
도수분포표(Frequency Distribution Table)
◎ 도수분포표: 수집된 데이터를 분류한 후, 각 분류에 해당하는 데이터의 빈도, 비율 등으로 정리한 표를 말한다.
앞서 통계학은 크게 기술통계학(Descriptive statistics)과 추론통계학(Inferential statistics) 이 두 가지로 나뉘며, 이 둘은 별개의 존재가 아니라, 기술통계학 > 추론통계학순으로 순차적으로 이루어진다고 하였다.
기술통계학은 말 그대로 데이터가 가지고 있는 정보를 기술(Describe)하는 것이며, 도수분포표는 데이터의 각 범주별 빈도수와 비율을 이용하여, 데이터를 설명하는 방법으로 기술통계학의 기초가 되는 기법이다.
백 마디 말보다, 한 번 실제 만들어보는 것이 가장 좋은 방법이니, 실제로 도수분포표를 만들어보고, 도수분포표가 어떻게 생겼고, 도수분포표를 이용해서 무엇을 할 수 있기에 기술통계학의 기초가 되는 것인지 알아보도록 하자.
- 도수분포표를 학습할 때, 집단을 잘 구분하는 것이 중요하다.
- 한 변수 안에는 $m$개의 데이터가 존재하는데, 이 $m$개의 데이터를 중복을 제거하면 $n$개의 데이터가 남게 된다($m$ ≥ $n$).
- 이 중복이 없는 $n$의 데이터는 한 원소 안의 집단(Group), 등급(Class) 두 가지 용어로 부를 수 있는데, 본 포스트에서는 이해하기 쉽도록, 선택된 군은 집단(Group)으로, 한 변수 안의 중복이 제거된 데이터의 군은 등급(Class)라 부르겠다.
1. Python을 사용하여, 기본적인 도수분포표를 만들어보자.
1.1. 데이터 가지고 오기
이전 포스트(참고: "통계 분석을 위한 데이터 준비")에서 생성한 데이터를 기반으로 통계 분석을 진행하도록 하겠다. 해당 데이터는 청소년건강행태조사 2019년 데이터에서 대표적인 16개 변수만 선택하고, 간단하게 결측값을 처리한 데이터다. 보다 상세한 설명이 필요한 경우 위 참고를 보길 바란다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt- 데이터 분석을 할 때, 기본적으로 사용하는 라이브러리다.
- pandas는 DataFrame을 이용해, 데이터를 관리하는 모든 과정을 굉장히 편하게 해 준다.
- numpy는 빠른 수학 연산에 필수인 라이브러리다.
- matplotlib.pyplot은 시각화에 필수인 라이브러리다.
Rawdata = pd.read_csv("Data_for_study.csv")
Rawdata- pd.read_csv("파일이름.csv"): csv 파일을 DataFrame으로 불러온다.

- 변수(Column)의 수는 총 14개이며, 55,748개의 대상이 들어가 있는 데이터가 불러와졌다.
1.2. 질적 변수 도수분포표 만들기
- 출력된 위 데이터만으로 데이터가 어떻게 생겼고, 그 안에 숨어있는 정보를 찾아내는 것은 불가능에 가깝다.
- 위 데이터를 가장 쉽게 정리하는 방법이 바로 도수분포표(Frequency distribution table)이다.
- 성별에 대한 도수분포표를 만들어보겠다.
>>> Rawdata.성별.value_counts()
1.0 29059
2.0 26689
Name: 성별, dtype: int64- value_counts(): 시리즈로 빈도표를 출력한다
- 1은 남자, 2는 여자이므로, 총 55,748명 중 남자가 29,059명, 여자가 26,689명임을 알 수 있다.
- 비율을 추가해보자.
성별_빈도표 = pd.DataFrame(Rawdata.성별.value_counts())
성별_빈도표.columns = ["freq"]
성별_빈도표["ratio"] = np.round(성별_빈도표.freq/sum(성별_빈도표.freq),2)
성별_빈도표- pd.DataFrame.columns: DataFrame의 컬럼명을 조작한다.
