728x90
반응형

지금까지 Index와 위치를 이용해서 데이터를 조회하는 방법에 대해 알아보았다. Index, 위치를 이용하여 행을 조회하는 것이 가장 빠르지만, 현실적으로 내가 원하는 데이터의 Index와 행의 위치를 미리 아는 것은 불가능하므로 이번 포스팅에서는 특정 조건으로 내가 원하는 행을 찾아내는 방법에 대해 학습해보도록 하겠다.
Pandas와 Boolean
불리언(Boolean)은 논리 자료형이라고도 하며, 참(True)과 거짓(False)을 나타낼 때 사용된다. Python에서 참(True)은 1, 거짓(False)은 0의 정수 값을 가지며, 이 특성을 잘 활용하면 재밌는 코드를 많이 만들어낼 수 있다.
>>> print(f"True의 Type: {type(True)}")
>>> print(f"False의 Type: {type(False)}")
>>> print("----"*10)
>>> print(f"True를 수치로 표현 시: {int(True)}")
>>> print(f"False를 수치로 표현 시: {int(False)}")
>>> print("----"*10)
>>> print(f"True를 수치로 표현 시: {float(True)}")
>>> print(f"False를 수치로 표현 시: {float(False)}")
True의 Type: <class 'bool'>
False의 Type: <class 'bool'>
----------------------------------------
True를 수치로 표현 시: 1
False를 수치로 표현 시: 0
----------------------------------------
True를 수치로 표현 시: 1.0
False를 수치로 표현 시: 0.0Pandas는 Boolean Series를 이용하여 True인 행은 출력하고, False인 행은 출력하지 않을 수 있다. 이를 더 쉽게 이야기해보면, "내가 원하는 행만 True로 만들면 그 행만 조회할 수 있다"는 것이다.
1. 예제 데이터와 라이브러리 가지고 오기
※ 예제 데이터
이번 포스트에서도 지금까지 사용한 "시험점수.csv" 파일을 예제 데이터로 사용해보도록 하겠다.
사용할 라이브러리는 pandas지만, pandas와 함께 다니는 친구인 numpy도 혹시 쓸 일이 있을지 모르니 가져와주도록 하자.
>>> import pandas as pd
>>> import numpy as np
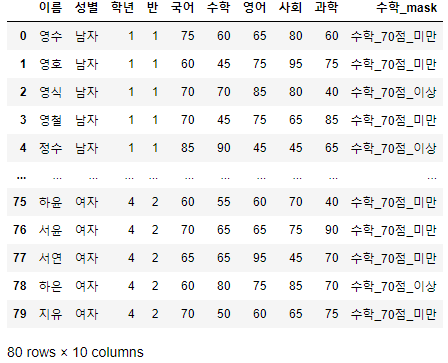
>>> FILE_PATH = "시험점수.csv">>> 시험점수 = pd.read_csv(FILE_PATH, encoding="euckr")
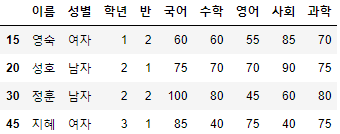
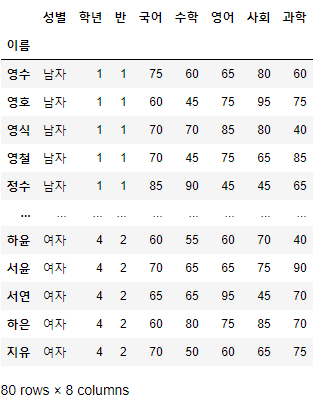
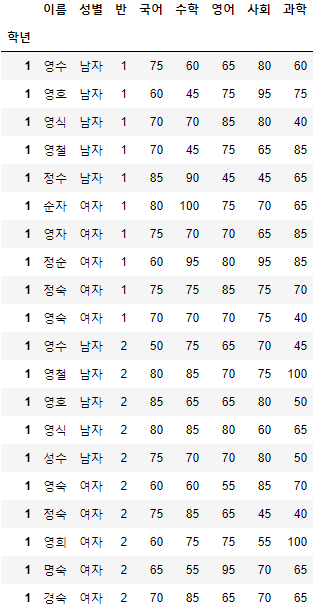
>>> 시험점수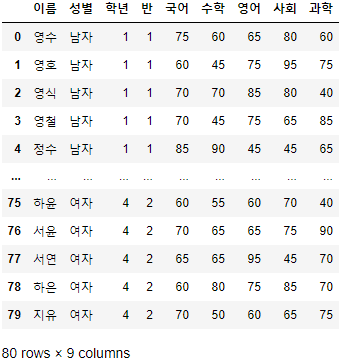
- 해당 예제 데이터는 이름, 성별, 학년, 반, 국어, 수학, 영어, 사회, 과학 총 9개의 열과 80개의 행으로 구성되어 있다.
