
편차(Deviation)
◎ 편차(Deviation): 관측값들이 특정값(평균)으로부터 떨어진 정도(거리)이다.
$$ Dev = x_i - \mu $$
- 이전 포스트에서 학습하였던, 범위, 사분위간 범위는 관측값 간의 간격을 사용해 산포도를 나타냈다. 이번에는 평균과 관측값의 차이인 편차(Deviation)를 이용해 산포도를 나타내는 방법에 대해 알아보겠다.
- 편차를 이용해 산포도를 나타내는 방법은 분산(Varience), 표준 편차(Stadard deviation), 절대 편차(Absolute deviation), 변동 계수(Coefficient of variation) 등이 있다.
- 편차는 양수, 음수 모두 가능하며, 평균보다 크면 양수, 작으면 음수가 된다.
- 편차의 크기는 관측값이 평균으로부터 떨어진 거리를 말한다.
- 모집단 평균에서의 편차는 오류(Error)라고 하며, 표본 집단 평균에서의 편차는 잔차(Observed value)라고 한다.
1. 분산(Varience)과 표준편차(Standard Deviation)
◎ 분산(Varience): 편차 제곱의 평균으로, 평균으로부터 관찰값들이 떨어진 거리의 제곱 평균이다.
◎ 표준편차(Standard Deviation): 분산의 양의 제곱근이다.
- 중심경향치에서 평균이 제일 많이 쓰이듯, 산포도에서 제일 많이 쓰이는 분산과 표준편차가 나오게 된 개념은 편차의 평균을 구하려는 시도에서 시작되었다.
- 편차는 각 관측값이 평균으로부터 떨어진 거리이므로, 그 평균을 알 수 있다면, 관측값들이 평균으로부터 떨어진 정도를 한 값으로 알 수 있다.
- 편차 평균의 공식은 다음과 같다.
$$\frac{1}{N}\sum (x_i - \mu)$$
- 그러나, 위 공식은 무조건 결괏값이 0이 나온다.

- 모든 편차의 합이 0이 되는 것을 막기 위해, 편차에 제곱을 해줘서 모든 편차를 양수로 만들고, 이의 평균을 구한 것이 바로 분산(Varience)이다.
- 본래 우리가 구하고자 했던 값은 편차의 평균이었다. 그러나, 편차의 합은 0이 나오기 때문에 제곱을 해주었고, 그로 인해 편차의 증폭과 단위의 제곱이 일어났다.
- 위 문제를 해결하고자, 분산에 양의 제곱근을 씌워, 제곱으로 인한 편차의 증폭과 단위를 원상 복귀하고자, 분산에 양의 제곱근을 씌운 것이 표준편차(Standard deviation)다.
2. 모집단과 표본집단의 분산과 표준편차
- 분산의 모수와 통계량은 계산 방법과 표기 방법이 달라진다.
- 모집단의 분산과 표준편차
모집단의 분산: $\sigma ^2 = \frac{\sum(X_i - \mu)^2}{N}$
모집단의 표준편차: $\sigma = \sqrt{\frac{\sum(X_i - \mu)^2}{N}}$
- 표본집단의 분산과 표준편차
표본집단의 분산: $S ^2 = \frac{\sum(X_i - \bar{X})^2}{n-1}$
표본집단의 표준편차: $S = \sqrt{\frac{\sum(X_i - \bar{X})^2}{n-1}}$
- 단순 기술통계량을 구할 땐, 모집단의 분산과 표준편차를 구하는 방식으로 하면 된다.
- 관찰 값들의 차이가 클수록 편차가 커지므로, 분산 $\sigma^2$은 커진다.
- 분산은 편차의 제곱이므로, 평균으로부터 멀어질수록 그 차이가 증폭되게 된다.
- 분산은 편차의 제곱이므로, 단위 역시 제곱된다.
- 위 문제를 해결하기 위해 양의 제곱근을 씌워서 표준편차를 만든다.
3. 표본 분산에 $(n-1)$을 나눠주는 이유.
표본 분산에 $(n-1)$을 나눠주는 이유는 꽤 복잡하기 때문에 기초통계학에서는 이를 다루지 않는다. 그러나, 이 부분을 그냥 넘어가게 된다면, 앞으로 이와 비슷한 경우가 등장할 때마다, 수식을 이해하는 것이 아닌, 수식을 암기만 하고 넘어갈 위험이 있다.