- np.round(array, n): array의 값들을 n의 자리에서 반올림한다.

- 대한민국의 중, 고등학생을 모집단으로 하는 데이터의 표본집단에서 남성이 차지하는 비중은 52%, 여성이 차지하는 비중은 48% 임을 쉽게 알 수 있다.
1.3. 양적 변수 도수분포표 만들기
- 이번엔 동일한 방법으로 양적 변수인 키에 대해 도수분포표를 만들어보겠다.
키_빈도표 = pd.DataFrame(Rawdata.키.value_counts())
키_빈도표.columns = ["freq"]
키_빈도표["ratio"] = np.round(키_빈도표.freq/sum(키_빈도표.freq),2)
키_빈도표
- 데이터를 보기 쉽게 만드려고 했는데, 여전히 보기가 어렵다.
- 키와 같은 양적 변수는 들어갈 수 있는 값이 매우 다양하여 등급(Class)이 많기 때문에 이를 바로 도수분포표로 만들면, 여전히 보기 어렵다. 이를 범주화(Categorization)시켜 단순화해보자.
>>> 키_array = Rawdata.키.to_numpy()
>>> print("min:", 키_array.min())
>>> print("max:", 키_array.max())
min: 136.0
max: 196.0- DataFrame.column.to_numpy(): DataFrame의 특정 열 column을 numpy의 array로 변환시킨다.
- array.min(): 배열의 최솟값
- array.max(): 배열의 최댓값
- 최솟값이 136.0cm, 최댓값이 196.0cm이므로, "140 이하", "140~150", "150~160", "160~170", "170~180", "180~190", "190 이상"으로 데이터를 범주화해보자.
키_범주 = np.where(키_array<=140, "140 이하",
np.where((키_array>140) & (키_array<=150), "140~150",
np.where((키_array>150) & (키_array<=160), "150~160",
np.where((키_array>160) & (키_array<=170), "160~170",
np.where((키_array>170) & (키_array<=180), "170~180",
np.where((키_array>180) & (키_array<=190), "180~190", "190 이상"))))))
키_도수분포표 = pd.DataFrame(pd.Series(키_범주).value_counts(), columns=["freq"])
키_도수분포표.sort_index(inplace=True)
키_도수분포표- np.where(조건, a, b): 조건에 해당하는 경우 a로 해당하지 않는 경우 b를 반환
- DataFrame.sort_index(): index로 정렬함.

- 비율을 추가해보자.
키_도수분포표["ratio"] = np.round(키_도수분포표.freq / sum(키_도수분포표.freq), 2)
키_도수분포표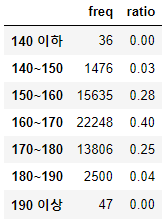
1.4. 누적 빈도, 누적 비율 추가
- 이번에는 빈도(freq)와 비율(ratio)을 첫 집단부터 차근차근 누적시키는 누적 빈도(Cumulative frequency)와 누적 비율(Cumulative ratio)을 보자.
키_도수분포표["cum_freq"] = np.cumsum(키_도수분포표.freq)
키_도수분포표["cum_ratio"] = np.cumsum(키_도수분포표.ratio)
키_도수분포표
- np.cumsum(array): array를 주어진 순서대로 누적합
2. 도수분포표의 개념 정리

위에서 만든 도수분포표를 기반으로, 도수분포표의 개념을 정리해 보자.
- 질적 변수는 일반적으로 구성하고 있는 등급(Class)의 수가 그리 많지 않기 때문에 바로 도수분포표를 생성해도 가시성이 높다. 물론, 질적 변수 역시 구성하고 있는 등급(Class)의 수가 매우 많다면, 재 범주화하여, 그 등급(Class)의 수를 줄여야한다.
예) 읍, 면, 동 단위로 지역명이 들어가 있는 변수는, 이를 시 단위로 재범주화 할 수 있음 - 양적 변수로 구성된 데이터는 중복을 제거하더라도, 구성하고 있는 등급(Class)가 매우 많아 도수분포표로 만들더라도, 가시성이 매우 떨어지므로, 변수의 성격에 따라 그 변수의 데이터 분포를 가장 잘 보여줄 수 있는 구간으로 데이터를 범주화시켜 도수분포표를 만든다.