- 한글이 깨지는 경우, 위 코드처럼 pd.read_csv(File_path, encoding='euckr')로 불러오면 된다.
2. Series와 Boolean
- DataFrame에서 조회할 대상을 가정해보자.
- 조회할 대상: 3학년이고 2반에 있으며, 국어 점수가 70점 이상인 여학생을 찾는다.
- 위 대상에 해당하는 속성이 4개나 되므로, 한 번에 찾기는 쉽지 않다.
- 위 문구를 구성하는 조건을 최소 단위로 쪼개보자.
- 조건 1: 학년 == 3
- 조건 2: 반 == 2
- 조건 3: 국어 >= 70
- 조건 4: 성별 == "여자"
- 문구를 최소 단위로 쪼개 보니 꽤 단순해졌다!
- 방금 정의한 "조회할 대상"은 위 조건 4개에 대해 모두 참(True)인 행이다.
- 즉, 위 조건 4개에 대해 모두 True인 행을 표현만 할 수 있다면, 위 행에 해당하는 사람의 데이터만 가지고 올 수 있다는 것이다.
- 지금까지 우리는 Pandas에서 다양한 변수를 담고 있는 데이터(다변량 데이터) 타입인 DataFrame을 다뤄봤는데, 이번엔 단 하나의 변수만 담고 있는 데이터(단변량 데이터) 타입인 시리즈(Series)로 접근을 해보도록 하자.
2.1. 단변량 데이터를 담는 시리즈(Series)
- 시리즈는 데이터 프레임에서 하나의 컬럼만 뽑으면 쉽게 만들 수 있다.
- 데이터 프레임 "시험점수"에서 "성별" 시리즈를 뽑아보자.
>>> 시험점수["성별"]
0 남자
1 남자
2 남자
3 남자
4 남자
..
75 여자
76 여자
77 여자
78 여자
79 여자
Name: 성별, Length: 80, dtype: object- 시리즈는 각 Value에 대한 Index 정보, 시리즈의 이름(Name), 시리즈를 구성하는 원소의 수(Length), 시리즈의 데이터 타입(dtype) 정보를 담고 있다.
- 이를 하나의 변수만 담고 있는 데이터 프레임이라고 생각해도 큰 문제는 없다.
- 시리즈는 데이터 프레임에서 사용 가능한 함수의 대부분을 지원하므로, 데이터 프레임을 쓸 줄 안다면 큰 어려움 없이 익숙해질 수 있다.
- 단, "시리즈 = 하나의 변수만 담긴 데이터 프레임"은 절대 아니다! 주의하도록 하자!
- 시리즈는 DataFrame을 만들었던 방법처럼 list나 numpy array 등을 이용해 쉽게 만들 수 있다.
>>> Test_list = ["감", "바나나", "포도", "딸기"]
>>> pd.Series(data=Test_list, name="과일")
0 감
1 바나나
2 포도
3 딸기
Name: 과일, dtype: object
3. Boolean Series를 이용하여 원하는 행을 조회하기.
3.1. 단변량 데이터인 시리즈에 조건 걸기
- "시험점수" 데이터 프레임에서 "성별" 시리즈를 뽑고, "여자"인 대상을 찾아보자.
- Python은 기본적으로 다음과 같은 비교 연산자를 제공한다.
| 뜻 | 같다 | 다르다 | 크다 | 작다 | 이상 | 이하 |
| 기호 | == | != | > | < | >= | <= |
- 위 비교 연산자를 이용하여 "성별" == "여자"인 대상자를 찾아보자.
>>> 시험점수["성별"] == "여자"
0 False
1 False
2 False
3 False
4 False
...
75 True
76 True
77 True
78 True
79 True
Name: 성별, Length: 80, dtype: bool- 비교 연산자를 사용하자 True와 False로 이루어진 Series가 출력되었다.
- 이 Series에서 True는 "성별" == "여자"인 행을 뜻하며, False는 "성별" != "여자"인 행을 뜻한다.
- 위에서 생성한 Boolean 시리즈를 이용해서, 제대로 탐색을 하였는지 확인해보도록 하자.
