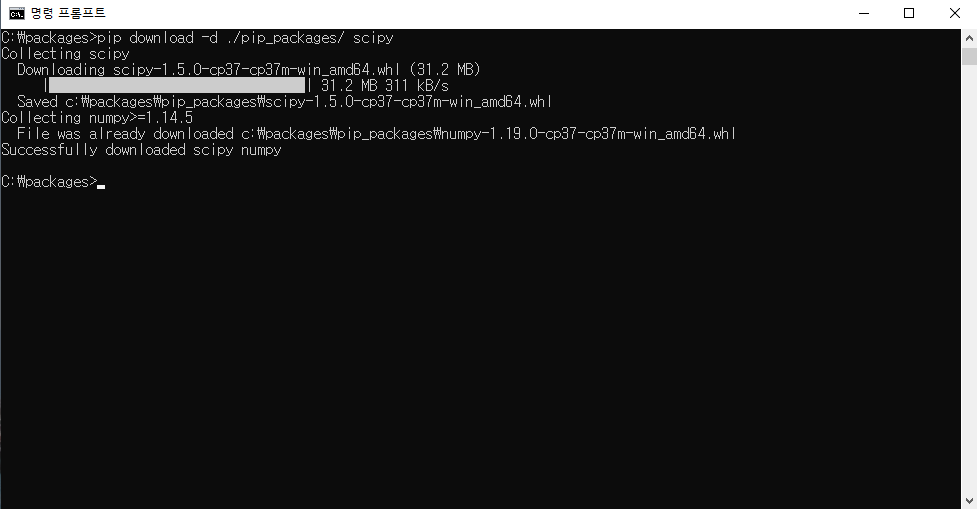
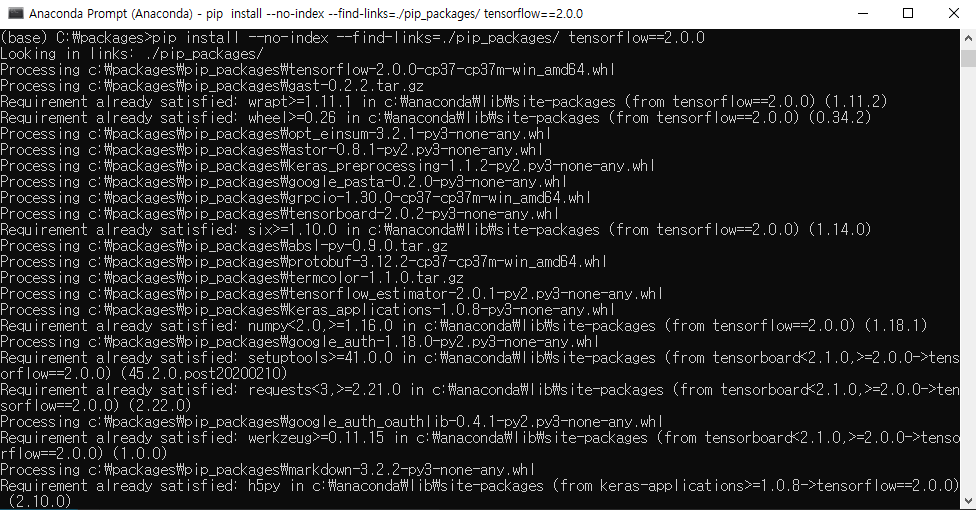
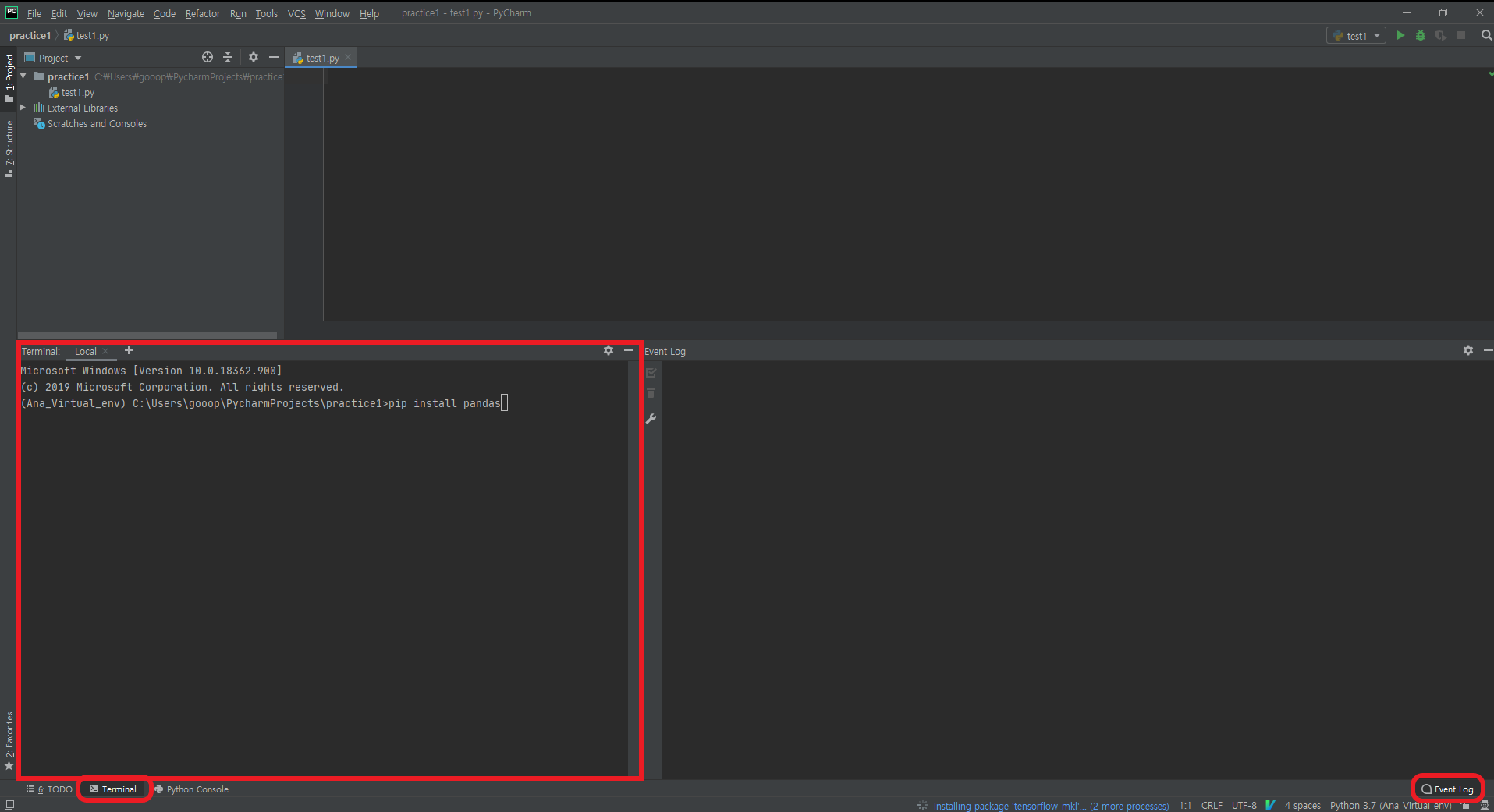
