활성화 함수(Activation Function)
이전 퍼셉트론에서 학습했던 내용을 보면, 입력층(Input layer)에서 전달된 정보(값)는 가중치를 받아 값이 변하고, 가중치를 받아 합산된 값($w_1x_1 + x_2x_2$)이 편향($b=-\theta$)보다 크거나 작다에 의해 정보가 전달(0 또는 1) 된다고 하였다.
이번 포스트에서는 이 정보가 전달되는지, 즉 정보가 활성화 되는지 혹은 정보가 활성화된다면, 어떻게 활성화되어 출력 값을 생성해내는지를 결정하는 활성화 함수(Activation Function)에 대해 학습해보겠다.
1. 퍼셉트론에서 활성화 함수가 적용된 방법
- 우리가 퍼셉트론에서 사용했던 "임계값을 넘으면 정보가 전달되고, 임계값을 넘지 않으면 정보가 전달되지 않는다. "는 말을 활성화 함수에 초점을 맞춰서 보다 단순화된 공식으로 만들어보자.
$$ X = w_1x_1 + w_2x_2 + b $$
$$ h(x) = \begin{cases}
0 \ \ (x \leq 0) \\
1 \ \ (x >0)
\end{cases} $$
- 위 공식에서 퍼셉트론 수식의 결과인 $X$는 활성화 함수 $h(x)$에 들어가게 되고, 그 결과는 출력 값 $y$로 나오게 된다. 이를 이해하기 쉽게 그림으로 그려보자.

- 이전에 봤던 퍼셉트론의 그림과 달리 파란색 노드가 새로 추가되지 않았는가?
- 이는 편향값이던 $b$를 노드와 동일한 형태로 만든 것이다. 이로써 $w_1, w_2, b$모두 단순하게 가중치라고 생각해도 충분한 상황이 만들어졌다.
- 앞에서도 설명하긴 했지만, 다시 한번 설명해보자면, 각 노드 1, $x_1, x_2$는 각각 $b, w_1, w_2$를 가중치로 받아 곱해지고, $X$로 합산되어 나온다. 합산된 $X$는 활성화 함수 $h(X)$가 되어 출력 값인 $y$가 최종적으로 도출되게 된다.
2. 계단 함수(Step Function)
- 이번엔 위 퍼셉트론에서 활성화 함수로 사용된, 계단 함수(Step Function)에 대해 초점을 맞춰보자.
$$ h(x) = \begin{cases}
0 \ \ (x \leq 0) \\
1 \ \ (x >0)
\end{cases} $$
- 계단 함수라고 하니, 대체 무슨 소리인가 싶을 텐데, 위 공식을 그래프로 그려보면 쉽게 이해할 수 있다.
>>> import numpy as np
>>> import matplotlib.pyplot as plt
# 계단 함수1
>>> def step_function1(x):
>>> if x <= 0:
>>> return 0
>>> else x>0:
>>> return 1
# 계단 함수2
>>> def step_function2(x):
>>> y = x > 0
>>> return y.astype(np.int)- 위 코드를 보면, 위 코드는 단순히 "만약 x가 0 이하면 0을 반환하고, 0 초과이면 1을 반환하라"라는 의미로 단순하게 받아들여질 수 있는데, 아래 코드는 무슨 의미인지 잘 와 닿지 않을 수 있다.
- x.astype(np.int)는 데이터 x를 정수(int) 타입으로 바꿔준다는 것인데, x > 0의 결과는 x로 주어진 인자들이 0보다 큰지 작은지를 진리 값을 반환하며, True는 1, False는 0이므로, 위 step_function1과 같은 기능을 갖는 것이다.
- 코드를 쉽고 다른 사람도 이해하기 쉽게 짜려면 위 코드도 괜찮은 선택이다. 다만 상황에 따라 데이터의 양이 너무 많이 성능을 따져야한다면, 이런 식으로 같은 결과를 가지고 오지만, 다른 방법으로 돌아가는 코드도 짜서 성능 비교를 해볼 필요는 있다.
# 계단 함수를 그려보자
>>> np.arange(-5.0, 5.0, 0.1)
>>> y = step_function2(x)
# 캔버스 설정
>>> fig = plt.figure(figsize=(8,8)) # 캔버스 생성
>>> fig.set_facecolor('white') # 캔버스 색상 설정
>>> plt.plot(x, y)
>>> plt.ylim(-0.5, 1.5)
>>> plt.xlim(-5, 5)
>>> plt.ylabel('y', fontsize = 20, rotation = 0)
>>> plt.xlabel('x', fontsize = 20)
>>> plt.title("Step Function", fontsize = 30)
>>> plt.show()
- 위 그래프를 보면, 마치 계단을 올라가듯이, x가 0을 기준으로 크게 변하는 것을 알 수 있다.
- 위 함수의 의미는 아주 순수하게 신경 세포의 전달 방법을 묘사한 기법으로, 출력되는 결과값이 갖는 정보가 너무 희석된다는 단점이 있다.
- 예를 들어, 합산된 값이 0.1인 경우와 1.0인 경우는 단순 산술적으로 10배 정도 차이가 있으나, 이를 모두 무시하고 단순하게 1로 전달하므로, 합산된 값의 강도에 대한 의미가 부여되지 않는다.
3. 선형 함수(Linear Function)
- 앞서 본 계단 함수는 합산된 값의 크기를 완전히 무시한다는 단점이 있다고 했다.