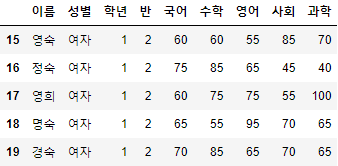
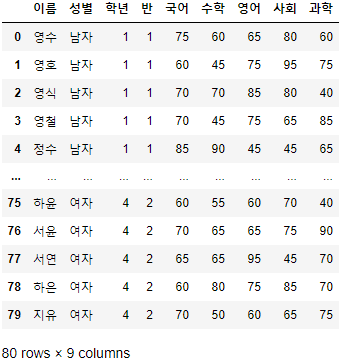
>>> 시험점수[시험점수["성별"] == "여자"].head(10)
- 출력되는 결과가 매우 길어 df.head(n) 함수를 이용해 상위 n개의 행만 출력되게 하였다.
- Pandas의 데이터 프레임은 df[Boolean Series]를 하면, Boolean Series에서 True에 해당하는 행만 출력한다.
- 앞서, Boolean은 True는 1, False는 0의 값을 갖는다고 하였는데, 이 성질을 이용하면 "성별"=="여자"인 대상의 수를 알 수 있다.
>>> sum(시험점수["성별"] == "여자")
40- sum()은 괄호 안의 list, array, series 등의 Data type에 대해 합계를 내주는 함수로, 40이 나왔으므로 1이 40개 있다는 것을 보여준다.
- 이는 "성별"=="여자"인 행이 40개 있다는 것으로, 여성의 수가 40명이라는 것을 의미한다.
- 등호가 돌아가는 원리를 알았으니 이번엔 부등호를 조건으로 걸어보자.
- 이번엔 부등호로 조회를 해보자.
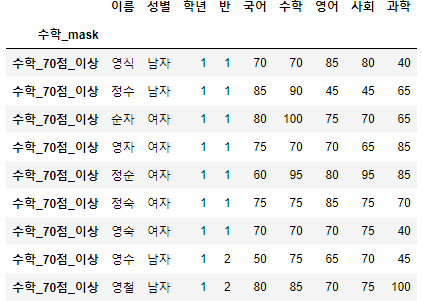
- 이번에는 국어 점수가 70점 이상인 대상을 찾아보자.
>>> 시험점수[시험점수["국어"] >= 70].head(10)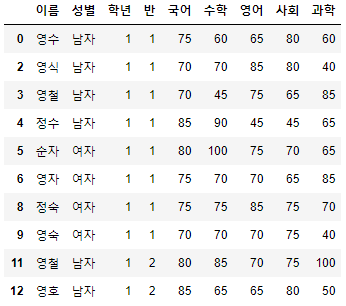
- 국어 점수가 70점 이상인 상위 10명을 뽑아 보았다.
- 부등호도 등호와 마찬가지로 쉽게 뽑을 수 있다.
3.2. 동시에 2개 이상의 조건 걸기
- 앞서 시리즈를 이용해 단변량 데이터에 대해 조건을 걸어보았다.
- 이번엔 2개의 시리즈를 동시에 사용하여 다변량 데이터에 대한 조건을 걸어보도록 하겠다.
- 이때 사용되는 것이 옛날에 배웠던 집합(Set)이다.
- Python에서 주로 사용되는 집합은 교집합, 합집합, 차집합이며, 이들은 다음과 같은 기호를 통해 사용할 수 있다.
| 집합 | 교집합 | 합집합 | 차집합 |
| 기호 | & | | | - |
- 2개의 Boolean Series를 가지고 와보자.
>>> 여자_Boolean_Sr = 시험점수["성별"] >= "여자"
>>> 국어_Boolean_Sr = 시험점수["국어"] >= 70
>>> print(여자_Boolean_Sr)
>>> print("----"*10)
>>> print(국어_Boolean_Sr)
0 False
1 False
2 False
3 False
4 False
...
75 True
76 True
77 True
78 True
79 True
Name: 성별, Length: 80, dtype: bool
----------------------------------------
0 True
1 False
2 True
3 True
4 True
...
75 False
76 True
77 False
78 False
79 True
Name: 국어, Length: 80, dtype: bool- 두 Boolean 시리즈를 교집합 해보자.
>>> 여자_Boolean_Sr & 국어_Boolean_Sr
0 False
1 False
2 False
3 False
4 False
...
75 False
76 True
77 False
78 False
79 True
Length: 80, dtype: bool- 두 시리즈 모두 True인 행만 True로 나오고, 둘 중 하나라도 False인 행은 False가 되었다.
- 교집합은 두 가지에 모두 해당해야 한다는 의미이므로, 모두 True인 대상을 가지고 온다.
