728x90
반응형

이전 포스트에서 데이터 셋을 표준 정규분포로 만들어 더 쉽게 데이터셋을 모델에 학습시켜보았다. 그러나, 패턴의 단순함에 비해 여전히 정확도(Accuracy)가 원하는 수준까지 나오질 않는다. 대체 왜 그럴까?
이번 포스트에서는 경험적 하이퍼 파라미터 튜닝 방법을 사용하여, 하이퍼 파라미터를 튜닝해보도록 하겠다. 제대로 된 하이퍼 파라미터 튜닝은 추후 자세히 다루도록 하겠다.
하이퍼 파라미터 튜닝(HyperParameter Tuning)
- 머신러닝을 공부하다 보면 하이퍼 파라미터라는 단어와 파라미터라는 단어가 반복해서 등장하는 것을 볼 수 있다.
- 파라미터(Parmeter)라는 단어는 코딩을 하다 보면 자주 보이는, 수정할 수 있는 값인데, 갑자기 왜 하이퍼 파라미터라는 값이 등장할까? 또, 왜 파라미터는 수정할 수 없는 값이라고 할까?
- 머신러닝에서의 파라미터는 가중치(Weight), 편향(Bias) 같은 학습 과정에서 모델이 자동으로 업그레이드하며 갱신하는 값을 가리킨다.
- 파라미터는 학습 도중 머신이 알아서 바꿔가는 것이므로, 연구자가 손 델 수 있는 값이 아니다.
- 머신러닝에서 하이퍼 파라미터는 그 외 연구자가 수정할 수 있는 값으로, 학습률, Optimizer, 활성화 함수, 손실 함수 등 다양한 인자들을 가리킨다.
- 이 값들을 손보는 이유는 모델이 학습에 사용한 데이터 셋의 형태를 정확히 알지 못하고, 데이터 셋의 형태에 따라 이들을 사용하는 방법이 바뀌기 때문이다.
1. 하이퍼 파라미터 튜닝을 해보자.
- 우리는 이미 우리가 만들어낸 데이터 셋의 형태를 알고 있다.
- 우리가 만들어낸 데이터셋은 선형 데이터셋인데, 우리는 활성화 함수로 은닉층에서 ReLU를 사용하였다.
- 이번엔 모든 활성화 함수를 linear로 만들어 학습시켜보자.
# Import Module
import pandas as pd
import numpy as np
from tensorflow import keras
from tensorflow.keras.layers import Dense
# Dataset Setting
def f(x):
return x + 10
# Data set 생성
np.random.seed(1234) # 동일한 난수가 나오도록 Seed를 고정한다.
X_train = np.random.randint(0, 100, (100, 1))
X_test = np.random.randint(100, 200, (20, 1))
# Label 생성
y_train = f(X_train)
y_test = f(X_test)
# Model Setting
model = keras.Sequential()
model.add(Dense(16, activation='linear'))
model.add(Dense(1, activation='linear'))
# Compile: 학습 셋팅
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=opt, loss = 'mse')
# 특성 스케일 조정
mean_key = np.mean(X_train)
std_key = np.std(X_train)
X_train_std = (X_train - mean_key)/std_key
y_train_std = (y_train - mean_key)/std_key
X_test_std = (X_test - mean_key)/std_key# 학습
>>> model.fit(X_train_std, y_train_std, epochs = 100)
Epoch 1/100
4/4 [==============================] - 0s 2ms/step - loss: 2.5920
Epoch 2/100
4/4 [==============================] - 0s 997us/step - loss: 1.5766
Epoch 3/100
4/4 [==============================] - 0s 2ms/step - loss: 0.7499
Epoch 4/100
4/4 [==============================] - 0s 2ms/step - loss: 0.3371
Epoch 5/100
4/4 [==============================] - 0s 2ms/step - loss: 0.0817
Epoch 6/100
4/4 [==============================] - 0s 2ms/step - loss: 0.0059
...
