
이전 포스트에서 모델을 생성해보고, 생성된 모델의 정보를 살펴보았다. 이번 포스트에서는 모델을 컴파일에 대해 학습해보도록 하겠다.
모델 컴파일
0. 이전 코드 정리
# Import Module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout, Flatten)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# Dataset 준비
(train_images, train_labels), (test_images, test_labels)= load_data()
# 무작위로 샘플 추출
np.random.seed(1234)
index_list = np.arange(0, len(train_labels))
valid_index = np.random.choice(index_list, size = 5000, replace = False)
# 검증셋 추출
valid_images = train_images[valid_index]
valid_labels = train_labels[valid_index]
# 학습셋에서 검증셋 제외
train_index = set(index_list) - set(valid_index)
train_images = train_images[list(train_index)]
train_labels = train_labels[list(train_index)]
# min-max scaling
min_key = np.min(train_images)
max_key = np.max(train_images)
train_images = (train_images - min_key)/(max_key - min_key)
valid_images = (valid_images - min_key)/(max_key - min_key)
test_images = (test_images - min_key)/(max_key - min_key)# 모델 생성
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28], name="Flatten"))
model.add(Dense(300, activation="relu", name="Hidden1"))
model.add(Dense(200, activation="relu", name="Hidden2"))
model.add(Dense(100, activation="relu", name="Hidden3"))
model.add(Dense(10, activation="softmax", name="Output"))
1. 모델 컴파일
# 모델 컴파일
opt = keras.optimizers.Adam(learning_rate=0.005)
model.compile(optimizer = opt,
loss = "sparse_categorical_crossentropy",
metrics = ["accuracy"])- 모델을 어떤 방식으로 학습시킬지 결정하는 과정이다.
- 모델 컴파일에서 지정하는 주요 항목은 최적화 방법인 옵티마이저(Optimizer)와 손실 함수(loss)이다.
- 추가로, 훈련과 평가 시 계산할 지표를 추가로 지정할 수 있다(metrics).
2. Optimizer
- 최적화 방법인 Optimizer는 경사 하강법(GD)을 어떤 방법으로 사용할지를 정한다고 생각하면 된다.
- Optimizer를 정하는 이유는 Optimizer 방법을 무엇을 선택하느냐에 따라 최적해를 찾아가는 속도가 크게 달라진다.
- 경사 하강법(GD)은 기본적으로 4가지 문제가 존재하며, 이는 다음과 같다.
(좀 더 자세히 알고 싶은 사람은 다음 포스팅: "머신러닝-6.1. 최적화(2)-경사하강법의 한계점"을 참고하기 바란다.)
- 데이터가 많아질수록 계산량이 증가함
- Local minimum 문제
- Plateau 문제
- Zigzag 문제
- 위 문제들을 간단하게 말하면, 경사 하강법이 가진 구조적 단점으로 인해, 최적해를 제대로 찾아가지 못하거나, 찾는 속도가 늦어진다는 것이다.
- 이를 해결하기 위해선 데이터셋에 맞는 Optimizer를 사용해야 하며, 단순하게 가장 많이 사용하는 Optimizer가 Adam이므로, Adam을 사용하는 것은 그다지 추천할 수 없는 방법이다.
# Optimizer는
model.compile(optimizer = "Adam",
loss = "sparse_categorical_crossentropy",
metrics = ["accuracy"])- 위 방법으로 Optimizer를 하게 되면, 코드는 단순하지만, 학습률, Momentum과 같은 Optimizer 고유의 하이퍼 파라미터를 수정할 수 없다.
# 모델 컴파일
opt = keras.optimizers.Adam(learning_rate=0.005)
model.compile(optimizer = opt,
loss = "sparse_categorical_crossentropy",
metrics = ["accuracy"])- 위 방법으로 Optimizer를 잡아줘야, 각종 하이퍼 파라미터를 수정할 수 있다.
- keras.optimizers. 뒤에 원하는 optimizer를 넣으면 된다.
