728x90
반응형

지금까지 이미지 분류 모델을 만들고, 학습까지 시켜보았다. 지난 포스트에서는 학습 과정을 보며, 학습이 제대로 이루어졌는지를 평가하고, 최적의 epochs를 결정하는 방법에 대해 공부해보았다.
그러나, 지금 같이 데이터의 양이 작고, epochs가 상대적으로 적은 경우엔 학습이 완전히 끝난 후 그래프를 그려서 학습 과정을 살필 수 있었지만, 만약에 epochs가 1,000 이거나 데이터의 크기가 1,000만 개를 가뿐히 넘겨 학습 시간이 길어지는 경우라면, 이전에 했던 방법으로 접근해서는 안된다.
이때, 등장하는 개념이 바로 조기 종료다.
조기 종료(Early Stopping)
0. 선행 코드
# Import module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout, Flatten)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# Dataset 준비
(train_images, train_labels), (test_images, test_labels)= load_data()
# 무작위로 샘플 추출
np.random.seed(1234)
index_list = np.arange(0, len(train_labels))
valid_index = np.random.choice(index_list, size = 5000, replace = False)
# 검증셋 추출
valid_images = train_images[valid_index]
valid_labels = train_labels[valid_index]
# 학습셋에서 검증셋 제외
train_index = set(index_list) - set(valid_index)
train_images = train_images[list(train_index)]
train_labels = train_labels[list(train_index)]
# min-max scaling
min_key = np.min(train_images)
max_key = np.max(train_images)
train_images = (train_images - min_key)/(max_key - min_key)
valid_images = (valid_images - min_key)/(max_key - min_key)
test_images = (test_images - min_key)/(max_key - min_key)
# 모델 생성
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28], name="Flatten"))
model.add(Dense(300, activation="relu", name="Hidden1"))
model.add(Dense(200, activation="relu", name="Hidden2"))
model.add(Dense(100, activation="relu", name="Hidden3"))
model.add(Dense(10, activation="softmax", name="Output"))
# 모델 컴파일
opt = keras.optimizers.Adam(learning_rate=0.005)
model.compile(optimizer = opt,
loss = "sparse_categorical_crossentropy",
metrics = ["accuracy"])
1. 검증 손실 값과 과대 적합
- 조기 종료를 이해하기 위해선 이전에 만들었던 그래프를 다시 한번 봐야 한다.
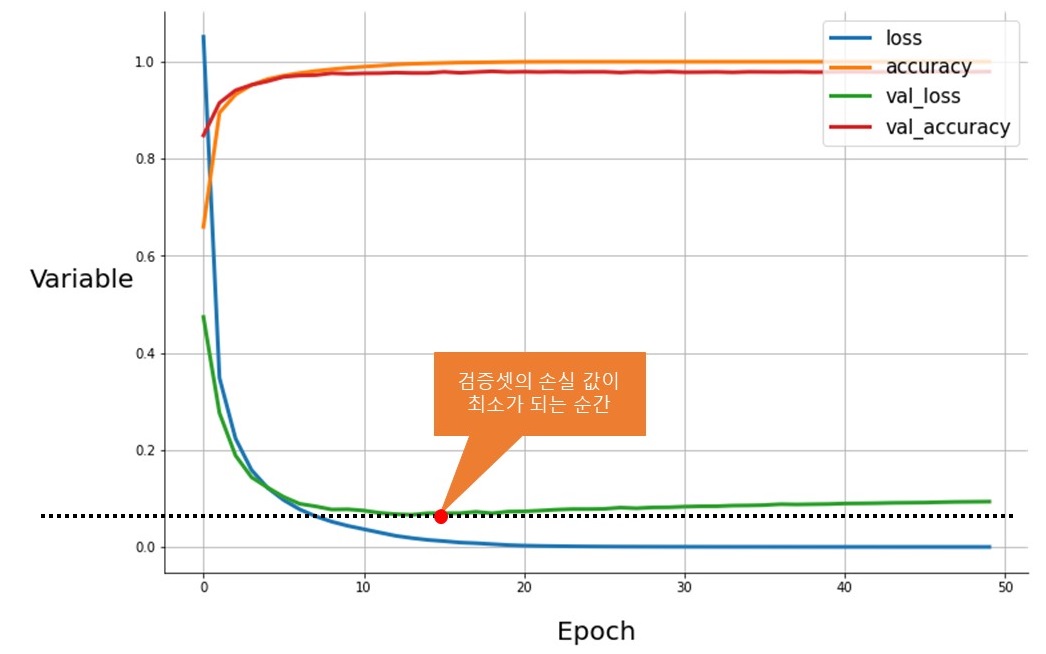
- 위 그래프는 훈련 셋과 검증 셋의 손실 값(Loss)과 정확도(Accuracy)를 시각화한 것이다.
