요즘 일 때문에 많이 바빴더니 몇 일째 포스트 하지 못했다. 퇴근 후에 취미 생활을 즐기기 위해선, 운동을 하긴 해야겠다.
이전 포스트에선 csv 파일을 가지고 오는 방법과 인코딩 문제에 대해 다뤄보았다. R을 사용하기 까다롭게 만드는 문제 중 하나가 인코딩 문제이고, 반면에 파이썬은 UTF-8을 기반으로 작성했기 때문에, 위 문제에서 보다 자유로운 편이다.
R을 사용하다보면, 분석 환경 세팅 난이도는 그리 높지 않은 편인데(오프라인 환경이나 보안이 강한 환경에서도 큰 문제없이 설치가 가능하다), 데이터를 Import(가져올 때), Export(내보낼 때) 문제가 종종 발생한다. 이 문제는 대부분 인코딩 문제 거나, 데이터 자체에 R로 Import 될 때, 문제를 일으킬 수 있는 인자가 있기 때문이다.
(예를 들어 \n과 같은 문자는 줄을 바꾸는 문자인데, 이런 특수한 역할을 하는 문자가 섞인 데이터에선 데이터의 형태가 변형되어 버릴 수 있다. 이 문제는 R에만 국한된 것은 아니지만, 이 기회에 살짝 언급하고 가겠다.)
이번 포스트에선 R로 엑셀 파일을 가지고 오고 내보내는 방법에 대해 학습해보도록 하겠다.
엑셀 파일을 R에서 불러와보자.
- R에서 엑셀 파일을 불러오기 위해선 readxl 패키지를 사용해야한다.
- read_excel()
: 엑셀 파일을 읽어오는 함수 - 주요 parameter
: read_excel("파일위치/파일이름.확장자", range = "A1:B3": 엑셀 시트 내에서 내가 불러오고자 하는 영역, col_names = TRUE: 첫 행이 컬럼의 이름인지, sheet = 1, 불러올 시트)- read_excel의 특징은 자기가 원하는 sheet를 불러올 수 있다는 것이다.
- read_excel은 Excel의 특징인 시트 내 좌표를 이용해서 내가 원하는 구간만 데이터를 가져올 수 있다.
library("readxl")read_excel(file.choose(), col_names = TRUE, range = "A1:D6", sheet = 1)- file 이름(워크 스페이스가 기본 경로이며, 다른 경로를 쓰고 사용하고 싶은 경우엔 해당 경로를 추가하면 된다.)
이번 포스트에선 file.choose()를 넣어보았다.
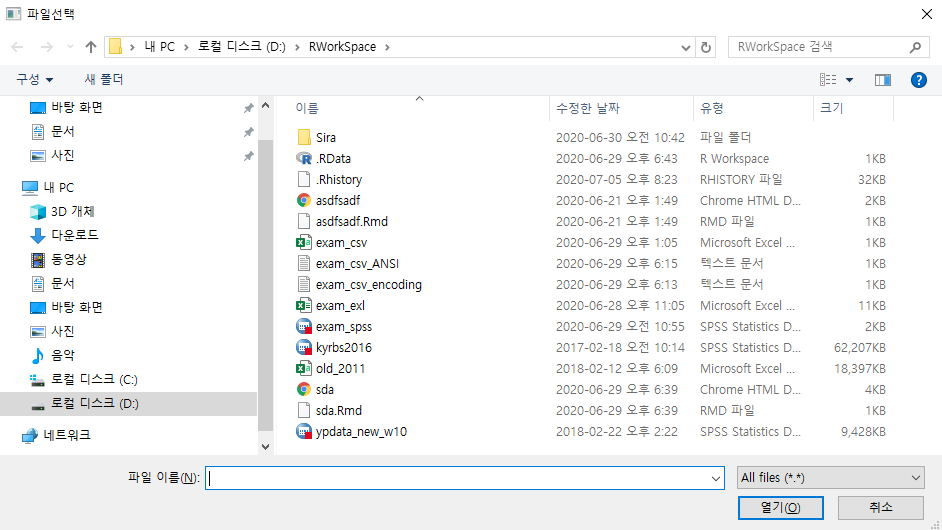
- file.choose()를 매개변수로 넣게 되면, 우리에게 익숙한 파일을 불러오는 창을 볼 수 있다.
- file.choose()는 R에 익숙할수록 딱히 필요 없는 기능이지만, 파일의 경로에 대해 익숙하지 않은 초보에겐 추천하는 기능이다.
(일단 파일을 불러와야 뭘 해볼 것 아닌가!)
## # A tibble: 5 x 4
## name class math English
## <chr> <dbl> <dbl> <dbl>
## 1 사나 1 80 70
## 2 다연 1 85 65
## 3 쯔위 1 70 90
## 4 모모 1 65 60
## 5 예림 2 80 70
겸사겸사 워크 스페이스 아래에서 경로를 가지고 장난을 쳐보자.
- 워크스페이스 경로는 D 드라이브의 RWorkSpace 파일이다.
