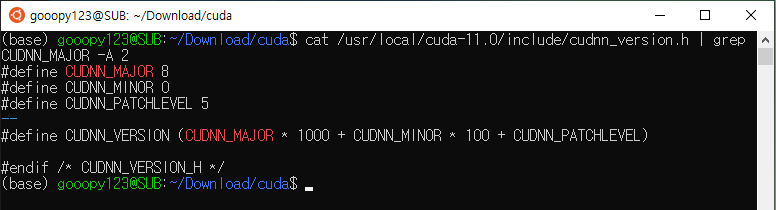
이전 포스트에서 CUDA 세팅에 필요한 CUDA와 cuDNN을 다운로드하였다. 이번 포스트에서는 CUDA를 설치해보도록 하겠다.
0. 다른 버전의 CUDA가 설치되어 있는지 확인하기
현재 CUDA를 세팅하는 환경은 wsl2를 이용하여 만들어진 가상 환경이기 때문에 엔비디아 드라이버가 설치되어 CUDA가 꼬일 문제가 없지만, 윈도우 PC나 사용하려는 텐서플로우 버전과 기존 서버에 세팅된 CUDA 버전이 다른 경우, 기존 NVIDIA 파일과 CUDA를 제거해줘야 한다.
현재 환경에 엔비디아 드라이버가 설치되어 있다면, 다음과 같은 방법으로 그래픽 드라이버 정보를 얻을 수 있다.
nvidia-smi
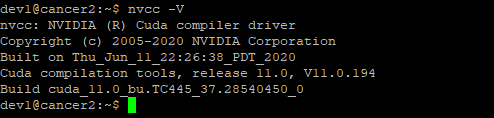
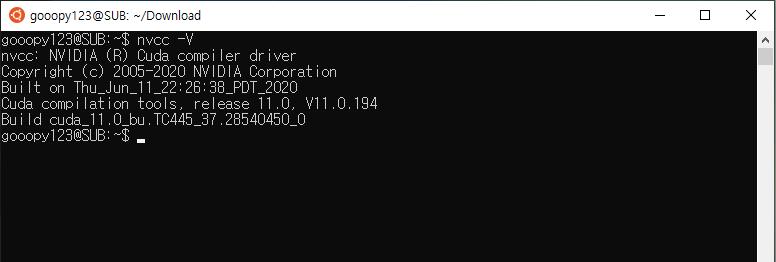
nvcc -V
CUDA가 설치되어 있다면, nvcc -V를 확인하면 된다.
경우에 따라 nvcc -V에서 출력되는 쿠다와 nvidia-smi에서 출력되는 CUDA Version이 다른 경우가 있는데, 이는 CUDA가 꼬여 있는 것일 수 있기 때문에 이후에 Tensorflow 사용 시, 충돌이 일어날 수 있다. 때문에 CUDA 파일과 nvidia 관련 파일을 완전히 제거하여, CUDA를 맞춰주는 것이 좋다.
nvidia-smi 입력 시 출력되는 화면은 다음과 같다.
nvcc -V 입력 시 출력되는 화면은 다음과 같다.
엔비디아 드라이버와 쿠다를 제거하는 방법은 다음과 같다.
# nvidia driver 삭제
sudo apt-get remove --purge '^nvidia-.*'
# CUDA 삭제
sudo apt-get --purge remove 'cuda*'
sudo apt-get autoremove --purge 'cuda*'
# CUDA 남은 파일 삭제
sudo rm -rf /usr/local/cuda
sudo rm -rf /usr/local/cuda-10.1
엔비디아 드라이버와 쿠다 제거 후, 성공적으로 제거되었는지 확인하기 위해, nvidia-smi, nvcc -V와 같은 코드를 입력하여, 제대로 제거되었는지 확인하자.
그러나, CUDA가 여러 개 깔려 있거나, 여러 개의 GPU 서버의 GPU가 연결 되어 있는 경우, 위 방법대로 제거하더라도, nvidia-smi나 nvcc -V가 다시 출력될 수 있다.
1. CUDA 설치하기
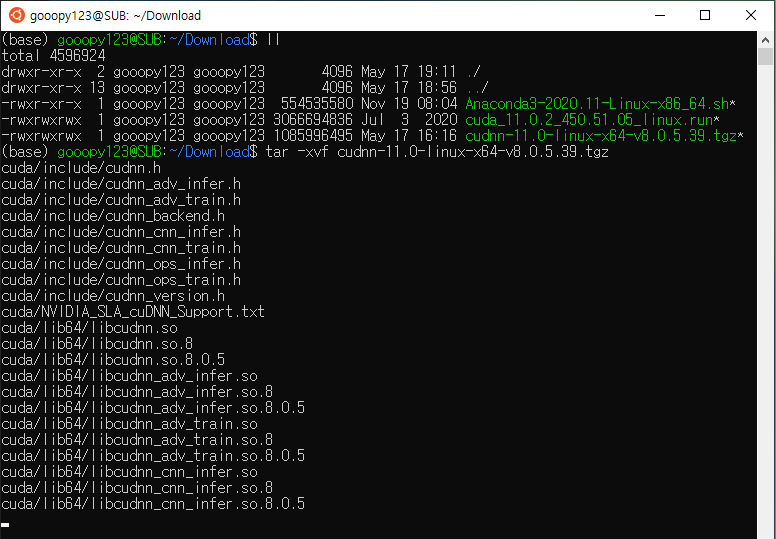
이전 포스트에서 다운로드하였던 CUDA 파일을 실행하기 전에 권한을 부여하도록 하자.
이전 포스트까지 Download 디렉터리에 받았던 파일들은 다음과 같다.
위 사진에서 cuda_11.0.2_450.51.05_linux.run에 chmod를 사용하여, 777 권한을 부여하자.
chmod 777 cuda_11.0.2_450.51.05_linux.run
ll
이제 cuda_11.0.2_450.51.05_linux.run을 실행하여 CUDA를 설치하도록 하자.
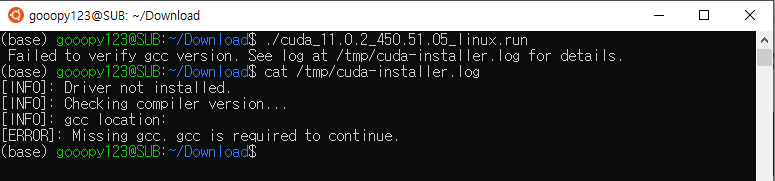
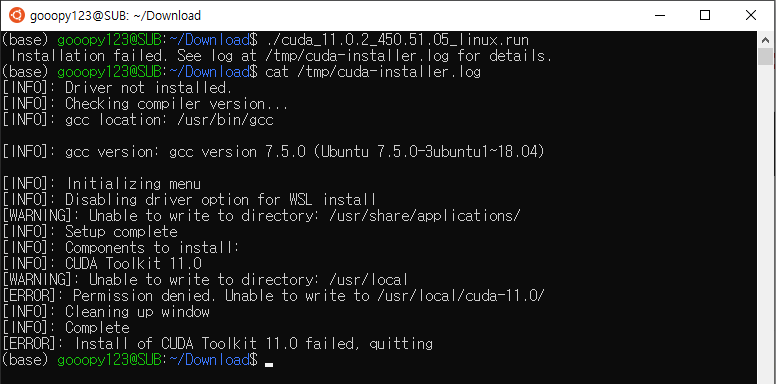
./cuda_11.0.2_450.51.05_linux.run
gcc 에러 발생
CUDA 설치 시, 다음과 같은 에러가 뜰 수도 있다.
Failed to verify gcc version. See log at /tmp/cuda-installer.log for details.
관련 로그를 확인하기 위해 위 에러가 말해준 위치로 이동해보자.
위 내용을 보니, gcc 가 없어서 발생한 문제임을 알 수 있다.
gcc를 설치하여, 위 문제를 해결해줘야 한다.
위 문제가 뜬 경우 apt를 비롯한 가장 기본적인 세팅도 안되어 있는 것이므로, 가능한 위와 같은 상황에선 인터넷을 열어달라 하여, 위와 같은 기본적인 세팅은 해놓는 것을 추천한다.
이전 포스트까지 Wide & Deep Learning 모델을 사용해서 다중 입력 모델을 만들어보았다. 이번엔 이전 모델에 추가로 출력층을 추가하여 출력층을 2개로 만들어 보도록 하자.
다중 출력 모델
일반적으로 다중 출력 모델을 사용하는 이유는 다음과 같다.
프로세스가 서로 독립적인 경우: 동일한 데이터 셋에서 두 개 이상의 출력층을 생성하지만, 출력된 결과는 전혀 다른 작업을 위해 실행되는 경우로, 예를 들어 인터넷 사용 Log 데이터를 기반으로, 대상의 관심사 파악(분류 모델)과 인터넷 사용률 예측(회귀 모델)은 별개의 목적을 위해 진행된다.