3. Optimizer의 종류
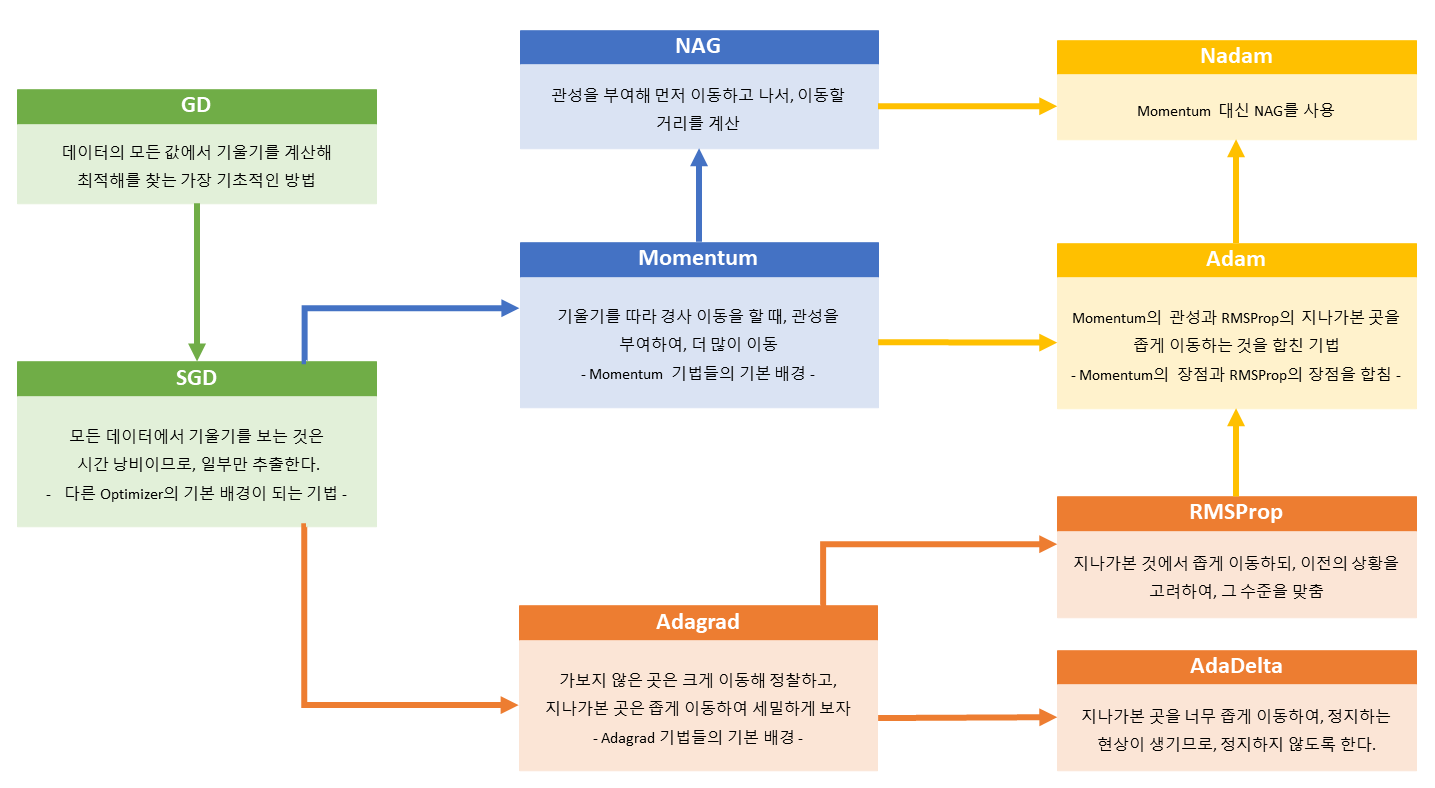
- Optimizer는 기본적으로 SGD를 기반으로 하므로, 확률적 추출을 통해 경사 하강법을 시행한다.
- Optimizer는 크게 Momentum 방식(관성 부여)과 Adagrad 방식(상황에 따른 이동 거리 조정)으로 나뉜다.
- Momentum 방식과 Adagrad 방식을 하나로 합친 방법이 Adam과 Nadam이다.
- 다른 Optimizer를 사용함으로 인해 최적해를 찾아가는 방법이 달라지게 되고, 그로 인해 학습 속도가 바뀌게 된다.
- Local minimum 문제는 무작위 가중치 초기화로 인해 발생할 가능성이 매우 낮다.
- 단순하게 Adam만 고집하지 말고, 여러 Optimizer를 사용하길 바란다.
- Optimizer와 경사하강법에 대한 상세한 설명을 보고자 한다면, 다음 포스트를 참고하기 바란다.