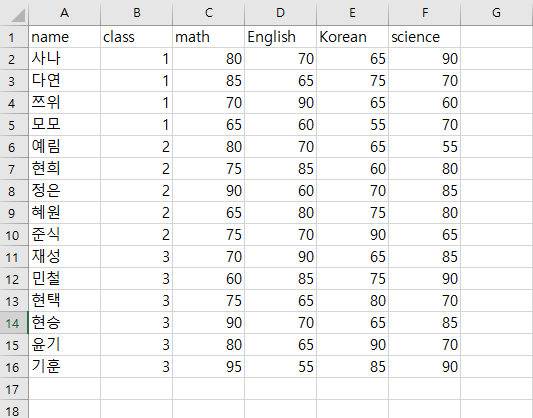
- 워크스페이스 경로에 손대지 말고, 해당 파일 안에 있는 Data 파일의 exam_exl.xlsx 파일을 불러와보자.
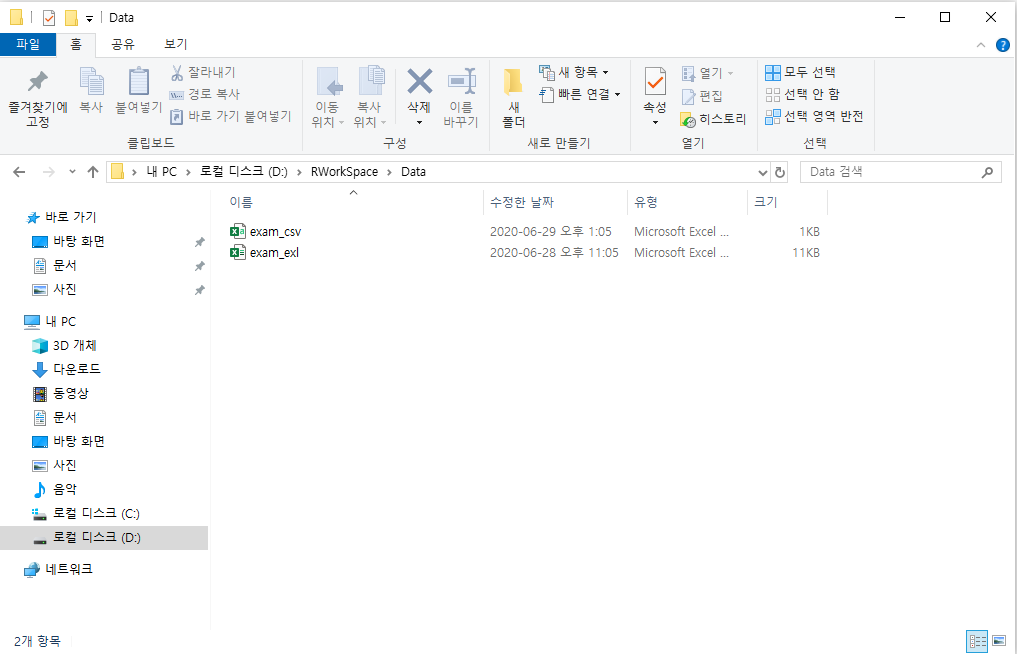
library("readxl")getwd()## [1] "D:/RWorkSpace"read_excel("./Data/exam_exl.xlsx", col_names = TRUE, sheet = 1)- ./Data 에서 .은 워크스페이스의 경로(정확히는 현 위치)를 의미한다.
## # A tibble: 15 x 6
## name class math English Korean science
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 사나 1 80 70 65 90
## 2 다연 1 85 65 75 70
## 3 쯔위 1 70 90 65 60
## 4 모모 1 65 60 55 70
## 5 예림 2 80 70 65 55
## 6 현희 2 75 85 60 80
## 7 정은 2 90 60 70 85
## 8 혜원 2 65 80 75 80
## 9 준식 2 75 70 90 65
## 10 재성 3 70 90 65 85
## 11 민철 3 60 85 75 90
## 12 현택 3 75 65 80 70
## 13 현승 3 90 70 65 85
## 14 윤기 3 80 65 90 70
## 15 기훈 3 95 55 85 90- 위 방식을 이용하면, 파일 관리를 보다 수월하게 할 수 있다.
엑셀 파일로 저장해보자.
- 엑셀로 파일을 불러왔으니, 이번엔 엑셀로 파일을 내보 내보자.
- 위에서 사용한 패키지인 readxl은 말 그대로 엑셀을 읽어오는 패키지이기 때문에, 엑셀로 파일을 내보내려면, writexl이라는 패키지를 설치해야 한다.
- 그러나 가능한 데이터는 엑셀 파일로 저장하지는 말도록 하자(데이터가 엑셀로 와서 어쩔 수 없는 상태에 엑셀을 R로 읽는 것이지, 데이터 관리를 엑셀로 하는 것은 좋지 않다. 이에 대한 내용은 후술 하도록 하겠다.)