프로세스가 한 목적을 위해 상호 보완적으로 이루어지는 경우: 하나의 목적을 이루기 위해 두 개 이상의 출력 값이 필요하여, 동일한 데이터 셋에서 두 개 이상의 출력층을 뽑아내는 경우로, 예를 들어 영상 속 물건을 인식하는 모델을 만든다면, 영상 속 물건의 위치(회귀 모델)와 물건의 종류(분류 모델)를 동시에 파악해야 한다.
규제 도구로써의 다중 출력 모델: 하위 네트워크가 나머지 네트워크에 의존하지 않고, 그 자체로 유용한 성능을 내는지 확인을 하기 위한 규제 기법으로 사용
이번 포스트에서는 Wide & Deep Learning model에 다중 출력 모델을 규제 도구로써 사용해보도록 하자.
1. 규제 도구로써의 다중 출력 모델
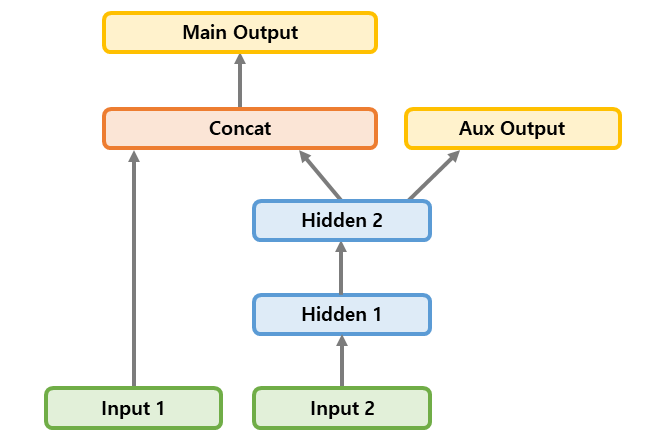
보조 출력층(Auxiliary Output)을 통해, 하위 네트워크가 나머지 네트워크에 의존하지 않고 그 자체로 유용한 것을 학습하는지 확인한다. 위 모델대로라면, Deep model에서의 출력된 값이 Wide model과의 연결로 인해, 원하는 결과를 뽑아내는 것인지, Deep model으로 인해 그러한 결과가 나왔는지 확인할 수 있다.
이를 통해, 과대 적합을 감소시키고, 모델의 일반화 성능이 높이도록 학습에 제약을 가할 수 있다.
2. 모델 생성 이전까지의 코드 가져오기
이전 포스트에서 만들었던, 모델 이전까지의 코드를 모두 가지고 온다.
입력층이 2개일 때는 입력 데이터를 목적에 맞게 나눴어야 했지만, 이번엔 출력층이 다른 데이터를 출력하는 것이 아니라, 보조 출력층(Auxiliary Output)과 주 출력층(Main Output)이 동일한 정답에 대해 어느 정도의 손실 값과 정확도를 내보내는지 알고 싶은 것이므로, Label dataset을 나누지 않아도 된다.
#################################### Import Module ####################################
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import callbacks
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import (Input, Dense, concatenate)
########################################################################################
#################################### Import Dataset ####################################
# 캘리포니아 데이터 가져오기
Rawdict = fetch_california_housing()
CaliFornia_DF = pd.DataFrame(Rawdict.data, columns=Rawdict.feature_names)
########################################################################################
#################################### Data Handling #####################################
# 데이터를 쪼개기 좋게 변수의 순서를 바꾸자
CaliFornia_DF = CaliFornia_DF[["HouseAge", "Population", "Latitude", "Longitude", "MedInc",
"AveRooms", "AveBedrms", "AveOccup"]]
# train, validation, test set으로 쪼갠다.
X_train_all, X_test, y_train_all, y_test = train_test_split(CaliFornia_DF.values, Rawdict.target, test_size = 0.3)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_all, y_train_all, test_size = 0.2)
# 정규화시킨다.
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)
# 데이터 셋을 input layer의 수만큼 쪼갠다.
X_train_A, X_train_B = X_train[:, :1], X_train[:,1:]
X_valid_A, X_valid_B = X_valid[:, :1], X_valid[:,1:]
X_test_A, X_test_B = X_test[:, :1], X_test[:,1:]
########################################################################################
3. 모델 생성
######################################## Model ########################################
input_A = Input(shape=[1], name = "deep_input")
input_B = Input(shape=[7], name = "wide_input")
hidden1 = Dense(30, activation="relu", name = "hidden1")(input_A)
hidden2 = Dense(30, activation="relu", name = "hidden2")(hidden1)
concat = concatenate([input_B, hidden2], name = "concat")
output = Dense(1, name="main_output")(concat)
# 보조 출력층 생성
aux_output = Dense(1, name="aux_output")(hidden2)
model = keras.Model(inputs=[input_A, input_B], outputs=[output, aux_output])
########################################################################################
앞서 학습했던 방법처럼 보조 출력층 생성 역시 Keras API 함수로 구현하는 것은 꽤 단순하다.
보조 출력층(aux_output)과 데이터를 받는 층(hidden2)을 연결시키고, model에서 outputs을 2개 다 잡아주면 된다.
4. 모델 컴파일
다중 입력 모델과 달리 다중 출력 모델에서는 모델 컴파일 방법이 바뀌게 된다.
이는, 컴파일에서 출력층에서 모델을 평가하게 되는 손실 함수를 결정하기 때문이고, 이 손실 함수는 출력층마다 다르게 설정해야 하기 때문이다.
# 모델 컴파일
model.compile(optimizer=Adam(learning_rate=0.005),
loss = ["msle", "msle"],
metrics=["accuracy"],
loss_weights=[0.9, 0.1])
최적화나 모델 평가 지표는 출력층의 수와 상관없기 때문에 바뀌지 않는다.
손실 함수는 출력층이 2개가 되었으므로, 2개를 잡아줘야 한다(만약, 손실 함수를 하나만 잡아준다면, 모든 출력의 손실 함수가 같다고 가정한다 - 위 경우에는 출력층이 회귀모형이므로, msle로 같은 손실 함수를 사용하므로, msle 하나만 사용해도 된다).
loss_weights: 출력 층별 손실 값의 가중치를 정해준다. 케라스는 기본적으로 출력된 손실 값들을 모두 더해 최종 손실을 구하며, 이를 기반으로 학습을 한다. 여기서 사용된 보조 출력은 규제로 사용되었기 때문에 주 출력이 더 중요하다. 그러므로, 주 손실 값에 더 많은 가중치를 부여하였다.
5. 모델 학습 및 평가
모델 학습과 평가에서의 차이는 Label 역시 각 출력층에 맞게 2개가 들어가야 한다는 것이다.
해당 다중 출력 모델은 규제 목적으로 보조 출력층을 추가한 것이므로, 동일한 데이터를 label로 사용해도 된다.
이전과 달리 값이 굉장히 많이 나오기 때문에 이를 파악하기 어려울 수 있는데, 그 내용은 생각보다 상당히 단순하다.
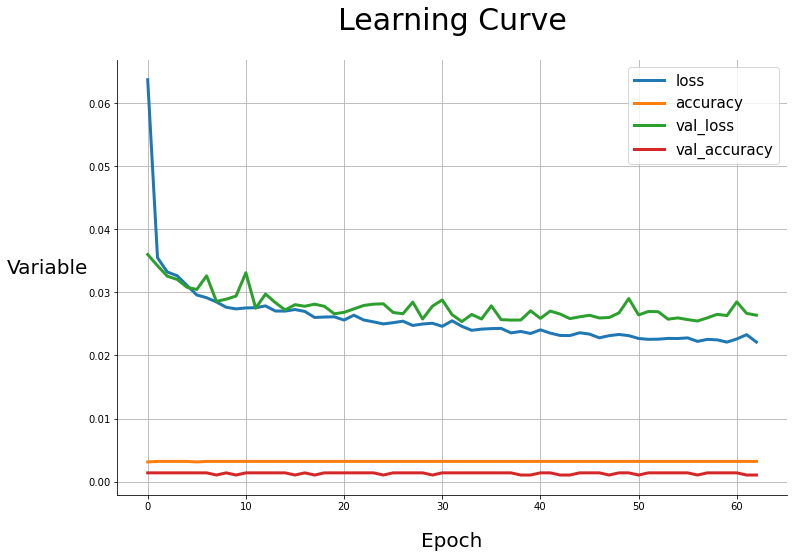
손실 값은 loss: 0.0533, main_output_loss: 0.0454, aux_output_loss: 0.1241이 나왔다.
여기서 loss만 신경 쓰면 된다. 위에서 우리는 main_output_loss와 aus_output_loss의 가중치를 0.9, 0.1로 부여하였는데, loss는 각 손실 값에 해당하는 가중치를 곱하여 합한 값이기 때문이다.
$$ 0.0533 = 0.9*0.0454 + 0.1*0.1241 $$
Deep model의 손실 값과 Wide & Deep Learning model의 손실 값을 동시에 반영하여, 총 손실 값을 계산하였으므로, Deep model이 Wide model과의 결합 없이도 우수한 성능을 보이는 것을 알 수 있다.