- 각 등급(Class)에서 관찰된 객체의 수를 빈도수 또는 도수(Frequency)라고 하며, $f$로 나타낸다.
- 각 변수를 구성하는 데이터의 빈도, 비율 등을 파악하기 때문에 이 과정을 빈도 분석(Frequency Analysis)라 하며, 출력된 도수분포표를 빈도표라고도 한다.
- 빈도 분석을 통해 생성하는 도수분포표 자체도 통계 분석에서 목적이 될 정도로 중요하지만, 일반적으로는 데이터의 형태를 파악하는 기초 자료로 생성하는 경우가 많다.
- 누적 빈도(Cumulative frequency):
어떤 등급(Class)에 해당하는 빈도를 포함해, 그 이하 또는 그 이상에 있는 모든 빈도를 합친 것 - 누적 빈도를 사용하게 되면, 특정 등급(Class)에 있는 대상이 전체 데이터에서 차지하는 위치를 알 수 있다. 위 도수분포표를 보면, 중·고등학생 전체 집단에서 키가 170~180에 있는 집단이 전체 대상에서 96%에 위치하고 있음을 알 수 있다.
- 누적 빈도는 질적 변수에 대해서는 사용하지 않는 것을 추천한다. 양적 변수는 데이터에 순서가 있고, 값과 값 사이의 간격이 일정하므로, 누적 빈도를 통해 대상 등급(Class)의 객관적인 위치를 알 수 있다. 그러나, 명목 변수는 순서가 없고, 순서가 존재하는 서열 변수라 할지라도, 간격이 일정하지 않기 때문에, 대상 등급(Class)이 전체 등급의 어디에 위치하는지 알 수 없다.
3. 상대 빈도(Relative frequency) = 비율(Ratio)
- 위에서 생성한 키에 대한 도수분포표는 표본 집단인 중·고등학교에 재학 중인 청소년을 대상으로 한 것이다.
>>> print("만연령 min:", Rawdata.연령.min())
>>> print("만연령 max:", Rawdata.연령.max())
만연령 min: 12.0
만연령 max: 18.0- 대상 집단의 연령 범위는 만 12세~18세이며, 성별이 남, 녀 두 가지가 들어 있기 때문에 단순하게 위 도수분포표를 보고, 해당 집단의 특성을 파악한다면 아래와 같은 정보 전달의 오류가 발생할 위험이 있다.
- 키 170cm는 12세 여성이란 집단에서는 굉장히 큰 키이지만, 18세 남성이란 집단에서는 그리 큰 키가 아니다. 위 도수분포표는 만 12세 ~ 18세 중·고등학생 표본집단을 대상으로 하였기 때문에 위 도수분포표만으로는 둘을 같게 볼 여지가 있다.
(물론, 대상을 만 12~18세라고 미리 설명해놨다면, 이런 문제는 발생하지 않는다.) - 보다 정밀한 데이터 파악을 위해선, 연구자의 의도를 가장 잘 보여줄 수 있는 도수분포표(빈도표) 생성이 필요하다.
- 이번에는 만 16세인 사람으로 한정하여, 남성과 여성의 키를 보도록 하자.
def cat_height(array):
cat_array = np.where(array<=140, "140 이하",
np.where((array>140) & (array<=150), "140~150",
np.where((array>150) & (array<=160), "150~160",
np.where((array>160) & (array<=170), "160~170",
np.where((array>170) & (array<=180), "170~180",
np.where((array>180) & (array<=190), "180~190", "190 이상"))))))
return cat_array
def Freq_table(array):
freq_table = pd.DataFrame(pd.Series(array).value_counts(), columns=["freq"])
freq_table.sort_index(inplace = True)
freq_table["ratio"] = freq_table.freq / sum(freq_table.freq)
freq_table["cum_freq"] = np.cumsum(freq_table.freq)
freq_table["cum_ratio"] = np.round(np.cumsum(freq_table.ratio), 2)
# 반올림 및 총합 생성
freq_table.loc["총합"] = [sum(freq_table.freq), sum(freq_table.ratio), "", ""]
freq_table["ratio"] = np.round(freq_table["ratio"], 2)
return freq_table- 위에서 만들었던, 양적 변수의 범주화(키)와 도수분포표를 출력하는 코드들을 정리하여 별 개의 함수로 만들어놓았으며, 추가로 총합이 계산되도록 코드를 추가하였다.