- 참고: "머신러닝-6.0. 최적화(1)-손실함수와 경사하강법"
Optimizer별 최적해 수렴 속도 차이
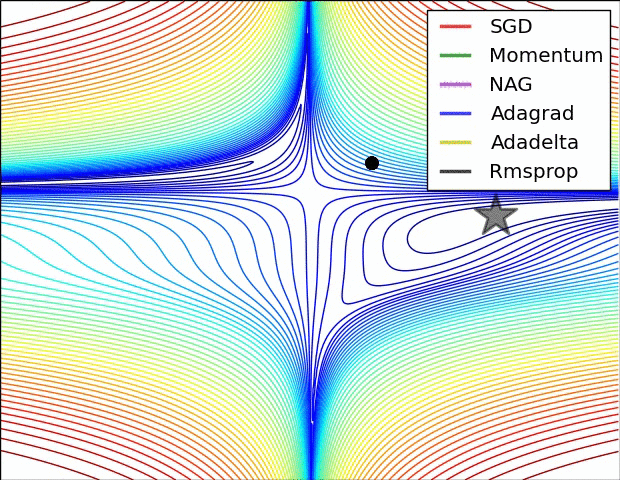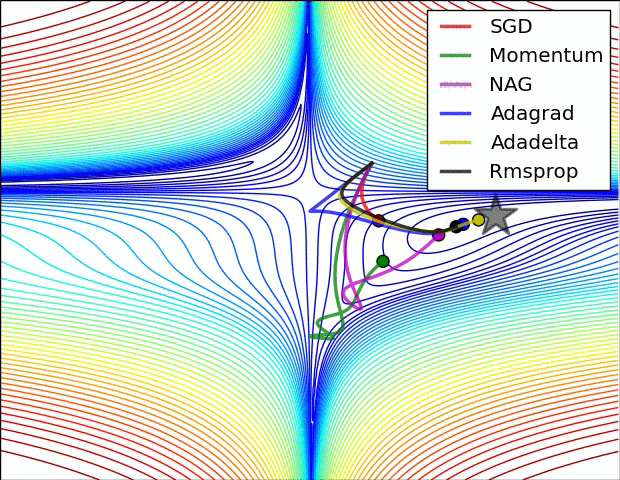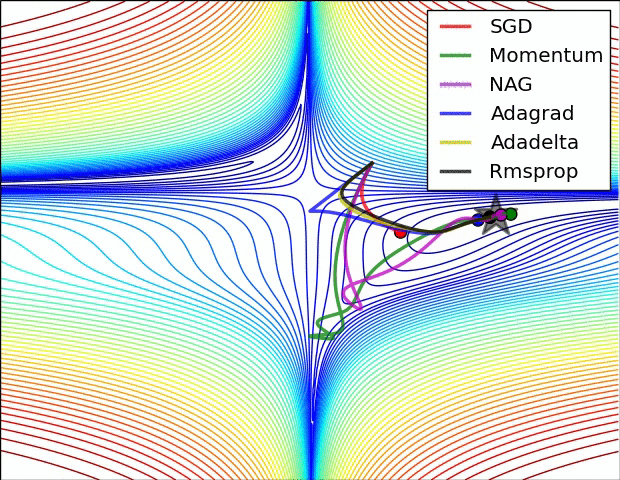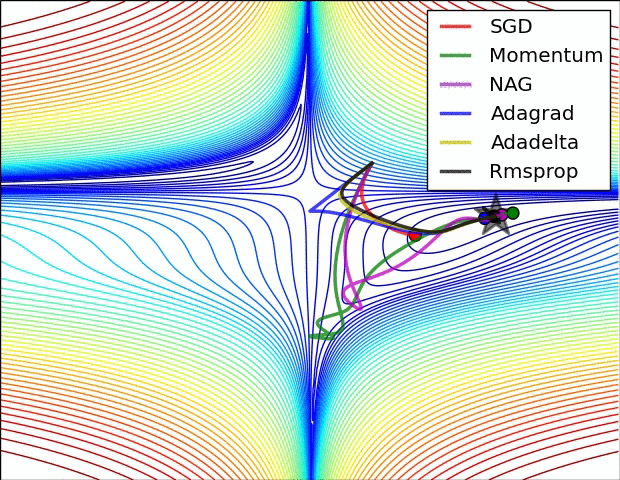
- 별이 최적해라고 할 때, 각종 Optimizer가 최적해를 찾아가는 방식을 시각화한 것이다.