주 출력층의 Accuracy는 0.0029, 보조 출력층의 Accuracy도 0.0032로 Deep model, Wide & Deep Learning model 모두 Accuracy가 괜찮게 나왔다. 이로 인해 Deep model 자체만으로도 우수한 성능을 보이는 것을 알 수 있다.
5.1. 손실 값과 정확도를 시각화해보자.
def Drawing_Scalars(history_name):
history_DF = pd.DataFrame(history_name.history)
# 그래프의 크기와 선의 굵기를 설정해주었다.
history_DF.plot(figsize=(12, 8), linewidth=3)
# 교차선을 그린다.
plt.grid(True)
plt.legend(loc = "upper right", fontsize =15)
plt.title("Learning Curve", fontsize=30, pad = 30)
plt.xlabel('Epoch', fontsize = 20, loc = 'center', labelpad = 20)
plt.ylabel('Variable', fontsize = 20, rotation = 0, loc='center', labelpad = 40)
# 위 테두리 제거
ax=plt.gca()
ax.spines["right"].set_visible(False) # 오른쪽 테두리 제거
ax.spines["top"].set_visible(False) # 위 테두리 제거
plt.show()
Drawing_Scalars(history)
굉장히 많은 지표들이 추가되었지만, Early Stopping의 기준으로 사용한 val_loss를 본다면, patience가 30이었으므로, epochs 27에서 모델이 수렴하였다는 것을 알 수 있다.
[참고 자료]
이번 포스트에서는 다중 출력 모델을 Wide & Deep Learning model에서의 규제 기법으로 사용해보았다. Deep model의 결괏값에 대한 평가가 모델 전체 평가에 반영되었으므로, Deep Model의 일반화가 잘 이루어진 모델이 만들어졌다고 할 수 있다.
지금까지 Wide & Deep Learning 모델을 기반으로 다중 입력, 다중 출력 모델을 만드는 방법과 이를 통해 Wide & Deep Learning Model을 더 잘 사용할 수 있도록 해보았다.
이전 포스트에서는 Wide & Deep Learning 모델에 대한 간단한 설명과 함수형 API를 사용해서 기초적인 Wide & Deep Learning 모델을 만들어보았다. 이때는 완전히 동일한 Input 데이터를 바라보았으나, Wide & Deep Learning 모델은 다른 Input Layer를 만들어 Wide model과 Deep model에 따로 학습시킬 수 있다.
1. 다중 입력 Wide & Deep Learning
Wide & Deep Learning model의 특징은 Wide model에 전달되는 Feature와 Deep model에 전달되는 Feature를 다르게 할 수 있다는 것이다.
즉, 입력되는 Feature에서 일부 특성은 Wide model로 나머지 특성은 Deep model로 전달할 수 있다. (각 모델로 전달되는 특성은 중복 가능하다).
Deep model은 입력된 모든 데이터를 MLP에 있는 모든 층에 통과시키다 보니, 간단한 패턴이 연속된 변환으로 인해 왜곡될 위험이 있다.
때문에 Wide & Deep Learning model에서는 일반적으로 간단한 패턴이 있는 Column은 Wide model 쪽으로, 복잡한 패턴이 있는 Column은 Deep model 쪽으로 보낸다.
간단한 패턴이 있어 Wide model로 보낸 Column 역시 Deep model에서 숨겨진 패턴을 찾는데 도움이 될 수 있으므로, Wide model로 Input 될 데이터의 일부 혹은 전체를 Deep model에 같이 넣기도 한다.
이를 도식화해보면 다음과 같다.
위 모델을 보면 Input Layer가 2개 존재하는 것을 볼 수 있는데, 이처럼 한 번에 2개 이상의 Input이 존재하여 동시에 여러 입력을 하는 것을 다중 입력 모델이라 한다.
다중 입력 모델은 Keras의 함수형 API를 사용하면 쉽게 구현할 수 있다.
2. 데이터의 각 변수별 상세 정보 파악
이전 포스팅에서 해당 모델을 Input Layer 1개로 넣었을 때, 이미 Accuracy 0.0034, Loss 0.0242로 꽤 괜찮은 결과가 나왔었다. 굳이 데이터를 나눠서 넣을 필요는 없으나, Keras API를 이용해서 다중 입력하는 방법을 학습하기 위해, 데이터 셋을 쪼개 보도록 하겠다.
해당 포스트의 참고 논문(Heng-Tze Cheng et al.(2016))에서 예시로 든 단순한 패턴은 "설치한 앱"과 "열람한 앱"을 Cross-product transformation으로 생성한 희소 특징(Sparse feature)이다.
그러나, 해당 데이터셋에는 그 대상이 될 수 있는 범주형 데이터가 따로 없으므로, 데이터 패턴을 보는 가장 기초적인 방법인 히스토그램과 독립변수와 종속변수 간의 산점도(상관관계)를 만들어, 패턴이 아주 단순한 경우는 Wide model로, 그렇지 않은 경우는 Deep model로 넣어보겠다.
# Import Module
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import callbacks
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import (Input, Dense, Concatenate, concatenate)
2.1. 데이터 셋 정보 보기
sklearn에서 기본으로 제공하는 데이터에서는 아주 쉽게 메타 정보를 볼 수 있다.
>>> Rawdict = fetch_california_housing()
>>> print(Rawdict.DESCR)
.. _california_housing_dataset:
California Housing dataset
--------------------------
**Data Set Characteristics:**
:Number of Instances: 20640
:Number of Attributes: 8 numeric, predictive attributes and the target
:Attribute Information:
- MedInc median income in block
- HouseAge median house age in block
- AveRooms average number of rooms
- AveBedrms average number of bedrooms
- Population block population
- AveOccup average house occupancy
- Latitude house block latitude
- Longitude house block longitude
:Missing Attribute Values: None
This dataset was obtained from the StatLib repository.
http://lib.stat.cmu.edu/datasets/
The target variable is the median house value for California districts.
This dataset was derived from the 1990 U.S. census, using one row per census
block group. A block group is the smallest geographical unit for which the U.S.
Census Bureau publishes sample data (a block group typically has a population
of 600 to 3,000 people).
It can be downloaded/loaded using the
:func:`sklearn.datasets.fetch_california_housing` function.
.. topic:: References
- Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,
Statistics and Probability Letters, 33 (1997) 291-297
fig, axes = plt.subplots(nrows=4, ncols=2, figsize = (12, 20))
ax = axes.ravel()
xlabels = Rawdict.feature_names
plt.suptitle("Predict Variable & MedHouseVal Scatter", y=0.93, fontsize=25)
for i in range(Rawdict.data.shape[1]):
X = Rawdict.data[:,i]
Y = Rawdict.target
ax[i].scatter(X, Y, alpha = 0.025)
ax[i].set_title(xlabels[i], fontsize=15, fontweight ="bold")
Row가 20,640으로 단순하게 산점도로 그리기엔 그 양이 너무 많아, alpha를 0.025로 주어, 데이터가 동일한 위치에 많이 존재하지 않는다면 연하게, 많이 겹칠수록 진하게 그려지도록 설정하였다.
각 변수별 히스토그램과 독립변수 & 종속변수의 산점도를 볼 때, 단순한 패턴을 갖는 것은 AveRooms, AveBedrms, Population, AveOccup로 이들은 히스토그램에서도 데이터가 한쪽에 지나치게 모여있기 때문에 딱히 패턴이 존재하지 않는다. 그러므로, 이들을 Wide model에 넣겠다.
MedInc은 그 정도가 강하다고 할 수 있는 수준은 아니지만, 위 데이터 중 가장 뚜렷한 경향성을 가지고 있다. 이를 단순한 패턴으로 인식할지도 모르니, Wide model과 Deep model 양쪽에 넣어보자.
3. 데이터셋 쪼개기
입력층이 2개이므로, Train dataset, Validation dataset, Test dataset 모두 2개로 쪼개져야 한다.
def Drawing_Scalars(history_name):
history_DF = pd.DataFrame(history_name.history)
# 그래프의 크기와 선의 굵기를 설정해주었다.
history_DF.plot(figsize=(12, 8), linewidth=3)
# 교차선을 그린다.
plt.grid(True)
plt.legend(loc = "upper right", fontsize =15)
plt.title("Learning Curve", fontsize=30, pad = 30)
plt.xlabel('Epoch', fontsize = 20, loc = 'center', labelpad = 20)
plt.ylabel('Variable', fontsize = 20, rotation = 0, loc='center', labelpad = 40)
# 위 테두리 제거
ax=plt.gca()
ax.spines["right"].set_visible(False) # 오른쪽 테두리 제거
ax.spines["top"].set_visible(False) # 위 테두리 제거
plt.show()
Drawing_Scalars(history)
이전 포스트에서는 모든 데이터 셋을 Wide model과 Deep model에 넣었을 때는 Accuracy: 0.0034, Loss: 0.0242, epochs: 63에서 학습이 끝났으나, 이번 방법으로는 Accuracy: 0.0040, Loss: 0.0300, epochs: 280으로 기대에 미치는 성능이 나오진 않았다.