- 그렇다면, 정직하게 자신의 값을 나타내는 선형 함수(일차 함수)는 어떨까?
$$ y = kx (k: 상수)$$
# 선형 함수
>>> def Linear_Function(x, k):
>>> return k*x
>>> x = np.arange(-5.0, 5.0, 0.1)
>>> y = Linear_Function(x, 0.7)
# 캔버스 설정
>>> fig = plt.figure(figsize=(8,7)) # 캔버스 생성
>>> fig.set_facecolor('white') # 캔버스 색상 설정
>>> plt.plot(x, y)
>>> plt.ylim(-1, 4)
>>> plt.xlim(-1, 4)
>>> plt.axhline(c="black")
>>> plt.axvline(c="black")
>>> plt.ylabel('y', fontsize = 20, rotation = 0)
>>> plt.xlabel('x', fontsize = 20)
>>> plt.title("Linear Function", fontsize = 30)
>>> plt.show()
- 자 아주 단순한 일차 함수를 그려보았다.
- 그러나, 선형 함수는 활성화 함수로 사용할 수 없는 치명적인 단점을 2가지 가지고 있다.
선형 함수를 활성화 함수로 사용하지 못하는 이유
1. 선형 함수는 층을 쌓는 의미가 없게 만든다.
- 예를 들어 3개 층으로 구성된 신경망이 있다고 가정해보자.
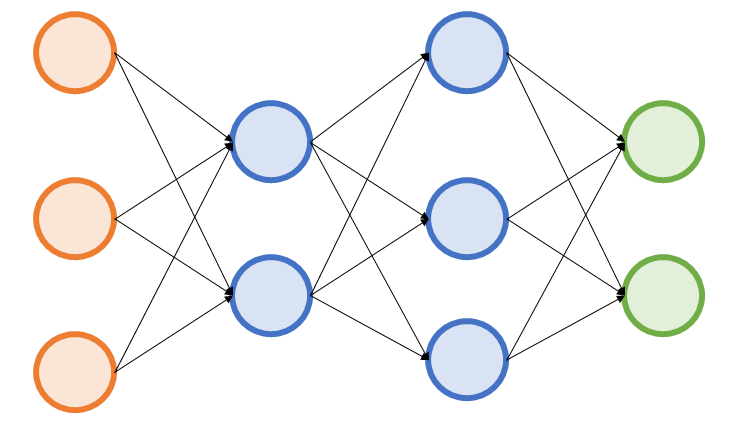
- 만약, 활성화 함수가 선형 함수 $h(x) = cx$라면, 각 노드에서 합쳐져 출력된 값들은 계수 c만큼 계속 곱해져 가며 커지기만 할 뿐이다.
- 즉, $h(x) = cx$를 쓰는 것과 $h(x) = ax \ \ (a = c^3)$를 쓰는 것과 큰 차이가 없는 형태가 된다.
- 물론, 이는 선형 함수를 절대 써선 안된다는 의미가 아니다. 선형 함수는 녹색 부분인 출력층에서 사용하는 것엔 문제가 없으나, 은닉층(파란색)에서 사용할 경우, 층이 쌓이는 것에 의미가 사라지기 때문에 사용하지 않는 것이 좋다.
2. 입력치에 이상치가 존재하는 경우, 분류를 불가능하게 만든다.
- 예를 들어, 학습 기간에 따른 합격 여부를 나눈다고 해보자.
- 공부 기간이 4일 이하인 경우, 불합격이 차지하는 비중이 많았고, 5일 이상에서 합격이 차지하는 비중이 훨씬 많았다. 그렇다면, 신경망은 4일을 기준으로 해서 합격 불합격 여부를 나누려고 학습을 할 것이다.
- 그러나, 만약, 누군가가 지나치게 공부를 오래하여, 1달 동안 공부를 해버렸다고 해보자. 이 경우 신경망은 어디를 기준으로 분류를 해야 할지 헷갈리게 된다.
반대로 말하자면, 활성화 함수로 선형 함수를 사용하는 것은, 만약 다층 신경망이 아니거나, 입력치에 이상치가 없거나, 이상치를 조정하여 데이터에서 이상치가 존재하지 않는 형태로 만들었다면, 선형 함수를 쓰는 것에 큰 문제가 없다.
지금까지 활성화 함수에서 가장 기초가 되는 계단 함수와 선형 함수에 대해 알아보았다. 선형 함수도 사용은 가능하나, 제한적으로 사용 가능하며, 다층 신경망에서 사용 시, 은닉층에서 사용해서는 안되므로, 주의해서 사용하길 바란다.
다음 포스트에서는 분류를 할 때, 가장 많이 사용되는 두 활성화 함수인 Sigmoid, Softmax에 대해 알아보겠다.
'Machine Learning > Deep Learning' 카테고리의 다른 글
| 딥러닝-3.2. 활성화함수(3)-소프트맥스 함수(Softmax) (1) | 2021.01.26 |
|---|---|
| 딥러닝-3.1. 활성화함수(2)-시그모이드 함수(Sigmoid) (3) | 2021.01.25 |
| 딥러닝-2.1. 퍼셉트론(2)-XOR 게이트 (0) | 2021.01.24 |
| 딥러닝-2.0. 퍼셉트론(1)-논리회로 (0) | 2021.01.23 |
| 딥러닝-1.0. 신경 세포와 퍼셉트론 (1) | 2021.01.22 |