- 이러한 코드 함수화를 통해, 코드의 재활용성, 가시성, 유지보수의 용이함 등의 이점을 얻을 수 있다.
남자_16세_키 = Rawdata[(Rawdata["연령"] == 16) & (Rawdata["성별"] == 1.0)]["키"].to_numpy()
여자_16세_키 = Rawdata[(Rawdata["연령"] == 16) & (Rawdata["성별"] == 2.0)]["키"].to_numpy()Freq_table(cat_height(남자_16세_키))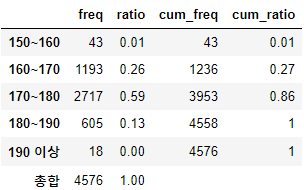
Freq_table(cat_height(여자_16세_키))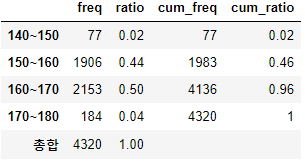
- 상대 빈도(relative frequency)는 비율(ratio)과 동일하다.
- 상대 빈도 즉, 비율을 사용하면, 서로 다른 집단에 대하여, 각 범주별 차지하는 비중을 알 수 있게 되므로, 서로 다른 집단을 비교하는데 매우 유용하다.
- 위 표를 하나로 합쳐보자.
# 성별에 따른 변수명 구분을 위해 column 앞에 특정 문자를 붙여줌
M_DF = Freq_table(cat_height(남자_16세_키))
M_DF = M_DF.add_prefix("M_")
F_DF = Freq_table(cat_height(여자_16세_키))
F_DF = F_DF.add_prefix("F_")
# 병합 및, 결측값은 0으로 채운다.
T_DF = pd.concat([M_DF, F_DF], axis=1).sort_index()
T_DF.fillna(0, inplace=True)
T_DF
- 위 표를 보면, 남성(M)과 여성(F)의 도수분포표를 비율(ratio)을 이용해서, 두 집단의 규모 차이를 무시하고 비교할 수 있다.
- 만 16세 남성의 59%는 170~180cm에 존재하며, 만 16세 여성의 50%는 160~170cm에 존재한다는 것을 알 수 있다.
지금까지 기술통계학의 가장 기초가 되는 빈도 분석(Frequency analysis)의 도수분포표(Frequency distribution table)에 대해 알아보았다.
빈도 분석은 모든 데이터 분석의 기반이 되며, 데이터의 분포를 파악하고, 연구자의 의도를 대상에게 전달하는 데 있어, 작성하기도 쉽고, 이해하기도 쉬우므로, 강력한 영향을 미친다.
변수의 수가 무수히 많고, 하나하나의 변수를 구성하는 집단 역시 매우 많기 때문에, 모든 빈도를 보여주는 것보다, 연구자의 의도가 가장 잘 담겨 있는 대상에 대한 도수분포표를 보여주는 것이 매우 중요하며, 도수분포표를 생성하기 전에 자신이 전달하고자 하는 바가 무엇인지? 자신이 전달하고자 하는 바에서 대상 집단이 어떻게 되는지를 명확히 하도록 하자.
'Python으로 하는 기초통계학 > 기본 개념' 카테고리의 다른 글
| 중심경향치(1) - 최빈값, 중앙값 (0) | 2021.03.03 |
|---|---|
| 도수분포표와 시각화 (0) | 2021.03.02 |
| 통계 분석을 위한 데이터 준비 (0) | 2021.03.01 |
| 변수(Variable) (0) | 2021.03.01 |
| 통계학이란? (0) | 2021.02.26 |