학습에 대한 평가는 큰 차이가 없으나, 도리어 epochs가 63에서 280으로 학습 시간이 크게 늘어, 성능이 도리어 크게 떨어진 모습을 보여주었다.
6. 위 문제를 해결해보자.
조기종료가 된 epochs가 63에서 280으로 증가했다는 소리는 주어진 데이터 셋이 이전보다 적합하지 않아, 학습하는데 시간이 오래 걸렸다는 소리다.
그렇다면, 위에서 보았던 독립변수의 데이터 분포(히스토그램)와 독립변수와 종속변수의 상관관계(산점도)로 데이터 패턴의 단순한 정도를 본 방법이 틀린 것일까?
앞서 우리가 학습하였던, "Tensorflow-4.0. 다층 퍼셉트론을 이용한 회귀모형 만들기"에서 회귀모형(Regression model)은 독립변수와 종속변수 간에 어떠한 경향성이 있다는 전제하에 독립변수가 변할 때, 종속변수가 변하고 이를 가장 잘 나타내는 계수를 찾는 것이 목적이라고 했다.
딥러닝 역시 회귀모형의 원리와 매우 유사하게 돌아가므로, 이번에는 독립변수와 종속변수의 산점도(상관관계)에서 어떠한 경향성도 갖지 않는 "HouseAge", "AveRooms", "AveBedrms", "Population", "AveOccup", "Latitude", "Longitude" 모두를 Wide model에 넣고, 약한 선형 관계를 보이는 "MedInc"만 Deep model에 넣어보도록 하겠다.
Deep model로는 1개의 변수만 집어넣었고, Wide model로 7개 변수를 넣었더니, Accuracy: 0.0024, Loss: 0.0468, epochs: 49(EarlyStopping의 patience인자가 30이므로, 실제 수렴은 epoch 19에서 한 것을 알 수 있다)로 수렴하였다.
모든 변수를 Deep model과 Wide model로 보내는 경우, Accuracy: 0.0034, Loss: 0.0242, epochs: 63으로, 정확도가 미미한 수준으로 더 좋아졌고, 수렴 속도가 보다 빨라졌으나, 큰 차이가 있진 않다.
Deep Learning은 아주 많은 양의 데이터가 있을 때, 그 안에 우리가 인식하지 못하는 패턴을 찾아내는 것이므로, 위와 같은 밀집 특징(Dense Feature)에 대해서는 모든 데이터를 넣는 것을 추천한다.
희소 특징(Sparse Feature)은 Deep model을 통과하며, 학습이 제대로 이루어지지 않을 수 있으므로, Wide model에는 희소 특징만 넣도록 하자.
7. 참고 - 일반적인 다중 입력 모델의 사용 예
위 그림처럼 다중 입력은, 전혀 다른 데이터 셋 들로부터 하나의 결과를 도출해낼 수도 있다.
예를 들어, 물건 판매 웹사이트 사용자들에 대해 패턴을 뽑고자 한다면, 사용자들의 정보는 Dense 모델로, 사용자의 제품 후기는 RNN 모델로, 사용자의 관심 있는 제품 사진들을 CNN 모델로 학습시키고 이를 하나로 합쳐 하나의 결괏값을 뽑아낼 수도 있다.
지금까지 Wide & Deep Learning model을 Input Layer를 2개로 하여 다중 입력 모델로 만들어보았다. Keras API로 모델을 만드는 경우, 위처럼 쉬운 방법으로 다중 입력, 다중 출력 모델을 만들 수 있으므로, Keras로 모델을 만들 땐, 가능한 API로 만들도록 하자.
지금까지 Wide & Deep Learning model의 개념을 어느 정도 알아보았으니, 다음 포스트에서는 좀 더 가볍게 해당 모델로 다중 입력, 다중 출력 모델을 만들어보도록 하겠다.
이전 포스트에서 다뤘던 선형 회귀 모형은 단일 입력층과 단일 출력층을 갖는 형태였다. 그러나, Keras를 사용하는 Tensorflow의 가장 큰 장점인 함수형 API모델을 사용하면, 다중 입력과 다중 출력을 갖는 모델을 만들 수 있다.
이번 포스트에서는 Keras의 장점인 함수형 API로 대규모 회귀 및 분류 모델에서 주로 사용되는 Wide & Deep Learning 모델을 만들어보자.
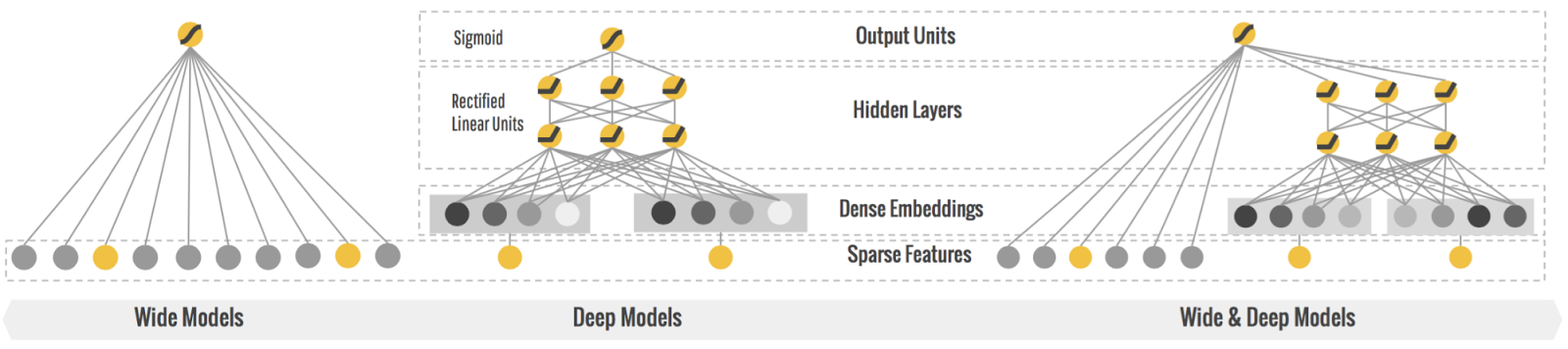
와이드 & 딥(Wide & Deep) 신경망
2016년 헝쯔 청(Heng-Tze Cheng et al.)의 논문에 소개된 신경망이다. Heng-Tze Cheng et al., "Wide & Deep Learning for Recommender Systems." Proceedings of the First Workshop on Deep Learning for Recommender Systems (2016): 7 - 10. http://homl.info/widedeep
인간은 일반화와 암기를 통해 학습을 한다.
일반화(Deep Models): 인간은 "참새는 날 수 있다.", "비둘기는 날 수 있다."를 통해 "날개를 가진 동물은 날 수 있다"라 일반화를 시킨다.
암기(Wide Models): 반면에 "펭귄은 날 수 없다.", "타조는 날 수 없다." 등과 같은 예외 사항을 암기하여, 일반화된 규칙을 더욱 세분화시킨다.
Wide & Deep Learning은 이러한 인간의 일반화와 암기를 결합하여 학습하는 점에 착안하여, 만들어진 기계 학습 방법이다.
앞서 우리가 학습해왔던 심층 신경망(Deep Network)은 대상으로부터 공통된 패턴을 찾아내어 일반화시키지만, 그 패턴을 가지고 있으나, 이에 해당하지 않는 많은 반례들이 존재한다. (일반적으로 딥 러닝에서는 이를 감안한 데이터 셋을 준비해 학습한다.)
Wide & Deep Learning은 여기서 더 나아가 넓은 선형 모델을 공동으로 학습시켜, 일반화(Deep Learning)와 암기(Wide Linear model)의 장점을 얻는다.
Wide & Deep Learning은 추천 시스템, 검색 및 순위 문제 같은 많은 양의 범주형 특징(Categorical Feature)이 있는 데이터를 사용하는 대규모 회귀, 분류 모델에서 유용하게 사용된다.
Wide & Deep Learning은 위 그림처럼 앞서 학습했던 다층 퍼셉트론(MLP - Deep way)에 입력 데이터의 일부 또는 전체 데이터가 출력층에 바로 연결(Wide way)되는 부분이 추가된 것이다.
이로 인해, Wide & Deep Learning은 복잡한 패턴과 간단한 규칙을 모두 학습할 수 있다. (MLP에서는 간단한 패턴이 연속된 변환으로 인해 왜곡될 수 있다.)
1. Tensorflow의 함수형 API를 사용하여 Wide & Deep Learning을 구현해보자.
sklearn에서 제공하는 캘리포니아 주택 가격 데이터 셋을 사용해보자.
sklearn에서 제공하는 기초 함수로 데이터 셋을 분리해보자.
sklearn에서 제공하는 기초 함수로 데이터 셋의 스케일 조정을 실시해보자.
Wide model과 Deep model이 같은 데이터를 바라보는 Input이 1개인 Wide & Deep Learning Model을 만들어보자.