- 해가 n개이므로, 파라미터는 평면이 아니라 입체이며, 이 입체를 이해하기 쉽도록 2차원 등고선으로 그린 것이다.
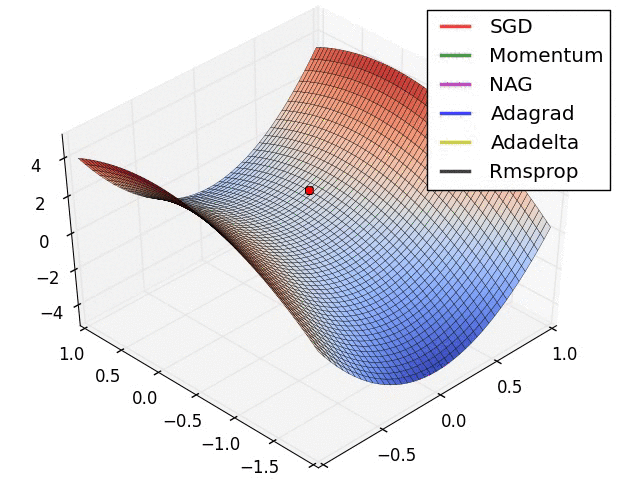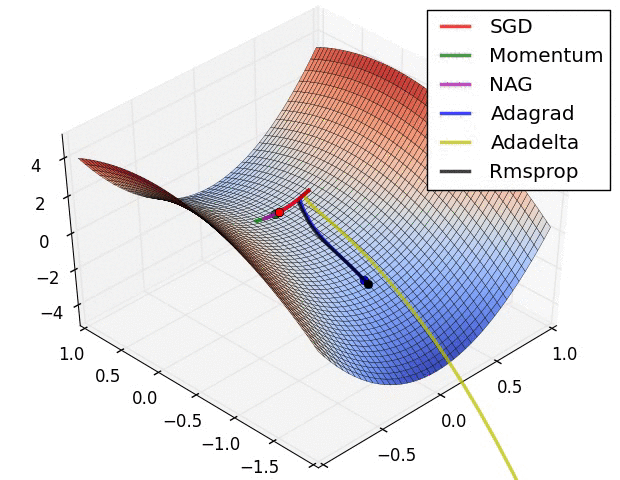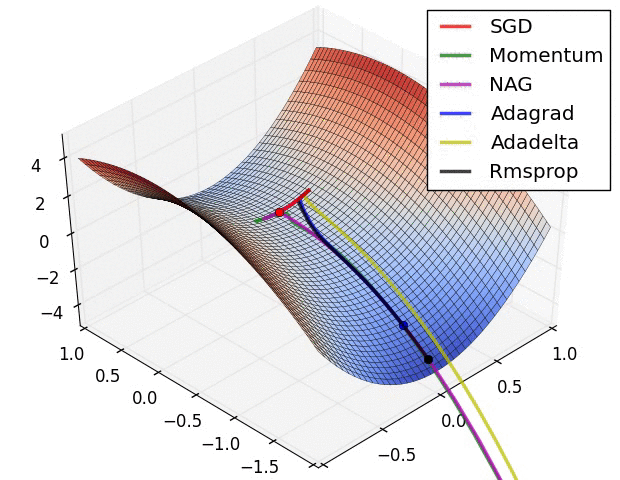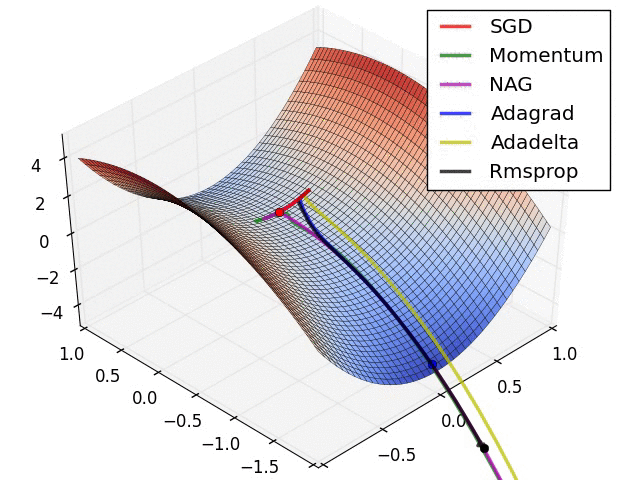
- 말안장 그림이라 하여, 3차원으로 최적해를 찾아가는 과정을 그린 것이다.
