728x90
반응형

테스트와 검증
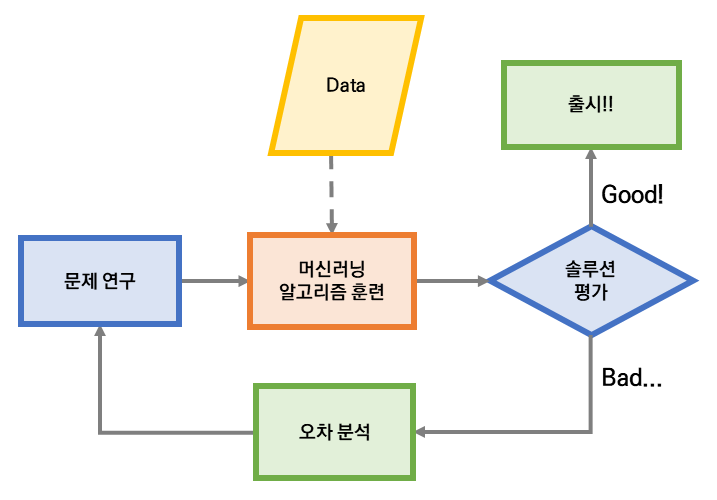
이전 포스트에서는 머신 러닝 사용 시 주의해야 할 사항에 대해 알아보았다. 이번 포스트에서는 학습이 끝난 모델을 어떻게 평가하는지에 대해 알아보도록 하겠다.
1. 데이터 셋 나누기
- 학습이 완료된 모델이 새로운 데이터에 대해 얼마나 잘 일반화되는지 알아보기 위해선, 학습에 사용하지 않은 새로운 데이터를 실제로 넣어보고, 잘 작동하는지 확인해봐야 한다.
- 그러나, 현장에서 새로운 데이터를 구하는 것은 굉장히 어려운 일이기 때문에, 학습에 사용할 훈련 데이터를 훈련 데이터 셋(Train dataset)과 테스트 데이터 셋(Test dataset)으로 나누는 것이 가장 현실적이다.
- 훈련 데이터셋으로 학습을 진행하고, 테스트 데이터 셋을 이용해서 모델을 평가하면, 테스트 데이터 셋에 대한 모델의 오차 비율을 얻을 수 있으며, 이를 일반화 오차(Generalization error) 또는 외부 샘플 오차(Out-of-sample error)라고 한다.
- 훈련 데이터에 대한 오차는 낮으나, 테스트 데이터에 대한 오차인 일반화 오차가 높다면, 이는 모델이 훈련 데이터에 과적합(Overfitting) 되었다는 것을 의미한다.
- 위 경우, 훈련 데이터에 과적합되는 것을 피하기 위해, 일반화 오차를 줄이는 방향으로, 하이퍼 파라미터 튜닝 등 다양한 작업을 수행할 수 있는데, 이 경우 단순히 결과 지표를 뽑기 위해 사용해야 하는 테스트 데이터 셋에 모델이 과적합되는 문제가 발생할 수 있다.
1.1. 검증 데이터 셋(Validation dataset)
- 검증 데이터 셋은 모델이 시험 셋(Test dataset)에 과대적합되는 것을 막기 위해, 훈련 데이터 셋에서 일부분을 추가로 추출하여, 모델 적합도의 기준으로 사용하는 데이터 셋이다.
- 전체 데이터 셋의 규모가 적거나, 검증 데이터 셋이 훈련 데이터 셋을 대표하지 못한다면, 데이터가 편향되는 결과가 발생할 수 있으므로, 교차 검증(Cross-Validation)과 같은 다양한 방법으로, 이를 해결한다.
- 물론, 데이터 셋의 양이 굉장히 많다면, 교차 검증은 현실적으로 사용이 불가능하며, 훈련 셋의 각 클래스별 비율에 맞는 데이터 셋을 추출하여, 대표성이 높은 검증 셋을 뽑을 수 있다.
- 이외 데이터 셋에 대한 보다 자세한 정보를 알고자 하면, 이전 포스트인 "Tensorflow-1.0. 기초(1)-데이터 셋 만들기"와 "Tensorflow-3.2. 이미지 분류 모델(2)-검증 셋(Validation set)"을 참고하기 바란다.
2. 하이퍼 파라미터 튜닝
- 하이퍼 파라미터 튜닝은 위에서 만든 학습 셋(Train set), 검증 셋(Validation set), 시험 셋(Test set)을 사용하여, 모델을 평가하며, 모델의 일반화 오차가 최소화되는 하이퍼 파라미터를 탐색하는 과정이다.
- 앞서 이야기 한, 학습 셋으로 만들어진 모델의 하이퍼 파라미터를 시험 셋에 과대적합 시키는 현상을 막기 위해, 검증 셋을 사용하는 것을 홀드 아웃 검증(Holdout validation)이라고 한다.
- 하이퍼 파라미터를 탐색하는 과정은 그리드 서치(Greed search), 랜덤 서치(RandomizedSearch), 베이지안 옵티마이저(Baysian optimizer) 등의 방법을 통해 가장 적합한 하이퍼 파라미터를 찾아낸다.
3. 공짜 점심 없음(No free lunch, NFL) 이론
- 1996년 David Wolpert가 발표한 "The Lack of A Priori Distinctions Between Learning Algorithms."에서 나온 공짜 점심 없음 이론은, 경험해보기 전까진 해당 데이터에 더 잘 맞을 것이라고 보장할 수 있는 모델은 존재하지 않는다는 내용이다.
- 머신러닝 알고리즘에서 사용되는 모델들은 관측된 데이터들을 간소한 것으로, 새로 들어온 데이터에서 일반적이지 않을 것으로 보이는 불필요한 세부 사항을 제거하는 것이다.
- 이러한 불필요한 세부 사항은 각 머신러닝 알고리즘이 만들어진 원리에 따라 다르게 정해진다.
- 때문에, 가장 핫한 머신러닝 모델 중 하나인 딥러닝 모델의 성능이 아무리 좋다고 할지라도, 경우에 따라서는 훨씬 단순한 선형 회귀 모델이 해당 데이터에는 더 적합할 수도 있다는 의미이다.
- 때문에 해당 데이터에 관련된 다양한 모델들을 평가해보고, 이를 비교하여, 적절한 모델을 선택하도록 해야 한다.
- 이는, 모든 머신러닝 모델을 각 데이터에 적용하라는 것이 아니라, 데이터의 복잡도, 데이터의 크기, 해당 데이터 성격에 관련된 모델 등 다양한 요소를 감안하여, 적합한 머신러닝 모델을 일부 선택한 후, 이들을 비교해보라는 의미이다.
[참고 서적]

728x90
반응형
'Machine Learning > Basic' 카테고리의 다른 글
| 머신러닝-1.4. 머신러닝 사용 시 주의해야 할 사항들 (0) | 2021.03.19 |
|---|---|
| 머신러닝-1.3. 사례 기반 학습과 모델 기반 학습 (0) | 2021.03.19 |
| 머신러닝-1.2. 배치 학습과 온라인 학습 (0) | 2021.03.15 |
| 머신러닝-1.1. 지도 학습 & 비지도 학습 & 준지도 학습 & 강화 학습 (0) | 2021.03.15 |
| 머신러닝-1.0. 전통적인 기법과 머신러닝의 차이 (0) | 2021.03.14 |