1.1 데이터셋 준비
# import Module
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
# 캘리포니아 주택 가격 데이터 셋 확인
Rawdict = fetch_california_housing()
Cal_DF = pd.DataFrame(Rawdict.data, columns=Rawdict.feature_names)
Cal_DF
# Data의 모든 컬럼들의 data type을 확인한다.
>>> Cal_DF.dtypes
MedInc float64
HouseAge float64
AveRooms float64
AveBedrms float64
Population float64
AveOccup float64
Latitude float64
Longitude float64
dtype: object
# Data의 모든 컬럼들의 결측값 개수를 확인한다.
>>> Cal_DF.isnull().sum()
MedInc 0
HouseAge 0
AveRooms 0
AveBedrms 0
Population 0
AveOccup 0
Latitude 0
Longitude 0
dtype: int64
데이터 셋은 모두 소수(float64)로 구성되어 있다.
결측 값은 모든 칼럼에 존재하지 않는다.
1.2 데이터셋 분리
>>> X_train_all, X_test, y_train_all, y_test = train_test_split(Rawdict.data, Rawdict.target, test_size = 0.3)
>>> X_train, X_valid, y_train, y_valid = train_test_split(X_train_all, y_train_all, test_size = 0.2)
>>> print("Train set shape:", X_train.shape)
>>> print("Validation set shape:", X_valid.shape)
>>> print("Test set shape:", X_test.shape)
Train set shape: (11558, 8)
Validation set shape: (2890, 8)
Test set shape: (6192, 8)
sklearn.model_selection.train_test_split(array, test_size, shuffle): dataset을 쉽게 나눌 수 있는 sklearn 함수로 일반적으로 dataset, label 이 두 array를 동시에 넣고 사용한다.
test_size: test Dataset의 비율(float)이나 총 숫자(int)로 나눠준다.
Input 객체 생성: Input layer는 배치 크기를 포함하지 않는, array의 모양을 정한다. 즉, Data의 크기가 아닌, 한 Row의 Data의 모양만 반영된다. 예를 들어, shape = (32,)가 되면, 32차원의 벡터가 입력된다는 의미다. (변수 이름에 _가 들어간 것은 파이썬에서 언더스코어(_)의 기능을 이용한 것으로, 단순하게 input함수와 충돌되지 않도록 이렇게 만든 것이다.)
은닉층 객체 생성: 기존처럼 Layer를 add로 만들어진 모델에 은닉층을 쌓는 것이 아닌, 함수로 만들어 변수에 담는다. 여기서 케라스에서 층이 연결될 방법만 선언하였고, 그 어떤 데이터 처리도 발생하지 않은 상태이다.
결합층 객체 생성: Wide-Deep Learning은 선형 모델과 딥러닝 모델을 동시에 사용하는 방법이므로, 입력될 객체인 input_과 hidden2를 연결해준다.
출력층 객체 생성: 결합층에서 전달된 내용을 출력함
모델 생성: 입력과 출력이 지정된 Keras 모델 생성
tf.keras.layers.Concatenate(): 연결층이 Tensor를 연결하는 방법은 아래와 같다.
tf.keras.layers.Concatenate()는 np.concatenate() 함수와 동일한 역할을 하며, axis를 어떻게 잡느냐에 따라, 출력되는 Tensor의 모양을 다르게 할 수 있다.
3. 모델 학습 및 최종 코드 정리
지금까지 작성했던 코드와 이전에 사용했던 괜찮은 기능들을 합쳐 코드를 정리해보자.
# Import Module
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import callbacks
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import (Input, Dense, Concatenate)
지금까지 Input layer가 1개인 Wide & Deep Learning model을 만들어보았다. 그러나, Wide & Deep Learning model의 가장 큰 특징은 Input 되는 층이 지금까지처럼 1개의 동일한 Layer가 아니라, 암기(Linear Learning)를 위한 데이터와 일반화(Deep Learning)를 위한 데이터가 Input 될 층을 따로 구성될 수 있다는 것이다.
다음 포스트에서는 Input layer가 2개인 경우에 대하여 Wide & Deep Learning model을 만들어보면서, Wide & Deep Learning model에 대해 더 알아보도록 하자.
꽤 많은 블로그나 책에서 머신러닝을 다룰 때, 회귀모형, 로지스틱 회귀모형을 꼭 다루고 넘어가는데, 이번 포스트에서는 우리가 통계학에서 흔히 다루는 회귀모형과 딥러닝이 대체 어떤 관계길래 다들 회귀모형부터 다루는지에 대해 알아보고자 한다.
사실 우리는 이미 이전 포스트에서 회귀모형, 로지스틱 회귀모형을 만들어보았으며, 만약, 통계에 조금 익숙한 사람이라면, 분석된 결과나 그 과정을 보면서, 이게 회귀분석 아닌가? 하는 생각이 들었을지도 모른다(물론, Odd Ratio, $R^2$과 같은 익숙한 지표들이 그대로 등장하진 않았지만, 그것과 유사한 역할을 하는 지표를 이미 봤을 것이다).
회귀식은 퍼셉트론 공식과 아주 똑 닮았다("머신러닝-2.1. 퍼셉트론(2)-논리회로"). 그리고 딥러닝을 통해 우리는 각각의 파라미터(가중치와 편향)를 찾아낼 수 있다.
독립변수(Dataset이자 상수)의 변화에 따른 종속변수(Label, 상수)의 변화를 가장 잘 설명할 수 있는 계수(weight과 bias)를 찾아내는 것은 회귀분석이며, 이 점이 다층 퍼셉트론을 이용하여, 데이터 자체를 가장 잘 설명할 수 있는 파라미터를 찾아내는 딥러닝(Deep Learning)과 같다고 할 수 있다.
1.1. 이 밖의 회귀모형의 특징
회귀모형은 기본적으로 연속형 데이터를 기반으로 한다.
독립변수, 종속변수가 모두 연속형 데이터여야 한다.
연속형 데이터가 아닌 독립변수 존재 시, 이를 가변수(Dummy variable)로 만든다.
2. 데이터셋
이번 학습에서는 R을 사용해본 사람이라면 아주 친숙한 데이터 중 하나인 자동차 연비 데이터(MPG)를 이용해서 회귀모형을 만들어보도록 하겠다.
# Import Module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
>>> dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
Downloading data from http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data
32768/30286 [================================] - 0s 4us/step
tf.keras.utils.get_file()을 사용하면, 각종 데이터셋을 쉽게 가져올 수 있다.
데이터셋을 가지고 오는 곳은 UCI 머신러닝 저장소로 인터넷이 안 되는 환경이라면 데이터를 다운로드할 수 없으니, 조심하자.
sklearn처럼 데이터셋을 Dictionary에 깔끔하게 저장하여, 데이터를 다운로드하면, 모든 데이터에 대한 정보가 있는 상태가 아니므로, 데이터에 대해 파악하기 위해선 UCI 머신러닝 저장소에서 데이터에 대해 검색하여, 데이터 정보를 찾아봐야 한다.
전체 데이터에서 결측 값 행의 비율을 보니 0.015로 매우 미미한 양이므로, 제거하도록 하자.
Rawdata.dropna(inplace = True)
3.2. 범주형 데이터의 원-핫 벡터화
칼럼 Origin은 숫자로 표시되어 있지만, 실제론 문자인 범주형 데이터이므로, 원-핫 벡터화 해주자. (이는 회귀 모델에서의 가변수 처리와 매우 유사한 부분이라고 할 수 있다.)
# One-Hot Vector 만들기
def make_One_Hot(data_DF, column):
target_column = data_DF.pop(column)
for i in sorted(target_column.unique()):
new_column = column + "_" + str(i)
data_DF[new_column] = (target_column == i) * 1.0
이전 참고 포스트에서 만들었던, 원-핫 벡터 코드보다 판다스의 성격을 잘 활용하여 만든 코드다
DataFrame.pop(column): DataFrame에서 선택된 column을 말 그대로 뽑아낸다. 그로 인해 기존 DataFrame에서 해당 column은 사라지게 된다.
(target_column == i) * 1.0: Boolearn의 성질을 사용한 것으로 target_column의 원소를 갖는 위치는 True로, 원소가 없는 곳은 False가 된다. 이에 1.0을 곱하여 int로 바꿔줬다. Python은 동적 언어이므로, 1.0을 곱해주어도 int형으로 변하게 된다.
3.3. 데이터셋 분리
train set과 test set은 7:3으로 분리하도록 하겠다.
validation set은 이 단계에서 뽑지 않고, 학습 과정(fit)에서 뽑도록 하겠다.
위 그래프는 우리가 이전에 만들었던 matplotlib.pyplot으로 뽑았던 결과보다 자세한 결과를 보여준다. train_set과 validation_set이 다른 경향을 보여주는 부분을 크게 확대해서 보여주었다.