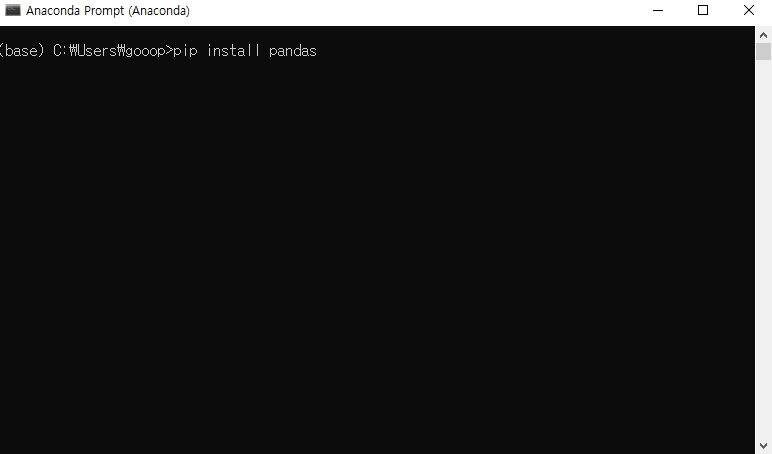
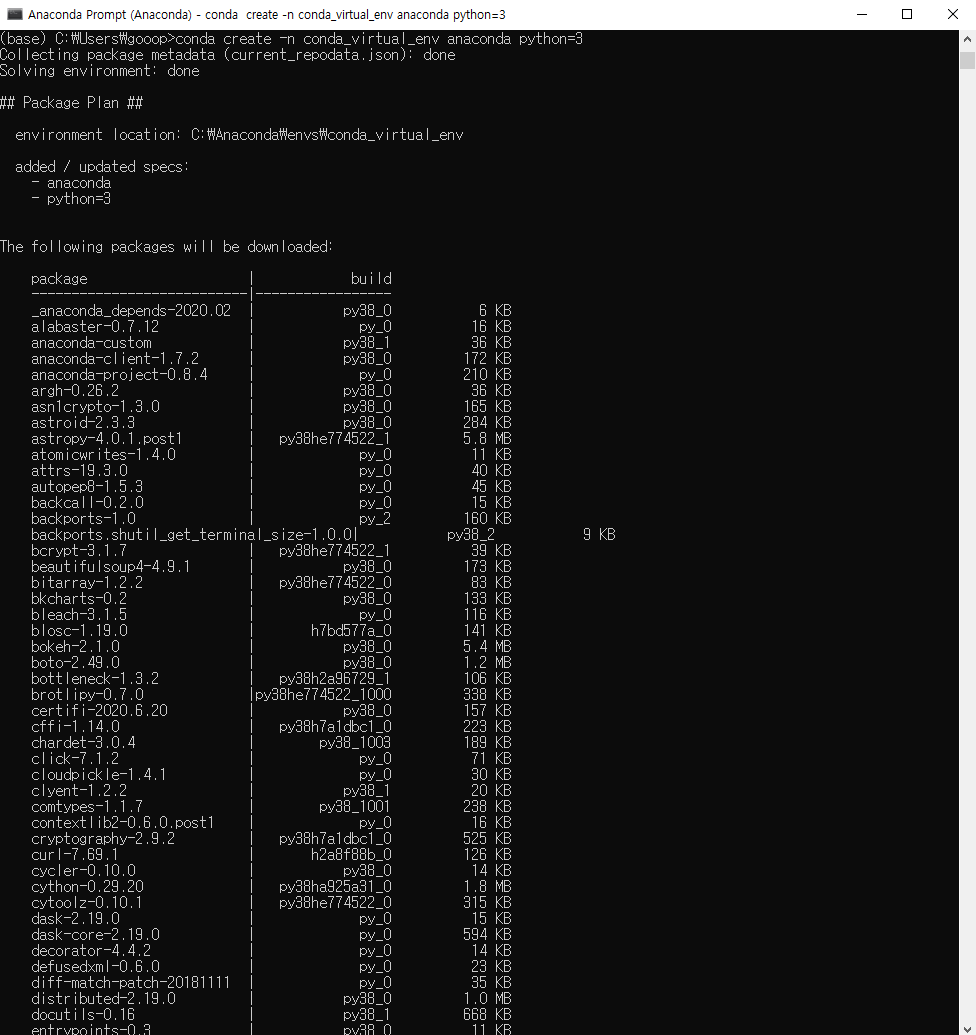
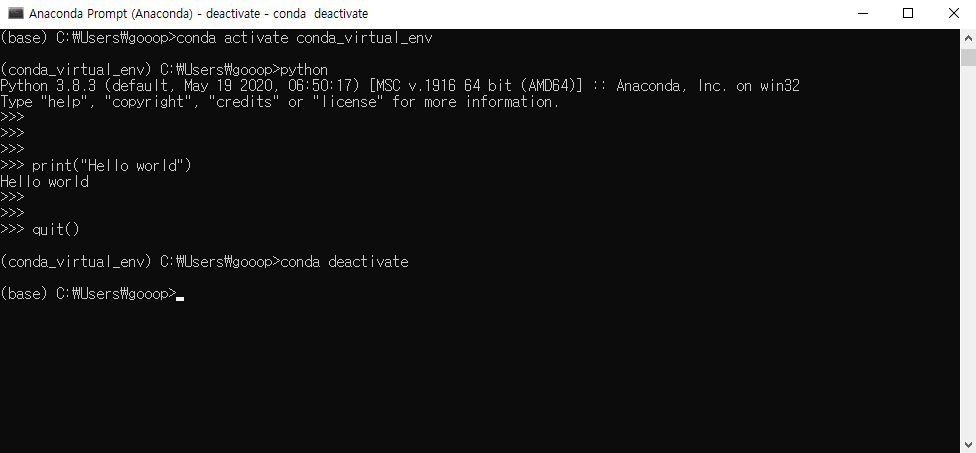
데이터 분석을 위해선 먼저 분석을 할 수 있는 환경을 만들어야 하고, 그다음엔 분석을 할 데이터를 가지고 와야 한다. 이번 포스트에선 R에서 데이터를 가지고 오는 방법에 대해 학습해보도록 하겠다.
