728x90
반응형

이전 포스트에서는 학습 단위에 대한 단어인 에포크(Epoch), 배치 크기(Batch size), 이터레이션(Iteration)에 대해 알아보았다. 이번 포스트에서 알아볼 확률적 경사 하강법(SGD)의 키는 배치 크기와 랜덤 추출이다.
경사 하강법에 다른 식을 붙이지 않고 바로 사용하는 방법은 크게 두 가지인 배치 경사 하강법(BGD)과 확률적 경사 하강법(SGD)이 있는데, 이 둘은 손실 함수의 기울기 계산에 사용되는 데이터 셋의 규모만 제외하고 같다.
중요한 것은 손실 함수의 경사를 구하는 대상이다!
1. 배치 경사 하강법(Batch Gradient Descent, BGD)
- 배치 경사 하강법(BGD)은 경사 하강법의 손실 함수의 기울기 계산에 전체 학습 데이터셋의 크기와 동일하게 잡는 방법이다.
- 즉, 경사 하강법 대상이 배치 크기와 동일하다는 것이다.
- 데이터셋 모두를 대상으로 하다 보니 파라미터가 한번 이동할 때마다, 계산해야 할 값이 지나치게 많으므로, 계산 시간도 엄청 길어지고, 소모되는 메모리도 엄청나다.
- mini batch 안 모든 데이터를 대상으로 경사 하강법을 실시하므로, 안정적으로 수렴한다.

- 안정적으로 수렴하므로, 수렴까지 발생하는 총 파라미터 업데이트 수는 매우 적다.
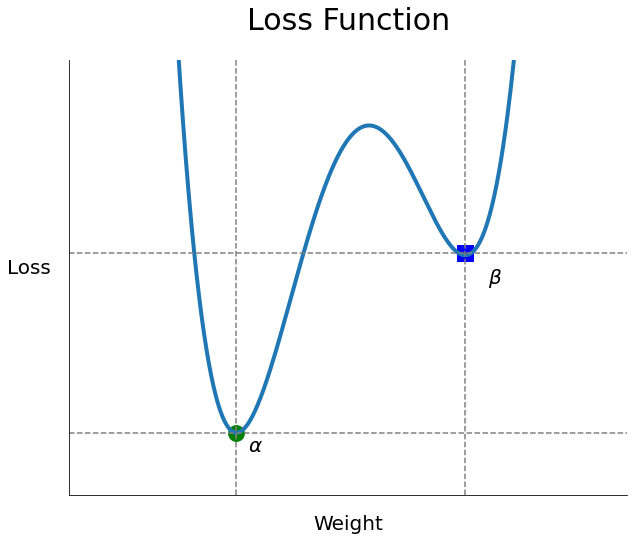
- 안정적으로 수렴하는 것은 좋으나, 안정적으로 움직이기 때문에 지역 최소해(Local Minimum)에 빠지더라도 안정적으로 움직이므로 빠져나오기 힘들다. 즉, Local Optima(minimum) 문제가 발생할 가능성이 높다.
- 학습 데이터셋이 커지면 커질수록 시간과 리소스 소모가 지나치게 크다.
2. 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
- 전체 훈련 데이터셋을 대상으로 학습하는 것은 한정된 리소스를 가지고 있는 우리의 분석 환경에서 매우 비효율적이며, 파라미터 업데이트 수가 적다는 것은 랜덤 하게 뽑힌 시작 위치의 가중치 수도 적으므로, Local minimum 현상이 발생할 확률도 높다는 것이다.
- 그래서 나온 방법이 학습 데이터셋에서 무작위로 한 개의 샘플 데이터 셋을 추출하고, 그 샘플에 대해서만 기울기를 계산하는 것이다.
- 샘플 데이터 셋에 대해서만 경사(Gradient)를 계산하므로, 매 반복에서 다뤄야 할 데이터 수가 매우 적어, 학습 속도가 매우 빠르다.
- 하나의 샘플만 대상으로 경사를 계산하므로, 메모리 소모량이 매우 낮으며, 매우 큰 훈련 데이터 셋이라 할지라도 학습 가능하다.
- 그러나, 무작위로 추출된 샘플에 대해서 경사를 구하므로, 배치 경사 하강법보다 훨씬 불안정하게 움직인다.