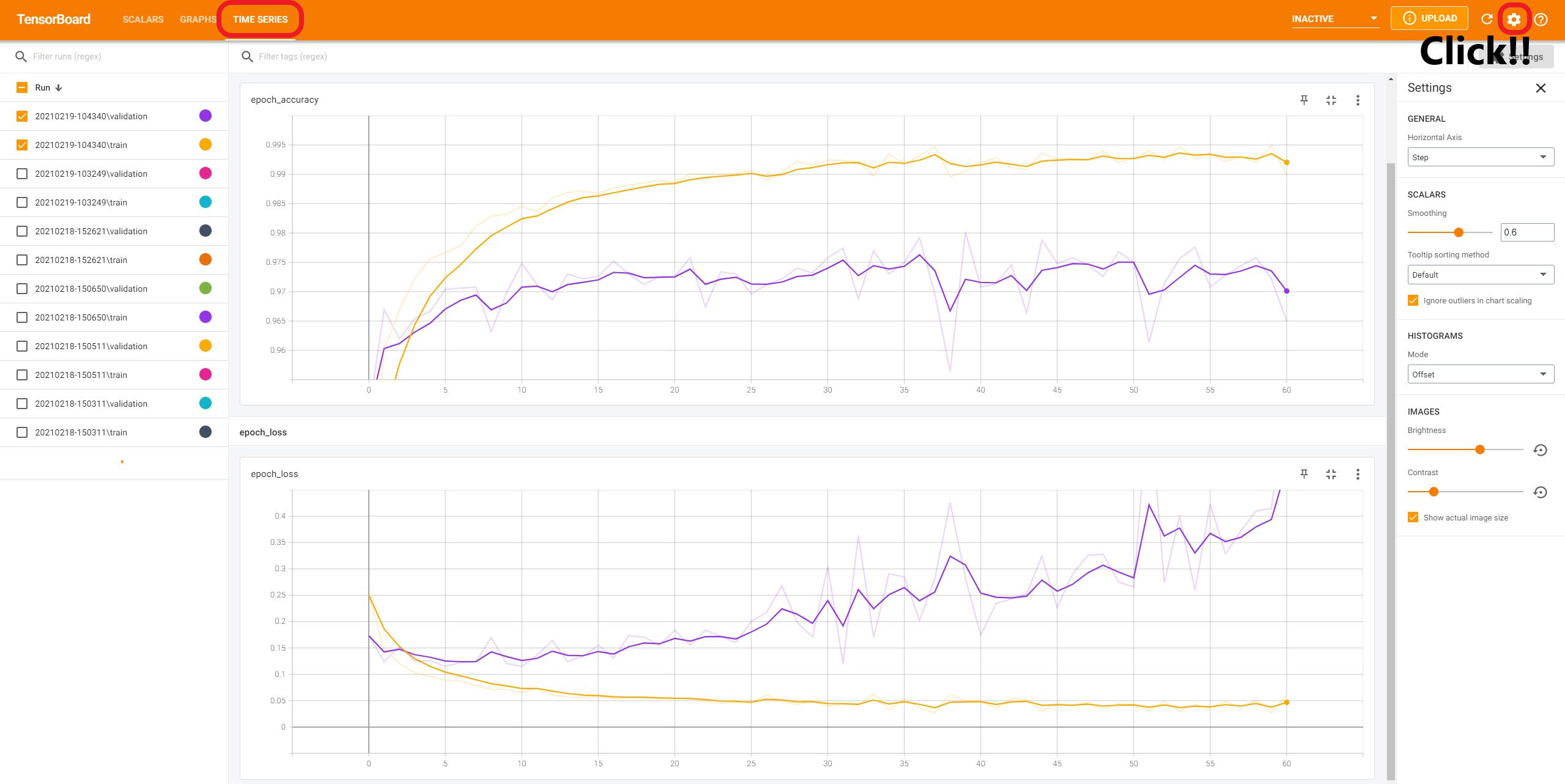
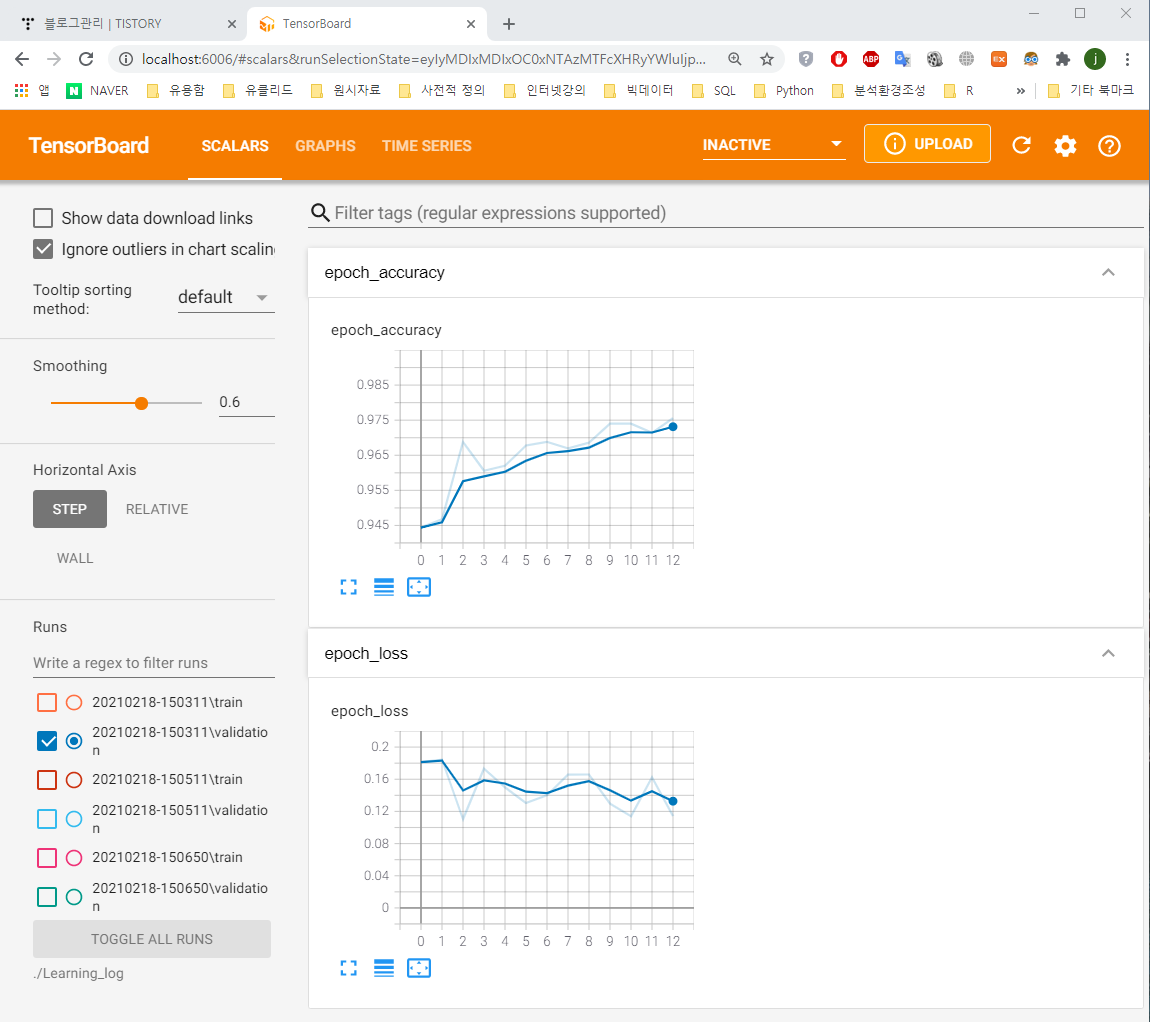
그래프를 보면 연한 파란색과 빨간색 그래프가 희미하게 있는 것을 볼 수 있는데, 이 희미한 그래프는 실제 값이고, 이를 부드럽게 만든 것이 우리가 보고 있는 진한 파란색, 빨간색 그래프다. 이 부드러운 정도는 좌측의 "Smoothing" 바를 움직여서 조절할 수 있다.
위 그래프에서 epoch_accuracy는 epoch별 accuracy의 변화를 보여준다. epoch_loss는 epoch별 loss의 변화를 보여준다.
위 그래프를 보면, train set에 대한 학습 과정을 보여주는 파란색은 epoch가 지날수록 train set에 최적화되어 가므로, 지속적으로 증가하거나 감소하는 것을 볼 수 있으나, valiation set인 빨간색은 accuracy에서는 증가하다가 감소하는 부분이 생기고, loss에서는 accuracy보다 더 큰 폭으로 출렁이다가, epoch 11을 최솟값으로 지속적으로 증가하는 것을 볼 수 있다.
해당 모델은 조기종료를 사용하였으며, 조기종료에서의 patience 파라미터를 10으로 주어, 최솟값이 등장한 이후 10만큼 추가 epoch를 실시해, 그 안에 보다 작은 최솟값이 등장하지 않는다면, 학습을 멈추게 하였다.
2. GPAPHS
좌측 상단의 SCALARS 옆에 있는 GRAPHS를 클릭하면, 다음과 같은 화면이 뜬다.
이는 노드와 엣지 등을 이용하여, 그래프로 학습이 일어난 과정을 시각화한 것이다.
위 내용을 보면, 무언가 처음 보는 것이 엄청 많기 때문에 이해하기가 쉽지 않다.
