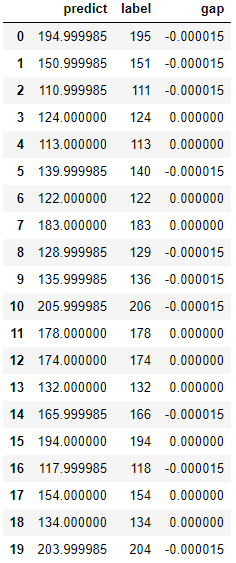
패턴을 거의 완벽하게 찾아내었으며, 정확도(Accuracy) 역시 0.000010789(e-05는 $10^{-5}$을 하라는 소리다.)로 거의 0에 근사하게 나왔다.
2. 정리
위 결과를 보면, 아무리 단순한 패턴이라 할지라도, 그 데이터 셋의 형태를 반영하지 못한다면, 정확히 그 결과를 찾아내지 못할 수 있다는 것을 알 수 있다.
인공지능은 흔히들 생각하는 빅데이터를 넣으면, 그 안에 숨어 있는 패턴이 자동으로 나오는 마법의 상자가 아니라, 연구자가 그 데이터에 대한 이해를 가지고 여러 시도를 해, 제대로 된 설계를 해야만 내가 원하는 제대로 된 패턴을 찾아낼 수 있는 도구다.
그러나, 실전에서는 지금처럼 우리가 이미 패턴을 알고 있는 경우는 없기 때문에 다양한 도구를 이용해서, 데이터를 파악하고, 적절한 하이퍼 파라미터를 찾아낸다.
넣을 수 있는 모든 하이퍼 파라미터를 다 넣어보는 "그리드 서치(Greed search)"나 랜덤 한 값을 넣어보고 지정한 횟수만큼 평가하는 "랜덤 서치(Random Search)", 순차적으로 값을 넣어보고, 더 좋은 해들의 조합에 대해서 찾아가는 "베이지안 옵티마이제이션(Bayesian Optimization)" 등 다양한 방법이 있다.
같은 알고리즘이라 할지라도, 데이터를 어떻게 전처리하느냐, 어떤 활성화 함수를 쓰느냐, 손실 함수를 무엇을 쓰느냐 등과 같은 다양한 요인으로 인해 다른 결과가 나올 수 있으므로, 경험을 많이 쌓아보자.
이전 포스트에서 만든 모델의 결과는 그리 나쁘진 않았으나, 패턴이 아주 단순함에도 쉽게 결과를 찾아내지 못했고, 학습에 자원 낭비도 많이 되었다.
왜 그럴까?
특성 스케일 조정
특성 스케일 조정을 보다 쉽게 말해보면, 표준화라고 할 수 있다.
이번에 학습한 대상은 변수(다른 정보에 대한 벡터 성분)가 1개밖에 없어서 그나마 나았으나, 만약, 키와 몸무게가 변수로 주어져 벡터의 원소로 들어갔다고 생각해보자.
키나 몸무게는 그 자리 수가 너무 큰 값이다 보니, 파라미터 역시 그 값의 변화가 지나치게 커지게 되고, 그로 인해 제대로 된 결과를 찾지 못할 수 있다.
또한 키와 몸무게는 그 단위마저도 크게 다르다 보니, 키에서 160이 몸무게에서의 160과 같다고 볼 수 있다. 그러나 모두가 알다시피 키 160은 대한민국 남녀 성인 키 평균에 못 미치는 값이며, 몸무게 160은 심각한 수준의 비만이다. 전혀 다른 값임에도 이를 같게 볼 위험이 있다는 것이다.
이러한 표준화가 미치는 영향은 손실 함수에서 보다 이해하기 쉽게 볼 수 있는데, 이로 인해 발생하는 문제가 바로 경사 하강법의 zigzag 문제다.
$w_1$과 $w_2$의 스케일 크기가 동일하다면(값의 범위가 동일), 손실 함수가 보다 쉽게 최적해에서 수렴할 수 있다.
$w_1$과 $w_2$의 스케일 크기가 많이 다르다면, 손실 함수는 쉽게 최적해에 수렴하지 못한다.