- write_xlsx()
: 데이터를 엑셀 형태로 저장한다. - 주요 parameter
: write_xlsx(data, path = "경로/파일이름.xlsx")
library("writexl")data = data.frame(ID = c("A01", "A02", "A03", "A04", "A05"),
math = c(60, 80, 70, 90, 65))
write_xlsx(data, path = "./Data/test.xlsx")- 위 과정을 거치면 아래와 같이 엑셀 파일이 생성되는 것을 확인할 수 있다.
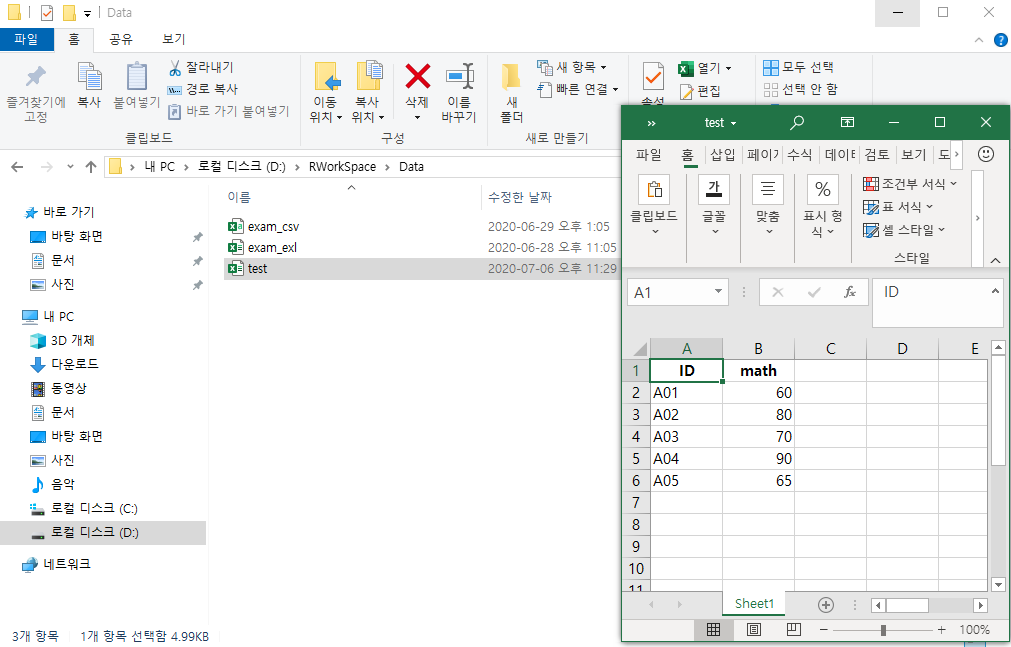
엑셀 파일로 데이터 관리를 하는 것은 좋을까?
이번 포스트에선 엑셀로 파일을 올리고 내리는 법을 알아보았다. 그런데 과연 엑셀로 파일을 관리할 일이 있을까? 엑셀은 데이터를 관리하는 데 있어서 상당히 많이 사용되지만, 동시에 단점도 많은 툴이기 때문에, 개인적으로 비추한다. 엑셀을 사용할 바에 csv 파일로 파일을 읽고 쓰는 것을 추천한다.
엑셀의 단점은 다음과 같다.
-
엑셀에 단위가 매우 큰 숫자를 넣는 경우 E(지수 형태)로 변환이 되어, 실제 값의 정보가 손실된다.
-
많은 양의 데이터(행이 65,536개 이상)를 관리할 수 없다.
물론, 위 문제가 R에서 패키지를 이용해서 파일을 불러오고 내보내는 상황에서도 적용되는지 확신은 못하지만, 당신이 R에 익숙해지면 익숙해질수록, 엑셀은 느려 터지고, 불편한 툴이라는 생각이 들어서 자동으로 멀리하게 될 것이다. R은 코드를 통해서 작동하므로, 엑셀보다는 진입장벽이 있긴 하지만, R에 익숙해지고 나면, 속도, 기능 등 모든 면에서 R이 압도적이므로, 엑셀로 파일을 관리하는 일은 사라지게 될 것이다.
(필자는 엑셀로 수정할 바에 차라리 R로 코딩을 하는 것을 선호할 정도로 R은 쉽고 빠르다!)
이번 포스트에선 엑셀로 R에 파일을 올리고 내리는 방법에 대해 학습해보았다. 다음 포스트에선 텍스트 파일을 R로 다루는 방법에 대해 학습해보겠다.
'R > Basic' 카테고리의 다른 글
| R 데이터 가지고 오기(1부): 인코딩 문제, csv파일 다루기 (3) | 2020.06.29 |
|---|---|
| R dplyr 패키지와 데이터 전처리 (0) | 2020.06.23 |
| R(기초) 패키지란? (0) | 2020.06.23 |
| R(기초) 데이터 타입 판별과 타입 변환 (0) | 2020.06.22 |
| R(기초) 리스트(List) (0) | 2020.06.22 |