표본 분산에 $(n-1)$을 나눠준 이유를 알기 위해서는 먼저 "자유도(Degree of freedom)"라는 개념에 대해 알아야 한다. 자유도의 개념은 꽤나 모호하고, 국내에서는 이를 명확히 설명하는 글을 찾기 어렵다. 위키피디아 영문판에서는 자유도를 무엇인지 대략적인 개념을 이해해보자.
3.1. 자유도(Degree of freedom)
◎ 자유도(Degree of freedom):
- In statistics, the number of degrees of freedom is the number of values in the final calculation of a statistic that are free to vary.
("Degrees of Freedom". Glossary of Statistical Terms. Animated Software. Retrieved 2008-08-21.) - Estimates of statistical parameters can be based upon different amounts of information or data. The number of independent pieces of information that go into the estimate of a parameter are called the degrees of freedom. In general, the degrees of freedom of an estimate of a parameter are equal to the number of independent scores that go into the estimate minus the number of parameters used as intermediate steps in the estimation of the parameter itself
(Lane, David M. "Degrees of Freedom". HyperStat Online. Statistics Solutions. Retrieved 2008-08-21.) - 출처: en.wikipedia.org/wiki/Degrees_of_freedom_(statistics)
위 자유도의 정의를 해석해보면, 자유도는 다음과 같은 성질을 갖는다.
- 통계의 최종 계산에서 자유롭게 변경 가능한 값의 개수
- "통계의 매개 변수의 추정치(Estimates of statistical parameters)"는 정보나 데이터에서 다른 값의 개수를 기반으로 하며, 매개 변수 추정치에 들어가는 독립적인 정보의 수를 자유도라 한다.
일반적으로, 모수 추정의 자유도는 추정에 들어가는 독립된 값의 개수에 모수 추정의 중간 단계로 사용되는 모수의 수를 뺀 값과 같다.
위 내용을 보다 쉽게 풀어써보면 다음과 같다.
- 자유도는 독립된 값의 개수와 이를 통해 모수를 추정할 때, 사용되는 결정된 정보의 수를 뺀 것으로, 더 쉽게 말하면, 독립적인 미지수의 개수에 그 독립적인 미지수에 의해 자동으로 결정되어 버리는 값의 수를 빼는 것이다.
- 표본집단의 각 원소는 완전 무작위 표본 추출 방법으로 복원 추출하여 실시한다면, 각 원소는 독립적이지만, 그 독립된 원소들이 결정되면, 평균, 표준편차 등의 통계량들은 자동으로 결정되므로, 이들 통계량은 독립적이지 않다고 할 수 있다.
- 그러므로, 자유도는 표본 집합의 원소의 수에 모수 추정 과정에서 표본 집합이 결정되면, 자동으로 결정되는 평균, 표준편차와 같은 파라미터의 개수를 빼서 구하게 된다.
3.2. 자유도를 사용해서 표본 분산을 계산하는 이유
- 표본집단은 모집단에 비해, 표본의 수가 매우 적으므로, 데이터가 편향(Bias)되어 있다.
- 편향되어 있기 때문에 표본집단의 크기는 모집단의 크기보다 작으며, 이를 보정하여, 통계량의 값을 크게 만들어줘서 불편추정량(Unbiased estimate)으로 만들어줘야 한다.
- 이때, 독립적인 정보의 수인 n이 아니라, 자유도로 나눠준다면, 표본 집단의 통계량의 기댓값이 모집단의 통계량의 기댓값과 같아져 불편추정량이 된다.
- 다른 값이 아니라 자유도를 사용하는 이유는, 자유도로 나눴을 때, 불편추정량이 만들어지기 때문이며, 이는 최소분산불편추정량(Uniformaly Minimum Variance Unbiased Estimator, UMVUE)를 통해 증명할 수 있다.
- 모 분산과 표본 분산의 기댓값에 대하여, 표본 분산을 자유도로 나눴을 때, 어떤 결과가 나오는지 보도록 하자.


- 위 결과를 보듯, 표본 분산의 기댓값은 $n$이 아니라, 자유도인 $n-1$로 나눴을 때, 모분산과 같게 된다.
- 그러므로, 표본 분산에는 $n$이 아닌 자유도 $n-1$로 나눠줘야 한다.