1. 특성 스케일 조정 방법
특성 스케일 조정 방법은 크게 2가지가 있다.
첫 번째는 특성 스케일 범위 조정이고, 두 번째는 표준 정규화를 하는 것이다.
A. 특성 스케일 범위 조정
특성 스케일 범위 조정은 말 그대로, 값의 범위를 조정하는 것이다.
바꿀 범위는 [0, 1]이다.
이 방법에는 최솟값과 최댓값이 사용되므로 "최소-최대 스케일 변환(min-max scaling)"이라고도 한다.
범위 축소에 흔히들 사용되는 해당 방법은, 가장 쉽게 표준화하는 방법이지만, 값이 지나치게 축소되어 존재하던 이상치가 사라져 버릴 수 있다.
특히나, 이상치가 존재한다면, 이상치보다 작은 값들을 지나치게 좁은 공간에 모아버리게 된다.
B. 표준 정규분포
표준 정규분포는 평균 = 0, 표준편차 = 1로 바꾸는 가장 대표적인 표준화 방법이다.
공식은 다음과 같다.
$$ x_{std} = \frac{x_i - \mu_x}{\sigma_x} $$
위 공식에서 $x_i$는 표준화 대상 array다.
표준 정규분포로 만들게 되면, 평균 = 0, 표준편차 = 1로 값이 축소되게 되지만, 여전히 이상치의 존재가 남아 있기 때문에 개인적으론 표준 정규분포로 만드는 것을 추천한다.
특성 스케일 조정에서 가장 중요한 것은, 조정의 기준이 되는 최솟값, 최댓값, 평균, 표준편차는 Train Dataset의 값이라는 것이다. 해당 방법 사용 시, Train Dataset을 기준으로 하지 않는다면, Test Dataset의 값이 Train Dataset과 같아져 버릴 수 있다.
2. 표준 정규분포를 이용해서 특성 스케일을 조정해보자.
# Import Module
import pandas as pd
import numpy as np
from tensorflow import keras
from tensorflow.keras.layers import Dense
# Dataset Setting
def f(x):
return x + 10
# Data set 생성
np.random.seed(1234) # 동일한 난수가 나오도록 Seed를 고정한다.
X_train = np.random.randint(0, 100, (100, 1))
X_test = np.random.randint(100, 200, (20, 1))
# Label 생성
y_train = f(X_train)
y_test = f(X_test)
# Model Setting
model = keras.Sequential()
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='linear'))
# Compile: 학습 셋팅
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=opt, loss = 'mse')
지난 포스트에서 데이터 셋에 대해 간략히 설명해보았다. 이번 포스트부터 본격적으로 텐서플로우를 사용해서, 내가 찾아내고 싶은 알고리즘을 찾아내 보자.
학습 목표
분석가가 알고 있는 패턴으로 데이터를 생성하고, 그 패턴을 찾아내는 모델을 만들어보자.
Input이 1개, Output이 1개인 연속형 데이터에서 패턴을 찾아보자.
1. 데이터 셋 생성
패턴: $f(x) = x + 10$
# Module 설정
import pandas as pd
import numpy as np
from tensorflow import keras
from tensorflow.keras.layers import Dense
def f(x):
return x + 10
# Data set 생성
np.random.seed(1234) # 동일한 난수가 나오도록 Seed를 고정한다.
X_train = np.random.randint(0, 100, (100, 1))
X_test = np.random.randint(100, 200, (20, 1))
# Label 생성
y_train = f(X_train)
y_test = f(X_test)
데이터 셋 생성 코드의 함수 설명
np.random.seed(int): 난수(랜덤 한 데이터) 생성 시, 그 값은 생성할 때마다 바뀌게 된다. 데이터 셋이 바뀌게 되면, 일관된 결과를 얻기가 힘들어, 제대로 된 비교가 힘들어지므로, 난수를 생성하는 방식을 고정시킨다. 이를 시드 결정(Set seed)이라 하며, 숫자는 아무 숫자나 넣어도 상관없다.
np.random.randint(시작 int, 끝 int, shape): 시작 숫자(포함)부터 끝 숫자(미포함)까지 shape의 형태대로 array를 생성한다.