- 즉, 두 조건에 동시에 해당하는 행만 교집합 시, True로 출력된다.
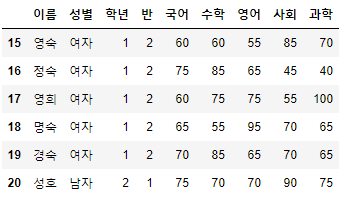
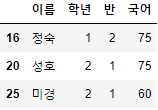
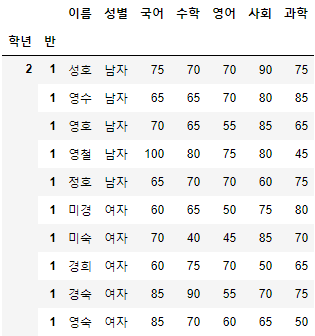
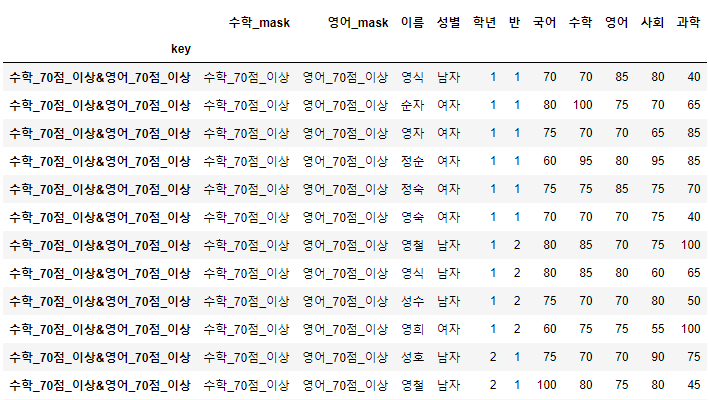
>>> 시험점수[여자_Boolean_Sr & 국어_Boolean_Sr].head(10)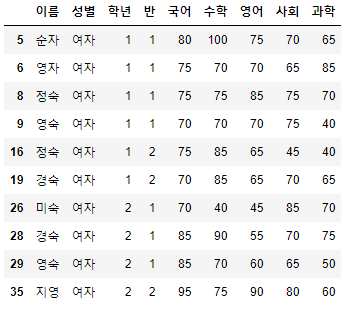
- 이를 이용하면, 조건이 아무리 많다고 할지라도 내가 원하는 대상을 구체적으로 찾아낼 수 있다.
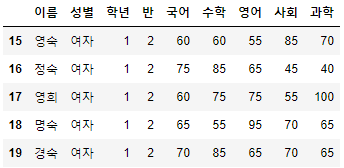
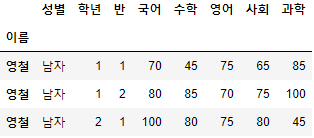
- 남은 조건인 "학년"==3, "반"==1을 추가하여 앞서 선언한 "조회할 대상"을 찾아보자.
>>> 시험점수[
(시험점수["성별"] == "여자") &
(시험점수["학년"] == 3) &
(시험점수["반"] == 1) &
(시험점수["국어"] >= 70)
]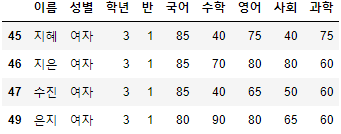
- 꽤 복잡한 조건이었음에도 Boolean Series를 사용하여 쉽게 찾아내었다.
- 2개 이상의 Boolean Series를 변수에 담지 않고 바로 조회하려면 꼭 괄호 안에 넣어주기 바란다(괄호 미사용 시 에러 발생).
지금까지 조건에 해당하는 행 조회 방법에 대해 알아보았다. 다음 포스트에서는 Pandas의 str을 이용하여, 원하는 문자열에 해당하는 행을 탐색하는 방법에 대해 다뤄보도록 하겠다.
728x90
반응형
'Python > Pandas' 카테고리의 다른 글
| Pandas-데이터 프레임, 데이터 조회하기-2. 위치와 슬라이싱 (0) | 2021.12.10 |
|---|---|
| Pandas-데이터 프레임, 데이터 조회하기-1. Index로 조회하기 (2) | 2021.12.09 |
| Pandas-데이터 프레임 컬럼명 가지고 놀기 (2) | 2021.02.24 |
| Pandas-데이터 프레임 Index 가지고 놀기 (0) | 2021.02.18 |
| Pandas-데이터 프레임의 구조와 용어 정리 (2) | 2021.02.17 |