
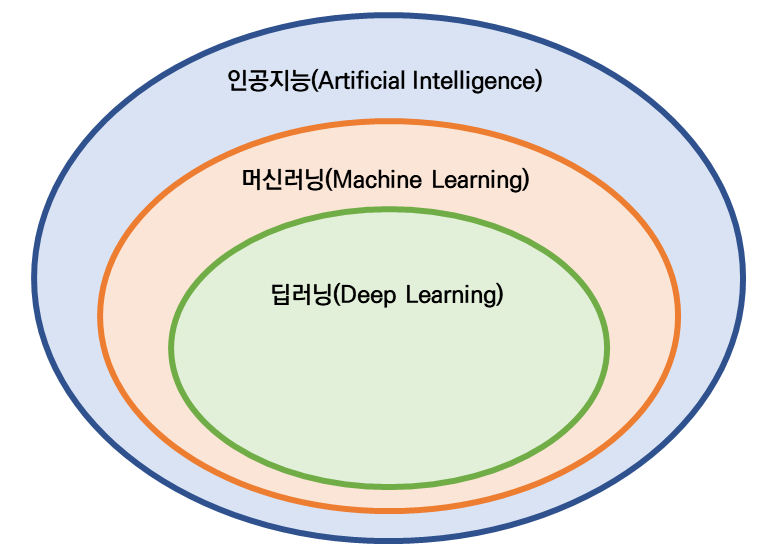
현재 컴퓨터를 사용하는 모든 분야에서 가장 핫한 분야를 한 가지 고르라고 한다면, 장담컨대 "인공지능 > 머신러닝 > 딥러닝"을 꼽을 수 있을 것이다. 알파고 이후로 모든 매체에서는 인공지능, 머신러닝, 딥러닝이라는 단어를 외치고 있으며, 이 것이 중요하다는 것은 알겠는데 구체적으로 어떻게 중요한지, 그리고 이 것이 구체적으로 무엇인지를 제대로 설명해주는 곳은 많지가 않다.
이번 포스트에서는 "인공지능 > 머신러닝 > 딥러닝"으로 이어지는 단어들에 대해 설명하고, 앞으로의 학습 방향에 대해 이야기해보도록 하겠다.
1. 인공지능(AI)이란?
인공지능이라는 단어를 들으면 막연하게 "터미네이터 같은 인간과 유사한 생김새를 갖고 있으며, 인간보다 뛰어난 능력을 가진 존재"라는 생각이 들 것이다. 인공지능은 크게 General AI(일반적인 AI)와 Narrow AI(좁은 AI) 두 가지로 나뉘는데, 이를 설명해보면, 대충 감이 올 것이다.
General AI
- 영화에 나오는 인공지능으로 인간처럼 사고를 하며, 상황에 맞는 다양한 활동을 하는 인공지능을 말한다.
- 예를 들자면 자신의 다리로 계단이던 길이던 횡단보도던 알아서 돌아다니고, 필요에 따라 판단하여 택시나 버스를 타고, 에너지가 부족하다 싶으면 알아서 에너지도 충전하고, 회사에 출근해서 눈치를 살피는 그런 인간과도 같은 존재를 가리킨다.
- 이런 복합적인 기능을 자유자재로 동시에 수행하는 것은 아직까진 우리 상상 속에만 존재하며, 영화나 드라마에서만 나오는 존재다.
Narrow AI
- 말 그대로 좁은 영역에서의 인공지능을 말하며, 특정한 행동에 대해서만 특화 돼 있는 인공지능이다.
- 가장 유명한 인공지능인 알파고는 바둑에 특화된 인공지능으로, 학습을 위해 바둑 기보들을 수집하고, 학습된 내용을 바탕으로 스스로 경쟁하여 바둑을 학습해, 바둑이라는 게임에서 승리할 수 있도록 만든 것이다.
- 학교, 뉴스, 4차 산업 혁명에 해당하는 인공지능이 바로 Narrow AI이다.
- 우리가 앞으로 학습할 인공지능이 이 곳에 해당한다.
2. 머신러닝(Machine Learning)이란?
머신러닝은 위에서 이야기한 Narrow AI에 속하는데, 말 그대로 기계를 학습시킨다는 말이다.