3.3. 자유도를 무시하는 경우
- 위 자유도의 개념을 알고 나니, 표본 집단을 이용하여, 모집단을 추정할 때는 불편추정량을 만들어주기 위해, 자유도의 개념이 필요하다는 것을 알 수 있다.
- 그러나, 위 개념을 모르는 상태에서 현장에서 데이터 분석을 해본 사람들은 지금까지 큰 문제가 없었을 것인데, 이는 앞서 말했던, 불편추정량이 생기는 원인 때문이다.
- 불편추정량은 표본 집단의 양이 작기 때문에 생기는 현상인데, 만약 표본 집단의 양이 매우 많다면 어떻겠는가
- 자 표본 분산을 구하는데, 표본 집단의 크기가 10개라고 생각해보자, 자유도 9와 원래 값인 10은 꽤 큰 차이가 있다. 그러나 표본 집단의 크기가 10,000개라고 해보자, 10,000개와 9,999개는 거의 차이가 없다.
- 즉, 표본의 크기가 매우 크다면, 자유도를 무시하고 n으로 계산해도 아무 문제가 없다.
4. 파이썬으로 표준편차를 구해보자.
위에서 봤던, 표준편차와 분산의 개념과 달리 파이썬으로 표준편차를 구하는 것은 매우 쉽다. 아래 데이터를 이용해서, 양적 데이터인 "키", "몸무게"의 표준편차를 뽑아보도록 하자.
import numpy as np
import pandas as pdRawdata = pd.read_csv("Data_for_study.csv")
4.1. 위 식대로 함수를 만들어보자
# 모 표준편차
def Pop_standard_deviation(data, column):
target_array = data[column].to_numpy()
result = np.sqrt(np.sum(((target_array - np.mean(target_array)) ** 2))/len(target_array))
return result
# 표본 표준편차
def Sample_standard_deviation(data, column):
target_array = data[column].to_numpy()
result = np.sqrt(np.sum((target_array - np.mean(target_array)) ** 2)/(len(target_array)-1))
return result# 키의 모표준편차
>>> Pop_standard_deviation(Rawdata, "키")
8.589382382344954
# 키의 표본표준편차
>>> Sample_standard_deviation(Rawdata, "키")
8.589459420964639
# 데이터의 크기
>>> len(Rawdata)
55748- 데이터의 크기가 55,784로 꽤 크다 보니, 모표준편차와 표본표준편차가 거의 유사하다는 것을 알 수 있다.
4.2 Pandas와 Numpy를 사용하여 표준편차를 구하자.
# pandas 함수로 구하기
>>> Rawdata.키.std()
8.589459420964502
>>> Rawdata.몸무게.std()
12.935373134509032
# numpy 함수로 구하기
>>> np.std(Rawdata.키.to_numpy())
8.589382382344954
>>> np.std(Rawdata.몸무게.to_numpy())
12.9352571175121- pd.Series.std(): 시리즈의 value를 대상으로 표준편차를 구한다. - 표본표준편차
- np.std(array): 배열을 대상으로 표준편차를 구한다. - 모표준편차
- 몸무게의 표준편차가 키의 표준편차보다 크므로, 몸무게의 데이터가 키의 데이터보다 평균에서 멀리 떨어진 것을 알 수 있다.
- 위 결과를 보면, Pandas와 Numpy의 표준편차 결과가 약간이긴 하지만, 차이가 나는 것을 알 수 있다.
- Pandas와 Numpy의 표준편차 계산 방식의 차이를 보기 위해, 표본을 아주 조금만 뽑아서 표본의 크기가 커져서, 자유도의 보정 영향력이 줄어드는 걸 줄여서 봐보자.
# 무작위로 데이터를 30개만 sampling 하자.
>>> sample_data = Rawdata.sample(30)
# 공식대로 만든 모표준편차
>>> Pop_standard_deviation(sample_data, "키")
7.172806672116262
# 공식대로 만든 표본표준편차
>>> Sample_standard_deviation(sample_data, "키")
7.295427634334816
# numpy의 std 함수
>>> np.std(sample_data.키.to_numpy())
7.172806672116262
# pandas의 std 함수
>>> sample_data.키.std()
7.295427634334816- 위 결과를 보면, numpy의 표준편차는 기본적으로 모표준편차를 구하는 공식으로 돌아가는 것을 알 수 있다.