Epoch 95/100
4/4 [==============================] - 0s 1ms/step - loss: 6.0676e-15
Epoch 96/100
4/4 [==============================] - 0s 1ms/step - loss: 6.2039e-15
Epoch 97/100
4/4 [==============================] - 0s 2ms/step - loss: 6.4773e-15
Epoch 98/100
4/4 [==============================] - 0s 2ms/step - loss: 5.6185e-15
Epoch 99/100
4/4 [==============================] - 0s 1ms/step - loss: 6.5939e-15
Epoch 100/100
4/4 [==============================] - 0s 1ms/step - loss: 6.7939e-15
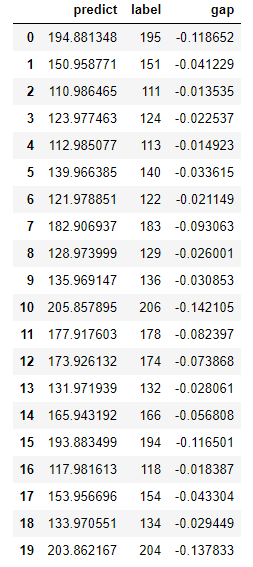
<tensorflow.python.keras.callbacks.History at 0x26e75c29e80># label과 test set을 비교해보자.
pred = model.predict(X_test_std.reshape(X_test_std.shape[0]))
pred_restore = pred * std_key + mean_key
predict_DF = pd.DataFrame({"predict":pred_restore.reshape(pred_restore.shape[0]), "label":y_test.reshape(y_test.shape[0])})
predict_DF["gap"] = predict_DF["predict"] - predict_DF["label"]
predict_DF
# 정확도(Accuracy)를 보자
>>> print("Accuracy:", np.sqrt(np.mean((pred_restore - y_test)**2)))
Accuracy: 1.0789593218788873e-05- 고작, 은닉층의 활성화 함수만 바꿨을 뿐인데, 이전보다 훨씬 좋은 결과가 나왔다.
- 패턴을 거의 완벽하게 찾아내었으며, 정확도(Accuracy) 역시 0.000010789(e-05는 $10^{-5}$을 하라는 소리다.)로 거의 0에 근사하게 나왔다.
2. 정리
- 위 결과를 보면, 아무리 단순한 패턴이라 할지라도, 그 데이터 셋의 형태를 반영하지 못한다면, 정확히 그 결과를 찾아내지 못할 수 있다는 것을 알 수 있다.
- 인공지능은 흔히들 생각하는 빅데이터를 넣으면, 그 안에 숨어 있는 패턴이 자동으로 나오는 마법의 상자가 아니라, 연구자가 그 데이터에 대한 이해를 가지고 여러 시도를 해, 제대로 된 설계를 해야만 내가 원하는 제대로 된 패턴을 찾아낼 수 있는 도구다.
- 그러나, 실전에서는 지금처럼 우리가 이미 패턴을 알고 있는 경우는 없기 때문에 다양한 도구를 이용해서, 데이터를 파악하고, 적절한 하이퍼 파라미터를 찾아낸다.
- 넣을 수 있는 모든 하이퍼 파라미터를 다 넣어보는 "그리드 서치(Greed search)"나 랜덤 한 값을 넣어보고 지정한 횟수만큼 평가하는 "랜덤 서치(Random Search)", 순차적으로 값을 넣어보고, 더 좋은 해들의 조합에 대해서 찾아가는 "베이지안 옵티마이제이션(Bayesian Optimization)" 등 다양한 방법이 있다.
- 같은 알고리즘이라 할지라도, 데이터를 어떻게 전처리하느냐, 어떤 활성화 함수를 쓰느냐, 손실 함수를 무엇을 쓰느냐 등과 같은 다양한 요인으로 인해 다른 결과가 나올 수 있으므로, 경험을 많이 쌓아보자.
728x90
반응형
'Machine Learning > TensorFlow' 카테고리의 다른 글
| Tensorflow-1.6. 기초(7)-기초 모델 만들기(2)-Input 4개, Output 2개 (0) | 2021.02.09 |
|---|---|
| Tensorflow-1.5. 기초(6)-기초 모델 만들기(1)-변수 2개인 경우 (0) | 2021.02.08 |
| Tensorflow-1.3. 기초(4)-특성 스케일 조정 (0) | 2021.02.08 |
| Tensorflow-1.2. 기초(3)-학습하기(2) (2) | 2021.02.08 |
| Tensorflow-1.1. 기초(2)-학습하기(1) (0) | 2021.02.08 |