- 손실 함수가 최솟값에 다다를 때까지 위아래로 요동치며 움직이다 보니, 학습이 진행되다 보면, 최적해에 매우 근접하게 움직이긴 하겠으나, 최적해(Global minimum)에 정확히 도달하지 못할 가능성이 있다.
- 그러나, 이렇게 요동치며 움직이므로, 지역 최솟값(Local minimum)에 빠진 다할지라도, 지역 최솟값에서 쉽게 빠져나올 수 있으며, 그로 인해 전역 최솟값(Global minimum)을 찾을 가능성이 BGD에 비해 더 높다.
- 즉, 확률적 경사 하강법(SGD)은 속도가 매우 빠르고 메모리를 적게 먹는다는 장점이 있으나, 경사를 구할 때, 무작위성을 띄므로 지역 최솟값에서 탈출하기 쉬우나, 전역 최솟값에 다다르기 힘들다는 단점을 가지고 있다.
- 이 문제를 해결하기 미니 배치 경사 하강법(mini-Batch gradient descent)이 등장하였다.
학습률 스케줄(Learning rate schedule)
- 전역 최솟값에 도달하기 어렵다는 문제를 해결하기 위한 방법으로, 학습률을 천천히 줄여 전역 최솟값에 다다르게 하는 방법이 있다.
- 학습률은 작아질수록 이동하는 양이 줄어들기 때문에 전역 최솟값에 안정적으로 수렴할 수 있다.
- 만약 학습률이 너무 급격하게 감소하면, Local Optima 문제나 Plateau 현상이 발생할 가능성이 높아진다.
- 그렇다고 학습률을 너무 천천히 줄이면 최적해 주변을 맴돌 수 있다.
3. 미니 배치 경사 하강법(mini-Batch gradient descent)
- 앞서 이야기한 배치 경사 하강법(BGD)나 확률적 경사 하강법(SGD)은 모두 배치 크기가 학습 데이터 셋 크기와 동일하였으나, 미니 배치 경사 하강법은 배치 크기를 줄이고, 확률적 경사 하강법을 사용하는 기법이다.
- 예를 들어, 학습 데이터가 1000개고, batch size를 100으로 잡았다고 할 때, 총 10개의 mini batch가 나오게 된다. 이 mini batch 하나당 한 번씩 SGD를 진행하므로, 1 epoch당 총 10번의 SGD를 진행한다고 할 수 있다.
- 일반적으로 우리가 부르는 확률적 경사 하강법(SGD)은 실제론 미니 배치 경사 하강법(mini-BGD)이므로, 지금까지 학습했던 차이들은 기억하되, 앞으로 SGD를 말하면, 미니 배치 경사 하강법을 떠올리면 된다.

- 미니 배치 경사 하강법은 앞서 이야기했던, 전체 데이터셋을 대상으로 한 SGD보다 파라미터 공간에서 Shooting이 줄어들게 되는데, 이는 한 미니 배치의 손실 값 평균에 대해 경사 하강을 진행하기 때문이다.
- 그로 인해, 최적해에 더 가까이 도달할 수 있으나, Local optima 현상이 발생할 수 있다. 그러나, 앞서 말했듯 Local optima 문제는 무수히 많은 임의의 파라미터로부터 시작되면, 해결되는 문제이며, 학습 속도가 빠른 SGD의 장점을 사용하여, 학습량을 늘리면 해결되는 문제다.
- 배치 크기는 총 학습 데이터셋의 크기를 배치 크기로 나눴을 때, 딱 떨어지는 크기로 하는 것이 좋다.
- 만약, 1050개의 데이터에 대하여 100개로 배치 크기를 나누면, 마지막 50개 데이터셋에 대해 과도한 평가를 할 수 있기 때문이다.
- 그러나, 만약 배치 크기로 나누기 애매한 경우라면, 예를 들어 총 학습 데이터 셋이 1,000,050개가 있고, 배치 크기를 1,000개로 나누고 싶은 경우라면, 나머지인 50개는 버리도록 하자(물론 완전 무작위 하게 50개를 선택해서 버려야 한다.).
지금까지 확률적 경사 하강법(SGD)에 대해 알아보았다. 본래의 SGD는 "배치 크기 = 학습 데이터 셋 크기"이지만, 일반적으로 통용되는 SGD는 "배치 크기 < 학습 데이터 셋 크기"인 미니 배치를 만들어 학습시키는 미니 배치 경사 하강법이다.
경사 하강법의 파이썬 코드화는 경사 하강법 함수 자체는 단순하지만, 학습에서 발생하는 모든 알고리즘이 복합적으로 작동하므로, 코드화시키는 것은 시간 낭비로 판단된다. Optimizer 파트부턴 그 개념과 특징을 이해하고, 텐서플로우로 학습을 해보도록 하자.
다음 포스트에서는 경사 하강법의 한계점을 보완하기 위한 시도 중 하나인 모멘텀(Momentum)에 대해 학습해보도록 하겠다.
728x90
반응형
'Machine Learning > Deep Learning' 카테고리의 다른 글
| 딥러닝-6.4.최적화(5)-확률적 경사 하강법(SGD) 파이썬 코드 구현 (1) | 2021.02.06 |
|---|---|
| 딥러닝-6.2. 최적화(3)-학습 단위(Epoch, Batch size, Iteration) (2) | 2021.02.05 |
| 딥러닝-6.1. 최적화(2)-경사하강법의 한계점 (0) | 2021.02.04 |
| 딥러닝-6.0. 최적화(1)-손실함수와 경사하강법 (0) | 2021.02.03 |
| 딥러닝-5.5. 손실함수(6)-범주형 교차 엔트로피 오차(CCEE) (0) | 2021.02.01 |