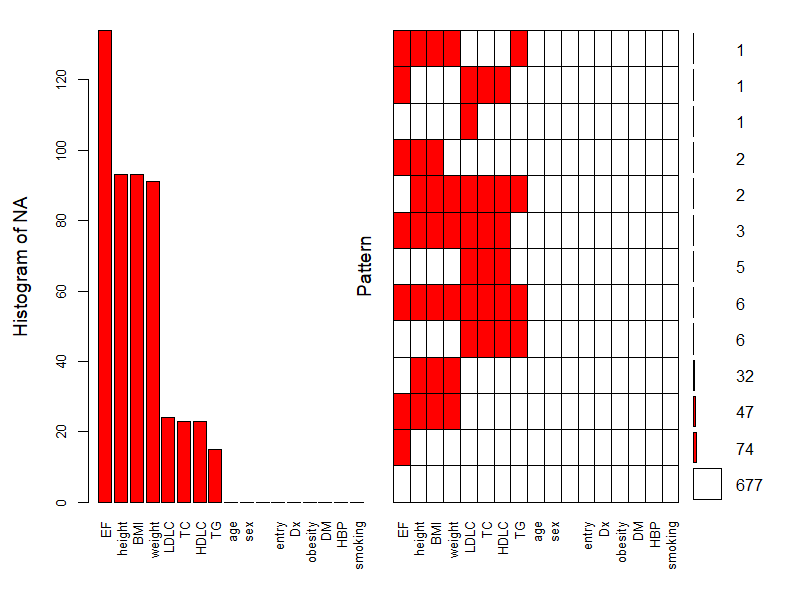
- 기능이 보다 많다 보니, 파라미터가 많은데, 그 내용은 다음과 같다.
- col = c("white", "red"): 결측 값이 없는 셀, 있는 셀의 색깔
- prop = FALSE: 비율로 출력할지(TRUE), 빈도로 출력할지(FALSE)
- number = TRUE: 결측 값의 개수를 숫자로 출력할지 여부
- sortVars = TRUE: 결측 값의 개수로 정렬함
- cex.axis = .8: 글자 크기
- gap = 1, 두 그래프의 간격
- ylab = c("title1", "title2"): 그래프의 이름
- 위 그래프에서 좌측 그래프는 단순한 히스토그램이니 설명은 생략하도록 하겠다.
- 우측 그래프는 공통된 결측 값의 빈도를 나타낸다. 예를 들어 EF, height, BMI, weight은 공통 결측 값을 47개 가지고 있다.
지금까지 외부 라이브러리를 사용하여, 결측 값을 보다 효과적으로 파악하는 방법을 알아보았다. 다음 포스트에서는 결측 값을 채워 넣는 방법인 Single Imputation에 대해 알아보도록 하겠다.
728x90
반응형
'분석에 필요한 배경 지식 > 결측값' 카테고리의 다른 글
| 결측값: 3.0. R-결측값 다루기 (0) | 2021.01.21 |
|---|---|
| 결측값: 2.1. 결측값 대체(2) - Multiple Imputation (0) | 2021.01.21 |
| 결측값: 2.0 결측값 대체(1) - Single imputation (4) | 2021.01.21 |
| 결측값: 1.1 기본개념(2) - 결측값의 종류 (0) | 2021.01.20 |
| 결측값: 1.0 기본개념(1) - 결측값이 미치는 영향 (0) | 2021.01.20 |