데이터 가져오기(Data Import)
R은 일반적으로 csv 파일, R 전용 데이터 파일인 RData(확장자: .rda 또는 .rdata), 엑셀 파일 등으로 데이터를 입출력한다.
이외에도 DB, Json, SPSS 파일 등 다양한 형태로 데이터 입출력 관리를 한다.
이번 포스트에서는 csv, RData, SPSS, 엑셀 파일로 데이터를 관리하는 방법에 대해 학습해보도록 하겠다.
DB를 통해 데이터를 관리하는 것은 추후 RMySQL 코드를 다루면서 짚고 넘어가도록 하겠다.
디렉터리(Directory) 확인하기.
디렉터리란, 다른 말로 폴더(Folder), 카탈로그(Catalog)라고도 하는데, 디렉터리라는 이 말보다 디렉터리를 부르는 다른 용어인 폴더라는 단어가 더 이해하기 쉬울 수 있다.
디렉터리는 상위 디렉토리(부모 디렉토리)와 하위 디렉토리(자녀 디렉토리)로 구성된 트리 형태의 구조를 가지고 있다.
R에서 당신이 확인할 디렉터리는 바로 워킹 디렉토리(Working Directory)이다.
워킹 디렉토리는 R에서 작업하는 파일들이 기본적으로 읽고 쓰이는 공간이다.
디렉토리 관련 기본 코드
getwd() : 현재 워킹 디렉터리를 확인한다.
setwd("폴더 주소") : "폴더 주소"로 워킹 디렉토리를 잡아준다. ※ 만약 당신이 워킹 디렉터리의 주소를 폴더의 url 주소를 복사 붙여 넣기 한다면, 슬래쉬(/) 역 슬래쉬로(\) 잡혀서 들어가므로, 이를 바꿔주어야 한다.
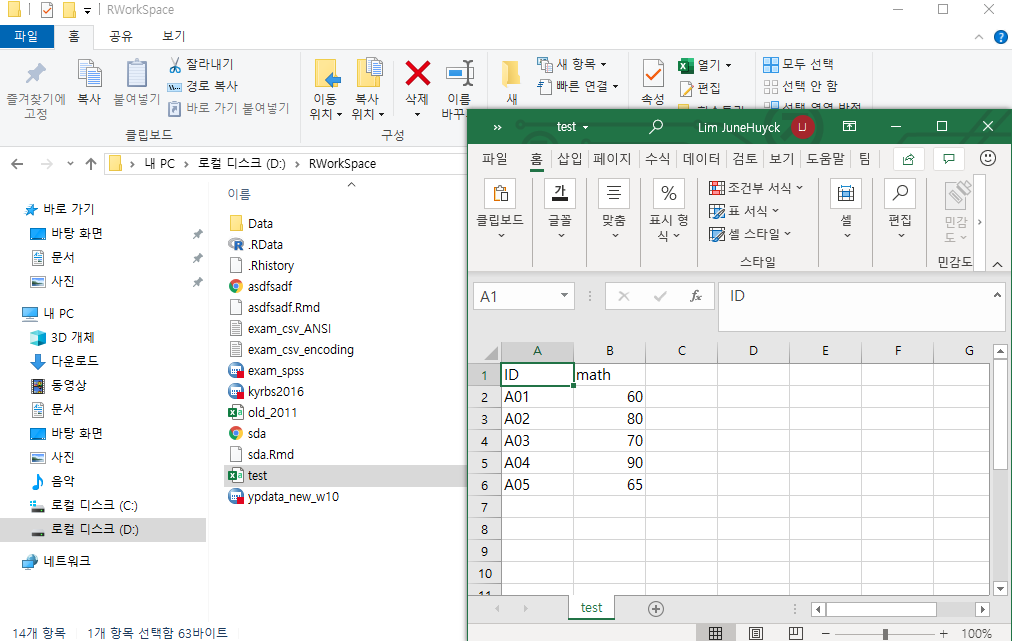
setwd("D:/Rworkspace")
getwd()
## [1] "D:/Rworkspace"
파일을 가지고 와보자.