- SGD는 지역 최솟값(Local minimum)에 빠져 최적해를 찾아가지 못하였다.
- 위 두 그림의 출처는 다음과 같으며, 보다 자세한 설명을 보고 싶은 경우 해당 사이트를 참고하기 바란다.
- ruder.io/optimizing-gradient-descent/
An overview of gradient descent optimization algorithms
Gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. This post explores how many of the most popular gradient-based optimization algorithms such as Momentum, Adagrad,
ruder.io
4. loss
- 손실 함수는 데이터셋과 라벨 데이터의 생김새에 따라 사용하는 방법이 달라진다.
- 기본적으로 연속형 데이터를 대상으로는 제곱 오차(SE)에서 파생된 기법을 사용하며, 범주형 데이터를 대상으로는 크로스 엔트로피 오차(CEE)에서 파생된 기법을 사용한다.
- 클래스의 수나 Label의 형태에 따라 사용하는 방법이 조금씩 달라진다.
- 가장 많이 사용되는 손실 함수의 사용 예는 다음과 같다.
| 데이터 형태 | Label의 형태 | 손실 함수 | |
| 범주형 | 클래스 2개 | binary_crossentropy | |
| 클래스 3개 이상 |
원-핫 벡터 | categorical_crossentropy | |
| 단순 범주형 | sparse_categorical_crossentropy | ||
| 연속형 | mean_squared_error (=mse) mean_squared_logarithmic_error (=msle) |
||
- 위 표는 기본적인 손실 함수에 대한 것이므로, 성능이 나오지 않는다면, 다른 손실 함수를 사용할 필요가 있다.
- 위 손실함수에 대한 상세한 설명을 보고자 한다면, 아래 포스팅을 참고하기 바란다.
- 참고: "머신러닝-5.0. 손실함수(1)-제곱오차(SE)와 오차제곱합(SSE)
- 모든 손실 함수의 목록은 아래 주소에 있으므로 필요시, 참고하기 바란다.
- www.tensorflow.org/api_docs/python/tf/keras/losses
Module: tf.keras.losses | TensorFlow Core v2.4.1
Built-in loss functions.
www.tensorflow.org
5. metrics
- 평가 기준으로 모델의 학습에는 영향을 미치지 않으나, 학습 중에 제대로 학습되고 있는지를 볼 수 있다.
- metrics에 무엇을 넣느냐에 따라 학습 시, 히스토리에 나오는 출력 Log가 달라지게 된다.
- 일반적으로 accuracy 즉, 정확도가 사용된다.
- 이 역시 데이터 셋에 따라 바뀌며, 손실 함수와 유사한 것을 선택하면 된다.
- metrics에 사용하는 하이퍼 파라미터는 아래 사이트를 참고하기 바란다.
- keras.io/api/metrics/
Keras documentation: Metrics
Metrics A metric is a function that is used to judge the performance of your model. Metric functions are similar to loss functions, except that the results from evaluating a metric are not used when training the model. Note that you may use any loss functi
keras.io
지금까지 Compile을 하는 방법에 대해 알아보았다. Compile은 일반적으로 사용하는 기법을 사용하여도 큰 차이를 느끼지 못할 수도 있으나, 제대로 모델을 학습시키기 위해선 데이터의 형태에 맞는 하이퍼 파라미터를 잡아주는 것이 좋다.
다음 포스트에서는 모델을 실제로 학습시켜보고, 그 Log를 시각화하여 최적의 Epochs을 선택하는 방법에 대해 학습해보겠다.
'Machine Learning > TensorFlow' 카테고리의 다른 글
| Tensorflow-3.6. 이미지 분류 모델(6)-학습과정 확인 (0) | 2021.02.17 |
|---|---|
| Tensorflow-3.5. 이미지 분류 모델(5)-모델 학습 (0) | 2021.02.17 |
| Tensorflow-3.3. 이미지 분류 모델(3)-모델 생성 (0) | 2021.02.16 |
| Tensorflow-3.2. 이미지 분류 모델(2)-검증 셋(Validation set) (0) | 2021.02.16 |
| Tensorflow-3.1. 이미지 분류 모델(1)-MNIST 데이터셋 (0) | 2021.02.16 |