- 검증 셋의 손실 값(val_loss, 녹색)은, 쭉 감소하다가 갑자기 손실 값이 증가하게 된다.
- 이는 모델이 학습 셋에 지나치게 최적화되어, 학습 셋이 아닌 다른 데이터 셋을 이상하게 출력하는 과대 적합(Overfitting) 현상이 발생하여, 일어나는 현상이다.
- 조기 종료는 검증 셋의 손실 값이 최소가 되는 순간(최적의 모델) 학습을 멈춤으로써, 이러한 과대 적합을 멈추는 아주 간단하면서도 강력한 규제 방법 중 하나다.
- 참고: "Tensorflow-3.2. 이미지 분류 모델(2)-검증 셋(Validation set)"
- 조기 종료는 이전 "Tensorflow-3.3. 이미지 분류 모델(3)-모델 생성"에서 잠깐 언급하고 넘어갔던, "스트레치 팬츠(Stretch pants) 방식"을 위한 도구 중 하나다.
2. 콜벡(callbacks)
- 콜벡(callbacks)은 학습 과정에서 영향을 주거나, 발생한 통계 데이터를 출력해주는 함수들의 집합이다.
- 대표적인 callbacks 함수는 이전 포스트에서 우리가 다뤘던 history로, 워낙 유용하다 보니 자동으로 적용되어 있다.
- callbacks 함수는 Sequential이나 .fit() 메서드에 전달 가능하다.
- 조기 종료는 이 callbacks 안에 포함되어 있다.
2.1. 조기 종료
- 조기 종료는 다음과 같은 방법으로 사용할 수 있다.
early_stop = keras.callbacks.EarlyStopping(monitor="val_loss", min_delta=0, patience=10, restore_best_weights=True)
history = model.fit(train_images, train_labels,
epochs=1000,
batch_size=5000,
validation_data=(valid_images, valid_labels),
callbacks=[early_stop])- keras.callbacks.EarlyStopping()의 중요 파라미터는 다음과 같다.
- monitor: 관찰할 값 - 일반적으로 검증 손실 값인 var_loss를 사용하며, 간간히 var_acc가 사용되기도 한다.
- min_delta: 개선 기준 최소 변화량 - 개선되고 있다고 판단할 수 있는 최소 변화량으로 변화량이 min_delta보다 작다면 개선이 없다고 판단한다.
- patience: 정지까지 기다리는 epochs - 당장 최솟값이 나왔다 할지라도, 이 값이 학습을 하다 보면, 더 떨어질 수도 있다. 그러므로, patience에 정해진 epochs만큼 학습을 더 실시하고, 그동안 개선이 없다면, 학습을 멈춘다.
- restore_best_weights: 최선 값이 발생한 때로 모델 가중치 복원 여부 - False로 돼 있다면, 학습의 마지막 단계에서 얻어진 모델 가중치가 사용된다.
- val_loss는 증감을 반복하므로, epochs를 조금 줘서 기다리도록 하자.
- 위 코드를 실행하면 다음과 같은 결과가 나온다.
