
지금까지 계단 함수, 선형 함수, 시그모이드 함수, 소프트맥스 함수, 하이퍼볼릭 탄젠트 함수에 대해 다뤄보았다. 이들은 은닉층에서 사용해서는 안되거나, 사용할 수 있더라도 제한적으로 사용해야 하는 활성화 함수들이었다. 이번 포스트에서는 은닉층에서 많이 사용되는 렐루 함수에 대해 학습해 보겠다.
렐루 함수(Rectified Linear Unit, ReLU)
- 렐루 함수는 딥러닝 역사에 있어 한 획을 그은 활성화 함수인데, 렐루 함수가 등장하기 이전엔 시그모이드 함수를 활성화 함수로 사용해서 딥러닝을 수행했다.
- 그러나, 이전 포스트에서 언급했듯 시그모이드 함수는 출력하는 값의 범위가 0에서 1사이므로, 레이어를 거치면 거칠수록 값이 현저하게 작아지게 되어 기울기 소실(Vanishing gradient) 현상이 발생한다고 하였다.
gooopy.tistory.com/52?category=824281
머신러닝-3.1. 활성화함수(2)-시그모이드 함수
지난 포스트에서 퍼셉트론의 가장 기본이 되는 활성화 함수인 계단 함수(Step Function)를 학습하였으며, 선형 함수(Linear Function)의 한계점에 대해서도 학습해보았다. 선형 함수는 층을 쌓는 것이
gooopy.tistory.com
- 이 문제는 1986년부터 2006년까지 해결되지 않았으나, 제프리 힌튼 교수가 제안한 렐루 함수로 인해, 시그모이드의 기울기 소실 문제가 해결되게 되었다.
- 렐루 함수는 우리 말로, 정류된 선형 함수라고 하는데, 간단하게 말해서 +/-가 반복되는 신호에서 -흐름을 차단한다는 의미다.
- 렐루 함수는 은닉층에서 굉장히 많이 사용되는데, 별생각 없이 다층 신경망을 쌓고, 은닉층에 어떤 활성화 함수를 써야 할지 모르겠다 싶으면, 그냥 렐루 함수를 쓰라고 할 정도로, 아주 많이 사용되는 활성화 함수이다(물론 신경망을 의도를 가지고 써보고 싶다면, 그래선 안된다.).
1. 렐루 함수의 생김새
- 렐루 함수는 +신호는 그대로 -신호는 차단하는 함수라고 하였는데, 그 생김새는 아래와 같다.
$$ h(x) = \begin{cases}
x \ \ \ (x>0) \\
0 \ \ \ (x\leq 0)
\end{cases} $$
- 말 그대로, 양수면 자기 자신을 반환하고, 음수면 0을 반환한다.
- 이번에는 이를 구현해보고, 어떻게 생겼는지 확인해보자.
>>> import numpy as np
# ReLU 함수를 구현해보자
>>> def ReLU(x):
>>> return np.maximum(0, x)- 단순하게 최댓값 함수를 사용하여 지금 들어온 값(원소별 연산이 된다!)이 0보다 크면 자기 자신을 반환하고, 그렇지 않으면, 최댓값인 0을 반환하는 함수를 이용해서 구현하였다.
>>> import matplotlib.pyplot as plt
>>> x = np.arange(-5.0, 5.0, 0.1)
>>> y = ReLU(x)
>>> fig = plt.figure(figsize=(8,6))
>>> fig.set_facecolor('white')
>>> plt.title("ReLU", fontsize=30)
>>> plt.xlabel('x', fontsize = 15)
>>> plt.ylabel('y', fontsize = 15, rotation = 0)
>>> plt.axvline(0.0, color='gray', linestyle="--", alpha=0.8)
>>> plt.axhline(0.0, color='gray', linestyle="--", alpha=0.8)
>>> plt.plot(x, y)
>>> plt.show()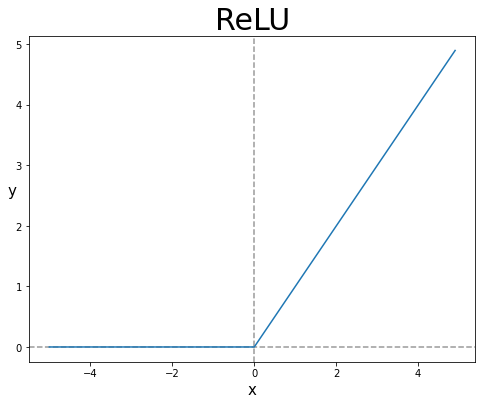
- 가장 많이 사용되는 활성화함수라기엔 지금까지 보아왔던 시그모이드, 소프트맥스, 하이퍼볼릭 탄젠트 등에 비해 너무 단순하게 생겼다는 생각이 들 것이다.
- 그렇다면 왜 렐루 함수를 은닉층에서 많이 사용할까?