갓 태어난 아이는 성장을 하며 말을 배우고, 친구를 사귀는 법을 배우며, 국어, 영어, 수학 같은 학문을 배운다. 나아가 음악을 들었을 때, 이 음악이 어떤 음악이었는지 그 제목을 떠올리기도 하고, 그림을 보고 그림의 제목과 화가의 이름을 맞추기도 한다.
우리가 처음으로 말을 배웠을 땐, 부모님이 하는 말을 계속 들어왔고, 부모님들은 사물에 사물 이름을 적은 메모장을 붙여놓는 방법 등을 통해 우리를 가르쳤다. 친구를 사귀는 법은 다양한 사람을 만나가며, 어떻게 하면 그들과 유대감을 쌓을 수 있는지 경험으로 익혔다. 국어, 영어, 수학 같은 학문은 계속 책을 보며, 문제를 푸는 방법과 사고하는 방법을 익혔다. 음악이나 그림을 판단하는 방법도 다양한 음악이나 그림을 접하면서 그것들을 구분하는 능력을 쌓았다.
위 예시에서 우리는 오로지 데이터만을 가지고 지금의 복잡한 작업을 수월하게 할 수 있게 된 것이다. 컴퓨터를 이용한 기계학습 역시 이와 유사하게 이루어진다. 기본적인 머신러닝 알고리즘이 존재하고, 그 알고리즘에 데이터를 부어넣으면, 그 데이터가 가지고 있는 패턴을 찾아내, 그 패턴대로 분류하게 되는 것이 바로 머신러닝이다.
3. 딥러닝(Deep Learning)이란?
1943년 논리학자 윌터 피츠(Walter Pitts)와 신경외과의 워렌 맥컬럭(Warren Mc Cullonch)은 "A Logical Calculus of Ideas Immanent in Nervous Activity"라는 논문에서 딥러닝의 기반이 되는 인공신경망이라는 개념을 등장시켰고, 인간의 신경세포를 모방한 퍼셉트론을 등장시켰다.
퍼셉트론을 이용한 인공지능 연구능 처음엔 굉장한 인기를 끌었으나, 굵직 굵직한 사건이 터져 몇 번이고 사장될 위기에 처했었다. 처음엔 XOR 게이트로 인해 퍼셉트론은 선형 분류밖에 할 수 없다는 한계점이 등장했고, 이를 다층 퍼셉트론(MLP)라는 개념을 등장시켜 선형 분류의 한계점을 해결하였으나, MLP를 학습시킬 방법이 없다는 한계점이 또 등장하였다. 이는 오류역전파(Backpropagation of errors)라는 기법으로 해결하였으나, 층이 늘어날수록 기울기가 소실되는 문제가 또 등장하고, 은닉층 활성화 함수로 Sigmoid 대신 ReLU를 사용하여 해결하는 등 수많은 과정을 거쳐 지금의 딥러닝이 탄생하게 되었다.
딥러닝이라는 이름이 생긴 이유도 기존의 다층 퍼셉트론(MLP)에 대한 부정적인 시선을 피하기 위해 딥러닝이라는 새로운 이름을 붙인 것이며, 다층 퍼셉트론(MLP)의 은닉층을 아주 많이 쌓기 때문에 딥(Deep)해진다. 즉, Layer가 깊어진다라는 의미에서 딥러닝이라는 이름이 붙은 것이다.
딥러닝 역시 머신러닝의 한 갈래에 속하지만, 머신러닝에는 퍼셉트론을 포함하여 수많은 이론들이 존재하므로, 머신러닝과 딥러닝을 분리해서 생각하는 것이 좋다.
해당 카테고리에서는 머신러닝에 대해서 학습할 계획이며, 딥러닝에 대해서는 Deep Learning 카테고리에서 따로 학습할 예정이다.
'Machine Learning > Basic' 카테고리의 다른 글
| 머신러닝-1.3. 사례 기반 학습과 모델 기반 학습 (0) | 2021.03.19 |
|---|---|
| 머신러닝-1.2. 배치 학습과 온라인 학습 (0) | 2021.03.15 |
| 머신러닝-1.1. 지도 학습 & 비지도 학습 & 준지도 학습 & 강화 학습 (0) | 2021.03.15 |
| 머신러닝-1.0. 전통적인 기법과 머신러닝의 차이 (0) | 2021.03.14 |
| 기계학습(Machine Learning)이란? (0) | 2020.06.27 |