우리가 모델을 만들 때, 사용했었던 Sequential 쪽으로 마우스를 드래그하고, 휠을 스크롤하여, 큰 화면으로 만들어보면, sequential 우측 상단에 + 마크가 있는 것을 확인할 수 있다. 이를 더블 클릭해보자.
이를 보면 우리가 모델을 만들 때 사용했던, Flatten, Hidden1, Hidden2, Hidden3, Output layer가 등장하는 것을 알 수 있다.
Hidden1, Hidden2, Hidden3는 모델을 생성할 때, name 파라미터를 이용해서 부여한 이름이다.
모서리가 둥근 직사각형을 클릭하면 그 안에 요약되어 있는 내용들을 볼 수 있다.
이를 이용해서 모델의 각 부분에서 어떻게 학습이 이루어졌는지 확인할 수 있다.
3. TIME SERIES
TIME SERIES에서는 실시간으로 그래프의 변화를 볼 수 있다.
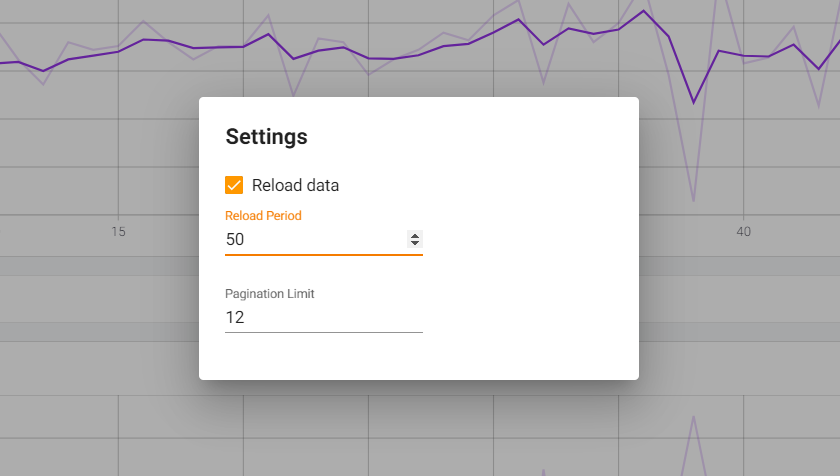
먼저, Setting을 손봐서, 그래프 자동 Update 시간을 바꾸자.
Reload Period는 자동 Update 시간으로 TensorBoard로 볼 데이터의 크기 학습 시간 등을 고려하여 설정해야 한다. 최소 시간은 15초이므로, 15로 설정하도록 하겠다.
텐서플로우가 익숙하지 않은 사람은, 텐서플로우로 코드를 짜는 과정에서 시각적으로 보이는 것이 많지 않고, 보이는 부분도 이해하기 쉽지 않다 보니, 자신이 모델을 만들고, 학습을 시켰음에도 정확히 자신이 무엇을 했고, 문제가 발생한다 할지라도 왜 문제가 발생했는지 이해하기 어려울 수 있다.
이 때 필요한 것이 시각화 도구인 Tensorboard로, 이전 포스팅에서 우리가 학습이 종료된 후, matplotbib.pyplot을 이용해 시각화를 했던 것과 달리, 텐서보드는 훈련하는 도중에도 실시간 시각화를 할 수 있다.
Tensorboard는 텐서플로우뿐만 아니라 파이토치(Pytorch)에서도 사용 가능하므로, 그 사용법을 꼭 익히도록 하자.
1. Tensorboard의 기능
텐서보드는 주로 시각화 기능을 제공하지만, 그 외에도 간단한 통계 분석, 자동 클러스터링 등 다양한 편의 기능을 제공한다. 다음 내용은 Tensorflow 홈페이지에서 이야기하는 텐서보드의 대표적인 기능이다(텐서플로우 공식 홈페이지).
손실 및 정확도 같은 측정 도구 추적 및 시각화
모델 네트워크 시각화
시간의 경과에 따른 가중치, 편향, 기타 텐서의 히스토그램의 변화
저차원 공간에 임베딩 투영
이미지, 텍스트, 오디오 데이터 표시
TensorFlow 프로그램 프로파일링
TensorBoard.dev를 사용하여 실험 결과를 쉽게 호스팅, 추적 및 공유 가능
위 내용을 보면, 텐서보드가 머신러닝을 사용하기 위해 반드시 필요한 존재인 것은 아니지만, 텐서보드가 제공하는 다양한 기능을 통해서 보다 정확하고, 편리하게 기계학습을 진행할 수 있다는 것을 알 수 있다.
지금까지의 포스팅에서는 학습을 하기 위해 데이터가 어떻게 생겼고, 손실 값과 정확도를 추적하는 과정에서 새로운 함수를 만들거나, 다른 라이브러리의 기능을 가져와서 구현했으나, 텐서보드를 사용하면 이보다 쉽게 더 강력한 결과를 볼 수 있다.
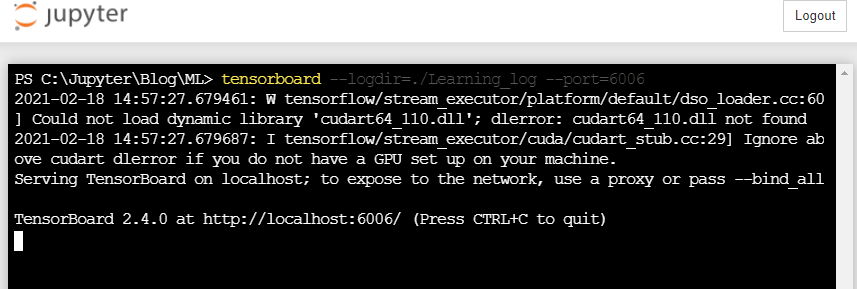
2. Tensorboard 디렉터리 세팅하기
Tensorboard는 Tensorflow 설치 시, 자동으로 설치가 되고, 우리가 지금까지 사용했던 keras에서도 Tensorboard를 지원하기 때문에 따로 Tensorboard를 설치하지 않고도 사용할 수 있다.
Tensorboard는 시각화하고자 하는 Log 데이터를 모아야 한다.
텐서보드는 Log 데이터가 쌓이는 디렉터리를 모니터링하고, 자동으로 변경된 부분을 읽어 그래프를 업데이트한다.
위 기능으로 인해 Tensorboard는 실시간 데이터를 시각화할 수 있으나, 약간의 지연이 생기게 된다.
2.1. Log Data가 저장될 디렉터리 경로 만들기
import os
# Log data를 저장할 디렉터리 이름 설정
dir_name = "Learning_log"
# main 디렉터리와 sub 디렉터리 생성 함수
def make_Tensorboard_dir(dir_name):
root_logdir = os.path.join(os.curdir, dir_name)
sub_dir_name = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
return os.path.join(root_logdir, sub_dir_name)
os 모듈: 운영 체제와 상호 작용을 할 때, 사용하는 Python 기본 모듈로, Python 안에서 끝내는 것이 아닌 자신의 컴퓨터와 어떠한 작업을 하고자 한다면, 해당 모듈을 필수로 사용하게 된다.
os.curdir: 현재 디렉터리를 가지고 온다.
os.path.join('C:\Tmp', 'a', 'b'): 주어진 경로들을 합쳐서 하나로 만든다.
dir_name은 Tensorboard가 바라 볼 디렉터리의 이름이다.
코드 실행 시, 생성된 로그 데이터가 섞이지 않도록, dir_name 디렉터리 아래에 현재 날짜와 시간으로 하위 디렉터리의 경로를 만들어낸다.
3. Log를 생성해보자.
이전 TensorFlow를 학습할 때, 만들었던 모델을 가져와서 실행해보도록 하자.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout, Flatten)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import os
import datetime
지금까지 텐서보드를 사용하기 위해, Log 디렉터리를 생성하고, 텐서보드를 실행하는 방법에 대해 알아보았다. 다음 포스트에서는 텐서보드를 사용해서 훈련 셋(Train set)과 검증 셋(Validation set)의 손실 값(loss)과 정확도(accuracy)를 평가하는 방법에 대해 알아보도록 하자.
지금까지 tensorflow.keras를 사용해서 일어나는 전반적인 과정에 대해 천천히 살펴보았다. 모델 평가는 하이퍼 파라미터 최적화(Hyper Parameter optimization)의 개념으로 들어가게 되면, 그 양이 꽤 길어지므로, 거기까진 나중에 따로 들어가도록 하겠다.
이번 포스트에서는 지금까지 학습했던 내용들을 정리하고, .evaluate() 함수로 지금까지 만들었던 모델의 성능을 평가한 후, 모델을 저장 및 불러오기를 해보도록 하겠다.
1. 학습 코드 최종 정리 및 모델 평가
# Import module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout, Flatten)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
지금까지 이미지 분류 모델을 만들고, 학습까지 시켜보았다. 지난 포스트에서는 학습 과정을 보며, 학습이 제대로 이루어졌는지를 평가하고, 최적의 epochs를 결정하는 방법에 대해 공부해보았다.