2. 렐루 함수를 은닉층에서 많이 사용하는 이유
기울기 소실(Vanishing Gradient) 문제가 발생하지 않는다.
- 렐루 함수는 양수는 그대로, 음수는 0으로 반환하는데, 그러다 보니 특정 양수 값에 수렴하지 않는다.
- 즉, 출력값의 범위가 넓고, 양수인 경우 자기 자신을 그대로 반환하기 때문에, 심층 신경망인 딥러닝에서 시그모이드 함수를 활성화 함수로 사용해 발생한 문제였던 기울기 소실(Vanishing Gradient) 문제가 발생하지 않는다.
기존 활성화 함수에 비해 속도가 매우 빠르다
- 동시에 렐루 함수의 공식은 음수면 0, 양수면 자기 자신을 반환하는 아주 단순한 공식이다 보니, 경사 하강 시 다른 활성화 함수에 비해 학습 속도가 매우 빠르다!
- 확률적 경사하강법(SGD)을 쓴다고 할 때, 시그모이드 함수나 하이퍼볼릭 탄젠트 함수에 비해 수렴하는 속도가 약 6배 가까이 빠르다고 한다!
- ReLU가 나오기 전에는 활성화 함수가 부드러워야(Smooth) 가중치 업데이트가 잘된다고 생각하여 exp 연산이 들어간 시그모이드나, 하이퍼볼릭 탄젠트 함수를 사용하여쓰나, 활성화 함수가 부드러운(Smooth)한 구간에 도달하는 순간 가중치 업데이트 속도가 매우 느려진다.
- ReLU는 편미분(기울기) 시 1로 일정하므로, 가중치 업데이트 속도가 매우 빠르다.
3. 렐루 함수의 한계점
- 렐루 함수의 그래프를 보면, 음수 값이 들어오는 경우 모두 0으로 반환하는 문제가 있다보니, 입력값이 음수인 경우 기울기도 모조리 0으로 나오게 된다.
- 입력값이 음수인 경우에 한정되긴 하지만, 기울기가 0이 되어 가중치 업데이트가 안되는 현상이 발생할 수 있다.
- 즉, 가중치가 업데이트 되는 과정에서 가중치 합이 음수가 되는 순간 ReLU는 0을 반환하기 때문에 해당 뉴런은 그 이후로 0만 반환하는 아무것도 변하지 않는 현상이 발생할 수 있다.
- 이러한 죽은 뉴런(Dead Neuron)을 초래하는 현상을 죽어가는 렐루(Dying ReLU) 현상이라고 한다.
- 또한 렐루 함수는 기울기 소실 문제 방지를 위해 사용하는 활성화 함수이기 때문에 은닉층에서만 사용하는 것을 추천한다.
- ReLU의 출력값은 0 또는 양수이며, ReLU의 기울기도 0 또는 1이므로, 둘 다 양수이다. 이로 인해 시그모이드 함수처럼 가중치 업데이트 시 지그제그로 최적의 가중치를 찾아가는 지그재그 현상이 발생한다.
- 또, ReLU의 미분은 0 초과 시, 1 0은 0으로 끊긴다는 문제가 있다. 즉, ReLU는 0에서 미분이 불가능하다.
(이에 대해 활성화 함수로는 미분 불가능 하다할지라도, 출력값 문제는 아니고, 0에 걸릴 확률이 적으니, 이를 무시하고 사용한다.)
지금까지 은닉층에서 주로 사용되는 활성화 함수인 렐루 함수에 대해 학습해보았다. 비록 렐루 함수가 입력값이 0일 때, 기울기가 0에 수렴해 가중치 업데이트가 안 되는 현상이 발생한다고는 하지만, 성능상 큰 문제가 없으며, 도리어 이를 해결하기 위해 만든 활성화 함수의 성능이 보다 안 나오는 경우도 있다고 한다.
때문에 기본적으로 은닉층에서는 렐루 함수를 사용하지만, 때에 따라 렐루 함수의 단점이 두드러지는 경우도 존재하므로, 렐루 함수의 한계점을 보완하기 위한 렐루 함수의 형제 함수들이 있다.
다음 포스트에서는 렐루 함수의 한계점을 극복하기 위해 만들어진 다양한 활성화 함수에 대해 학습해보도록 하곘다.
'Machine Learning > Deep Learning' 카테고리의 다른 글
| 딥러닝-4.0. 인공신경망(1)-신경망 연산(SLP) (0) | 2021.01.28 |
|---|---|
| 딥러닝-3.5. 활성화함수(6)-ReLU Family (0) | 2021.01.27 |
| 딥러닝-3.3. 활성화함수(4)-하이퍼볼릭 탄젠트 함수(tanh) (0) | 2021.01.26 |
| 딥러닝-3.2. 활성화함수(3)-소프트맥스 함수(Softmax) (0) | 2021.01.26 |
| 딥러닝-3.1. 활성화함수(2)-시그모이드 함수(Sigmoid) (3) | 2021.01.25 |