- pandas의 표준편차는 기본적으로 표본표준편차를 구하는 공식으로 돌아간다.
- 기본적으로 numpy의 성능이 더 좋기 때문에, numpy를 사용하여 표본표준편차를 구하고자 하는 경우도 많을 텐데, numpy로 표본표준편차를 구하고자 한다면, 다음 파라미터를 추가해줘야 한다.
# numpy를 사용해서 표본표준편차 구하기
>>> np.std(sample_data.키.to_numpy(), ddof = 1)
7.295427634334816- ddof 파라미터는 자유도에서 빼 줄 독립적이지 않은 파라미터의 크기를 말한다.
- 표본 데이터를 대상으로 numpy를 연산한다면, 자유도의 존재를 잊지 말고 꼭 반영해주자.
- 물론, 데이터의 양이 굉장히 크다면, 굳이 불편추정량을 만들기 위해, 자유도로 나눠주지 않아도 괜찮다.
5. 도수분포표를 이용한 표준편차 계산
- 앞서 도수분포표를 사용해서 평균, 중앙값 등을 구했듯, 도수분포표를 사용해서 표준편차를 계산할 수도 있다.
- 앞서 말했듯, 원시자료를 가지고 있다면, 굳이 도수분포표로 표준편차를 구하지 않아도 되지만, 도수분포표밖에 없다면, 도수분포표를 사용해서 표준편차를 유추해야 한다.
- 이전에 만들었던, 연속형 데이터를 범주형 데이터로 만드는 함수를 사용해서 도수분포표를 만들고, 해당 도수분포표를 이용해서 표준편차를 추론해보자.
def make_freq_table(data, column):
"""
-------------------------------------------------------------------------------
지정된 변수의 관찰값이 20개보다 많은 경우, 10개의 등급을 가진 데이터를 반환한다.
10개의 등급은 동일한 간격으로 자른 것이다.
-------------------------------------------------------------------------------
Input: DataFrame, str
Output: DataFrame
"""
# array 생성
target_array = data[column].to_numpy()
# class의 수가 20개보다 많은 경우 10개로 줄인다.
class_array = np.unique(target_array)
if len(class_array) > 20:
min_key = class_array.min()
max_key = class_array.max()
split_key = np.linspace(min_key, max_key, 10)
a0 = str(round(split_key[0], 2)) + " 이하"
a1 = str(round(split_key[0], 2)) + " ~ " + str(round(split_key[1], 2))
a2 = str(round(split_key[1], 2)) + " ~ " + str(round(split_key[2], 2))
a3 = str(round(split_key[2], 2)) + " ~ " + str(round(split_key[3], 2))
a4 = str(round(split_key[3], 2)) + " ~ " + str(round(split_key[4], 2))
a5 = str(round(split_key[4], 2)) + " ~ " + str(round(split_key[5], 2))
a6 = str(round(split_key[5], 2)) + " ~ " + str(round(split_key[6], 2))
a7 = str(round(split_key[6], 2)) + " ~ " + str(round(split_key[7], 2))
a8 = str(round(split_key[7], 2)) + " ~ " + str(round(split_key[8], 2))
a9 = str(round(split_key[8], 2)) + " 이상"
new_index = [a0, a1, a2, a3, a4, a5, a6, a7, a8, a9]
target_array= np.where(target_array <= split_key[0], 0,
np.where((target_array > split_key[0]) & (target_array <= split_key[1]), 1,
np.where((target_array > split_key[1]) & (target_array <= split_key[2]), 2,
np.where((target_array > split_key[2]) & (target_array <= split_key[3]), 3,
np.where((target_array > split_key[3]) & (target_array <= split_key[4]), 4,
np.where((target_array > split_key[4]) & (target_array <= split_key[5]), 5,
np.where((target_array > split_key[5]) & (target_array <= split_key[6]), 6,
np.where((target_array > split_key[6]) & (target_array <= split_key[7]), 7,
np.where((target_array > split_key[7]) & (target_array <= split_key[8]), 8, 9)))))))))
# 도수분포표 생성
freq_table = pd.DataFrame(pd.Series(target_array).value_counts(), columns = ["freq"])
freq_table.index.name = column
freq_table.sort_index(inplace = True)
freq_table["ratio"] = freq_table.freq / sum(freq_table.freq)
freq_table["cum_freq"] = np.cumsum(freq_table.freq)
freq_table["cum_ratio"] = np.round(np.cumsum(freq_table.ratio), 2)
freq_table["ratio"] = np.round(freq_table["ratio"], 2)
if "new_index" in locals():
freq_table.index = new_index
freq_table.index.name = column
return freq_tableRawdata = pd.read_csv("Data_for_study.csv")
make_freq_table(Rawdata, "키")
- 위 도수분포표에서 사용해야 할 것은 범주화된 $X_i$인 키의 중앙값과 freg다.