그러나, 지금 같이 데이터의 양이 작고, epochs가 상대적으로 적은 경우엔 학습이 완전히 끝난 후 그래프를 그려서 학습 과정을 살필 수 있었지만, 만약에 epochs가 1,000 이거나 데이터의 크기가 1,000만 개를 가뿐히 넘겨 학습 시간이 길어지는 경우라면, 이전에 했던 방법으로 접근해서는 안된다.
이때, 등장하는 개념이 바로 조기 종료다.
조기 종료(Early Stopping)
0. 선행 코드
# Import module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout, Flatten)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
조기 종료를 사용하면, 별도의 과정 없이, 손쉽게 최적의 epochs를 찾아낼 수 있으므로, 오차 역전파법을 찾아내 지금의 딥 러닝을 있게 한 1등 공신 중 한 명인 제프리 힌턴은 조기 종료를 "훌륭한 공짜 점심(beautiful free lunch)"이라고 불렀다고 한다.
이외에도 콜벡에는 학습 중간에 자동 저장을 하는 ModelCheckPoint나 학습률을 스케쥴링하는 LearningRateSchedule 등 유용한 기능이 많다. 관심 있는 사람은 다음 아래 사이트를 참고하기 바란다. (keras.io/ko/callbacks/)
이전 포스트에서 모델을 학습시키는 것에 대해 알아보았다. 기존 포스팅에서는 학습을 시키고, 이를 가만히 기다리기만 했었는데, 이 학습 과정에서 발생하는 Log를 분석할 수 있다면, 언제 학습을 멈춰야 할지, 과적합이 발생하였는지 등을 정보다 정확히 알 수 있다. 이번 포스팅에서는 학습과정을 확인하는 방법에 대해 알아보도록 하겠다.
학습과정 확인(History)
0. 이전 코드 정리
# Import module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout, Flatten)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
model.fit()는 History 객체를 반환하며, 이 것이 바로 fit()을 실행하면 반환되는 출력 Log이다.
출력되는 값은 model.compile을 할 때, metrics를 어떻게 지정하느냐에 따라 달라진다.
가장 일반적으로 사용되는 accuracy를 넣고, validation data를 넣으면, loss, accuracy, val_loss, val_acc가 출력되게 된다.
이는 매 에포크마다의 모델을 평가하는 점수라고 할 수 있으며, 그 뜻은 다음과 같다.
loss: 훈련 셋 손실 값
accuracy: 훈련 셋 정확도
val_loss: 검증 셋 손실 값
val_acc: 검증 셋 정확도
만약 검증 셋을 추가하지 않는다면 val_loss, val_acc가 출력되지 않으며, metrics에서 accuracy를 지정하지 않는다면, accuracy도 출력되지 않는다.
2. History 데이터를 다뤄보자.
# history를 출력시켜보자.
>>> history
<tensorflow.python.keras.callbacks.History at 0x20f001a1d00>
history를 출력시켜보면, <tensorflow.python.keras.callbacks.History at ~~~~~>와 같은 이상한 문자가 출력된다. Python에서는 이를 객체라 부르며, 해당 객체에 다양한 함수를 이용하여 학습과정에서 발생한 다양한 정보를 볼 수 있다.
예를 들어, history.epoch를 입력하면, 전체 epoch를 list로 출력하며, history.params 입력 시, 훈련 파라미터가 반환된다.
우리에게 필요한 것은 history.history로, 이 데이터는 한 에포크가 끝날 때마다 훈련 셋과 검증 셋을 평가한 지표들이 모여 있는 것이다.
# history.history는 각 지표들이 담겨있는 dictionary다
>>> type(history.history)
dict
# history.history의 생김새는 다음과 같다.
>>> history.history
{'loss': [1.1046106815338135,
0.32885095477104187,
0.2113472819328308,
0.1513378769159317,
0.11605359613895416,
0.09276161342859268,
...
0.9787999987602234,
0.9789999723434448,
0.9789999723434448,
0.979200005531311,
0.979200005531311]}
# 꺾은선 그래프를 그리자.
# 그래프의 크기와 선의 굵기를 설정해주었다.
history_DF.plot(figsize=(12, 8), linewidth=3)
# 교차선을 그린다.
plt.grid(True)
# 그래프를 꾸며주는 요소들
plt.legend(loc = "upper right", fontsize =15)
plt.title("Learning Curve", fontsize=30, pad = 30)
plt.xlabel('Epoch', fontsize = 20, loc = 'center', labelpad = 20)
plt.ylabel('Variable', fontsize = 20, rotation = 0, loc='center', labelpad = 40)
# 위 테두리 제거
ax=plt.gca()
ax.spines["right"].set_visible(False) # 오른쪽 테두리 제거
ax.spines["top"].set_visible(False) # 위 테두리 제거
시각화를 해서 4개 지표의 변화 추이를 보았다.
위 그래프의 결과를 해석해보면 다음과 같다.
훈련 셋과 검증 셋의 그래프가 비슷한 형태를 보였다. 이는 과적합(Overfitting)이 되지 않았다는 것을 의미한다.
훈련 셋, 검증 셋의 Accuracy는 1을 향해 상승하였다. loss는 0을 향해 하강하는 형태를 보였다. 이는 안정적으로 학습을 하고 있는 것을 의미한다.
훈련 셋, 검증 셋의 Accuracy와 loss는 epoch 20부터 수렴하기 시작했다.
검증 셋의 loss는 epoch가 20을 넘는 순간부터 소폭 증가하는 형태를 보였다.
검증 셋의 손실 값이 최저값을 약 epoch 20에서 달성하였으므로, 모델이 완전히 수렴하였다고 할 수 있다.
기존에 epochs을 100으로 설정하였으나, loss와 accuracy가 수렴한 지점을 볼 때, 이는 과하게 큰 값임을 알 수 있다. epochs를 30으로 줄여서 다시 학습을 해보도록 하자.
epoch가 불필요하게 큰 경우, 리소스의 낭비가 발생하기도 하지만, 과적합(Overfitting)이 될 위험이 있으므로, 적합한 epoch에서 학습을 해주는 것이 좋다.
epoch가 커지면 커질수록 훈련 셋의 성능은 검증 셋의 성능보다 높게 나온다. 검증 셋의 손실(var_loss)의 감소가 아직 이루어지고 있는 상태라면, 모델이 완전히 수렴되지 않은 상태라 할 수 있으므로, 검증 셋 손실의 감소가 더 이상 이루어지지 않을 때 까진 학습을 해야 한다.
epochs를 30으로 하여 다시 학습해보자.
history = model.fit(train_images, train_labels,
epochs=30,
batch_size=5000,
validation_data=(valid_images, valid_labels))
history_DF = pd.DataFrame(history.history)
# 꺾은선 그래프를 그리자.
# 그래프의 크기와 선의 굵기를 설정해주었다.
history_DF.plot(figsize=(12, 8), linewidth=3)
# 교차선을 그린다.
plt.grid(True)
plt.legend(loc = "upper right", fontsize =15)
plt.title("Learning Curve", fontsize=30, pad = 30)
plt.xlabel('Epoch', fontsize = 20, loc = 'center', labelpad = 20)
plt.ylabel('Variable', fontsize = 20, rotation = 0, loc='center', labelpad = 40)
# 위 테두리 제거
ax=plt.gca()
ax.spines["right"].set_visible(False) # 오른쪽 테두리 제거
ax.spines["top"].set_visible(False) # 위 테두리 제거
위 그래프를 보면 검증 셋이 연습 셋 보다 더 빠르게 0과 1로 다가가는 것으로 오해할 수 있으나, 훈련 셋의 지표는 epoch 도중에 계산되고, 검증 셋의 지표는 epoch 종료 후 계산되므로, 훈련 곡선을 왼쪽으로 소폭(에포크의 절반만큼) 이동시켜야 한다.
혹시나 해서 하는 말이지만, 모델이 생성된 후에 다시 학습을 하려면, 커널을 재시작해서 모델의 파라미터를 초기화시키고 학습해야 한다. Tensorflow는 이미 학습이 되어 파라미터가 생긴 모델을 재학습 시키면, 기존의 파라미터를 감안하여 학습을 하게 된다.
[참고 서적]
지금까지 모델 학습 과정에서 발생한 history 객체를 이용해서, 학습 셋과 검증 셋의 지표들을 시각화하고, 과적합이 발생하였는지, 적합한 epochs이 얼마인지 탐색해보았다.
간단하게 검증 셋과 학습 셋의 그래프가 비슷한 경향을 보이면 과적합이 일어나지 않고 있다는 것을 의미하며, 0과 1에 수렴하지 못한다면, 하이퍼 파라미터가 주어진 데이터셋에 맞지 않다는 것을 의미한다. 또한 epochs가 수렴 이후에도 지속되는 경우, 연습 셋에 과적합 될 수 있으므로, 적당한 epochs를 설정하는 것이 중요하다.
그러나, 꼭 위 방법처럼 epoch를 갱신해서 다시 학습을 해줘야 하는 것은 아니다. 다음 포스트에서는 epoch가 아직 남았더라도, 조건을 만족하면 알아서 학습을 멈추는 조기 종료에 대해 알아보도록 하겠다.