데이터 셋 생성 코드 설명
Train set은 0~100까지의 숫자를 랜덤으로 (100, 1)의 형태로 추출하였다.
Test set은 100~200까지의 숫자로 랜덤으로 (20, 1)의 형태로 추출했다. 여기서 값은 Train set과 절대 겹쳐선 안된다.
Label 데이터인 y_train과 y_test는 위에서 설정된 함수 f(x)에 의해 결정되었다.
기본적으로 Tensorflow에 Input 되고 Output 되는 데이터의 형태는 이렇다고 생각하자.
2. 모델 생성하기
tensorflow를 사용해 모델을 생성하는 경우, tensorflow가 아닌 keras를 사용하게 된다.
위에서 tensorflow의 기능을 가져올 때, 아래와 같은 코드로 가져왔다.
from tensorflow import keras
이는, tensorflow라는 프레임워크에서 keras라는 모듈을 가지고 온다는 의미이다.
keras는 추후 설명하게 될지도 모르지만, 모델 생성 및 학습에 있어 직관적으로 코드를 짤 수 있게 해 주므로, 쉽게 tensorflow를 사용할 수 있게 해 준다.
물론, keras와 tensorflow는 태생적으로 서로 다른 프레임워크이므로, 이 둘이 따로 에러를 일으켜, 에러 해결을 어렵게 한다는 단점이 있긴 하지만, 그걸 감안하고 쓸만한 가치가 있다.
model = keras.Sequential()
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='linear'))
keras를 사용해서 모델을 만드는 방법은 크게 2가지가 있다.
하나는 위 같이 add를 이용해서 layer를 하나씩 추가해 가는 방법이 있고
model = keras.Sequential([
Dense(16, activation='relu'),
Dense(1, activation='linear')
])
이렇게 keras.Sequential([]) 안에 층(layer)을 직접 넣는 방법이 있다.
처음 방법처럼 add를 사용하는 방법은 API 사용 방법이고, 아래와 같이 층을 Sequential([])에 직접 넣는 방식은 Layer 인스턴스를 생성자에게 넘겨주는 방법이라 하는데, 전자인 API를 사용하는 방법을 개인적으로 추천한다.
그 이유는 다중-아웃풋 모델, 비순환 유향 그래프, 레이어 공유 모델 같이 복잡한 모델 정의 시, 매우 유리하기 때문으로, 이는 나중에 다루겠으나, 이 것이 Tensorflow의 장점이다.
모델 생성 코드 함수 설명
keras.Sequential(): 순차 모델이라 하며, 레이어를 선형으로 연결해 구성한다. 일반적으로 사용하는 모델로 하나의 텐서가 입력되고 출력되는 단일 입력, 단일 출력에 사용된다. 다중 입력, 다중 출력을 하는 경우나, 레이어를 공유하는 등의 경우엔 사용하지 않는다.
model.add(layer): layer를 model에 층으로 쌓는다. 즉, 위 모델은 2개의 층을 가진 모델이다.
Dense(노드 수, 활성화 함수): 완전 연결 계층으로, 전, 후 층을 완전히 연결해주는 Layer다. 가장 일반적으로 사용되는 Layer다.
모델 생성 코드 설명
해당 모델은 Input 되는 tensor도 1개 Output 되는 tensor도 1개이므로, Sequential()로 모델을 구성했다.
은닉층에는 일반적으로 ReLU 활성화 함수가 사용된다고 하니, ReLU를 넣었다.
출력층에는 출력 결과가 입력 값과 같은 노드 1개이므로, 노드 1개로 출력층을 만들었다.
일반적으로 Node의 수를 $2^n$으로 해야 한다고 하지만, 크게 상관없다는 말이 있으므로, 굳이 신경 쓰지 않아도 된다. 처음엔 자기가 넣고 싶은 값을 넣다가, 성능이 안 나온다 싶으면 바꿔보는 수준이니 크게 신경 쓰지 말자.
사용된 활성화 함수(activation)는 일반적으로 은닉층에 ReLU를 넣고, 연속형 데이터이므로 출력층에 Linear를 넣어보았다.