Epoch 1/1000
11/11 [==============================] - 2s 177ms/step - loss: 1.5362 - accuracy: 0.4834 - val_loss: 0.4362 - val_accuracy: 0.8714
Epoch 2/1000
11/11 [==============================] - 1s 55ms/step - loss: 0.3673 - accuracy: 0.8928 - val_loss: 0.2479 - val_accuracy: 0.9252
Epoch 3/1000
11/11 [==============================] - 1s 55ms/step - loss: 0.2225 - accuracy: 0.9336 - val_loss: 0.1759 - val_accuracy: 0.9436
Epoch 4/1000
11/11 [==============================] - 1s 61ms/step - loss: 0.1550 - accuracy: 0.9539 - val_loss: 0.1353 - val_accuracy: 0.9560
Epoch 5/1000
11/11 [==============================] - 1s 55ms/step - loss: 0.1185 - accuracy: 0.9649 - val_loss: 0.1108 - val_accuracy: 0.9640
...
Epoch 19/1000
11/11 [==============================] - 1s 54ms/step - loss: 0.0032 - accuracy: 0.9997 - val_loss: 0.0786 - val_accuracy: 0.9806
Epoch 20/1000
11/11 [==============================] - 1s 51ms/step - loss: 0.0026 - accuracy: 0.9999 - val_loss: 0.0841 - val_accuracy: 0.9794
Epoch 21/1000
11/11 [==============================] - 1s 52ms/step - loss: 0.0024 - accuracy: 0.9998 - val_loss: 0.0831 - val_accuracy: 0.9794
Epoch 22/1000
11/11 [==============================] - 1s 60ms/step - loss: 0.0017 - accuracy: 1.0000 - val_loss: 0.0800 - val_accuracy: 0.9798
Epoch 23/1000
11/11 [==============================] - 1s 51ms/step - loss: 0.0013 - accuracy: 1.0000 - val_loss: 0.0845 - val_accuracy: 0.9792- epochs를 1000으로 지정하였으나, val_loss가 최솟값을 찍었기 때문에 epoch 23에서 학습을 정지하였다.
- 조기 종료를 사용하면, 별도의 과정 없이, 손쉽게 최적의 epochs를 찾아낼 수 있으므로, 오차 역전파법을 찾아내 지금의 딥 러닝을 있게 한 1등 공신 중 한 명인 제프리 힌턴은 조기 종료를 "훌륭한 공짜 점심(beautiful free lunch)"이라고 불렀다고 한다.
- 이외에도 콜벡에는 학습 중간에 자동 저장을 하는 ModelCheckPoint나 학습률을 스케쥴링하는 LearningRateSchedule 등 유용한 기능이 많다. 관심 있는 사람은 다음 아래 사이트를 참고하기 바란다.
(keras.io/ko/callbacks/)
Callbacks - Keras Documentation
Usage of callbacks 콜백은 학습 과정의 특정 단계에서 적용할 함수의 세트입니다. 학습 과정 중 콜백을 사용해서 모델의 내적 상태와 통계자료를 확인 할 수 있습니다. 콜백의 리스트는 (키워드 인수
keras.io
[참고 서적]

지금까지 조기 종료(Early stopping)와 콜백에 대해 알아보았다. 다음 포스트에서는 최종 과정인 모델 평가와 모델 저장 및 불러오기에 대해 학습해보도록 하겠다.
728x90
반응형
'Machine Learning > TensorFlow' 카테고리의 다른 글
| Tensorflow-4.0. 다층 퍼셉트론을 이용한 회귀모형 만들기 (0) | 2021.02.23 |
|---|---|
| Tensorflow-3.8. 이미지 분류 모델(8)-모델 저장과 불러오기 (0) | 2021.02.17 |
| Tensorflow-3.6. 이미지 분류 모델(6)-학습과정 확인 (0) | 2021.02.17 |
| Tensorflow-3.5. 이미지 분류 모델(5)-모델 학습 (0) | 2021.02.17 |
| Tensorflow-3.4. 이미지 분류 모델(4)-모델 컴파일 (0) | 2021.02.16 |