- 표준편차의 식을 다음과 같이 유도해보자.
$$\sqrt{\frac{\sum(X_i - \bar{X})^2}{n}} = \sqrt{\frac{\sum fX_i^2}{n} - \left ( \frac{\sum fX_i}{n} \right )^2}$$
# 중앙값 생성
키_도수분포표 = make_freq_table(Rawdata, "키")
키_도수분포표.reset_index(drop=False, inplace=True)
# 1 부터 8번 행까지 처리
키1_8_array = 키_도수분포표[1:9].키.str.split(" ~ ", expand=True).values.astype("float")
키1_8_array_mid = (키1_8_array[:,0] + 키1_8_array[:,1])/2
# 0, 9 행 처리
키0_9_array = 키_도수분포표.loc[[0,9]].키.str.partition(" ")[0].to_numpy().astype("float")
# 중앙값 생성
키1_8_array_mid = np.insert(키1_8_array_mid, 0, 키0_9_array[0])
키_도수분포표["중앙값"] = np.insert(키1_8_array_mid, len(키1_8_array_mid), 키0_9_array[1])키_도수분포표
키_도수분포표["$fX$"] = 키_도수분포표["freq"] * 키_도수분포표["중앙값"]
키_도수분포표["$fX^2$"] = 키_도수분포표["freq"] * 키_도수분포표["중앙값"]**2
키_도수분포표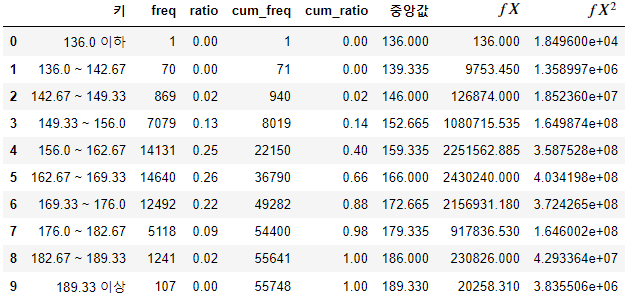
# 도수분포표로 추론한 표준편차
>>> 앞부분 = 키_도수분포표["$fX^2$"].sum()/키_도수분포표["freq"].sum()
>>> 뒷부분 = (키_도수분포표["$fX$"].sum()/키_도수분포표["freq"].sum())**2
>>> np.sqrt(앞부분 - 뒷부분)
8.771635569514544# 실제 표준편차
>>> np.std(Rawdata.키)
8.589382382344816- 자유도가 아닌 총 빈도 수인 $n$으로 나눠 모 표준편차를 구하였다.
- 표본 표준편차를 구하고자 하는 경우, 위 공식에서도 $n$이 아니라 $n-1$로 나눠주면 된다.
- 실제 표준편차는 8.5893이 나왔으며, 도수분포표로 추론한 표준편차는 8.7716이 나왔다.
- 앞서 말했듯, 이 방법은 도수분포표만 사용 가능한 경우에 쓸 수 있는 방법이다.
'Python으로 하는 기초통계학 > 기본 개념' 카테고리의 다른 글
| 대푯값과 비대칭도, 왜도(Skewness), 첨도(Kutosis) (0) | 2021.03.11 |
|---|---|
| 산포도 - 편차: 절대 편차 & 절대 편차를 사용하지 않는 이유 & 변동 계수 (0) | 2021.03.08 |
| 산포도(Dispersion) - 범위, 사분위간 범위, 사분위수와 상자 수염 그림 (0) | 2021.03.04 |
| 중심경향치(2) - 산술 평균, 기하 평균, 조화 평균, 모평균과 표본 평균이 같은 이유 (0) | 2021.03.03 |
| 중심경향치(1) - 최빈값, 중앙값 (0) | 2021.03.03 |