파일 경로에 한글이 들어가 있는 경우, 오류가 발생할 수 있으므로, 경로와 대상 파일의 명칭을 반드시 영어로 바꿔주자.
list.file() : 워킹 디렉터리에 있는 파일 리스트를 가지고 온다. (만약 괄호 안에 다른 경로를 넣는다고 하면, 그 경로에 있는 파일 리스트를 가지고 온다.)
파일을 가지고 오는 방법은 다음과 같다. (csv, excel, spss, txt, rdata 파일 모두 함수 안에서 파라미터로 불러오고자 하는 파일의 경로나, file.choose()로 파일을 클릭해서 가져올 수 있다. 아래 내용이 잘 이해가 안 될 수 있는데, 일단 넘기고 따라서 학습해보자)
워킹 디렉터리 내 파일을 가지고 오는 경우: "파일명.확장자"
가져오려는 파일의 위치가 가변적인 경우, "파일위치/파일명.확장자"로 불러오기
file.choose()를 사용하여 파일을 선택하여 불러오기
R은 기본적으로 제공하는 데이터셋이 있으며, 해당 목록은 data() 함수를 통해서 볼 수 있다.
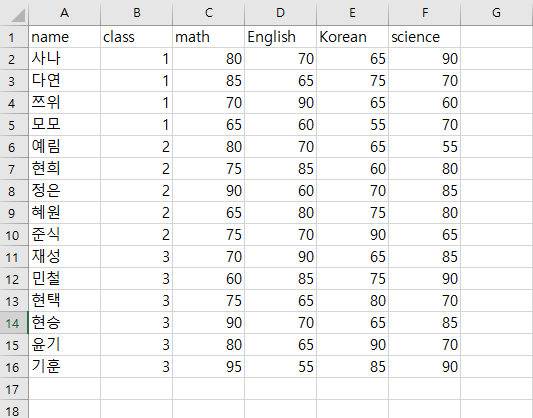
csv 파일을 가지고 와보자.
CSV(Comma-separated Values)는 말 그대로 쉼표(Comma)로 값들이 구분된 형태이다.
csv 파일은 엑셀, SAS, SPSS, R, Python 등 데이터를 다루는 대부분의 프로그램에서 읽고 쓰기가 가능한 범용 데이터 파일이다.
csv 형식은 다양한 프로그램에서 지원하고 엑셀 파일에 비해 용량이 매우 적기 때문에 데이터를 주고받는 경우 자주 사용된다.
단점으로는, csv파일은 쉼표로 구분자가 들어가 있으므로, 데이터 자체에 쉼표가 들어가 있는 경우, 데이터 취급이 곤란해진다(구분자를 탭 문자로 바꾼 TSV 등을 사용한다.)
read.csv() : csv 파일을 가지고 온다.
주요 Parameter : read.csv(file, header = FALSE, sep = ",", na.strings = "NA", stringsAsFactors = TRUE, fileEncoding = "", encoding = "unknown") # 파일 이름 / 첫 행을 헤더로 처리하여, 컬럼의 이름으로 할지 여부 / 구분자 / 데이터에 결측 값이 있는 경우 대응시킬 값 지정 / 문자열을 펙터로 가지고 올지 여부 / 가지고 오는 파일의 인코딩 / 문자열을 표시할 때의 인코딩
stringsAsFactors는 가능한 FALSE로 하여 가지고 오자(Default = TRUE)이다. 만약, 디폴트 값 그대로 가지고 온다면, 모든 문자형이 Factor로 들어오기 때문에, 텍스트 데이터를 조작하기가 꽤 어려워진다. 만약, 텍스트 데이터가 단순한 범주형 척도로써 존재한다면, TRUE로 가지고 와도 큰 문제가 없다.
write.csv() : csv 파일로 저장한다.
주요 Parameter : write.csv(data, file="", row.names=TRUE, encoding = "unknown") # 파일로 저장할 데이터 / 데이터를 저장할 파일명(경로) / 행 이름을 csv 파일에 포함하여 저장할지 여부 / 파일을 어떤 인코딩으로 저장할지
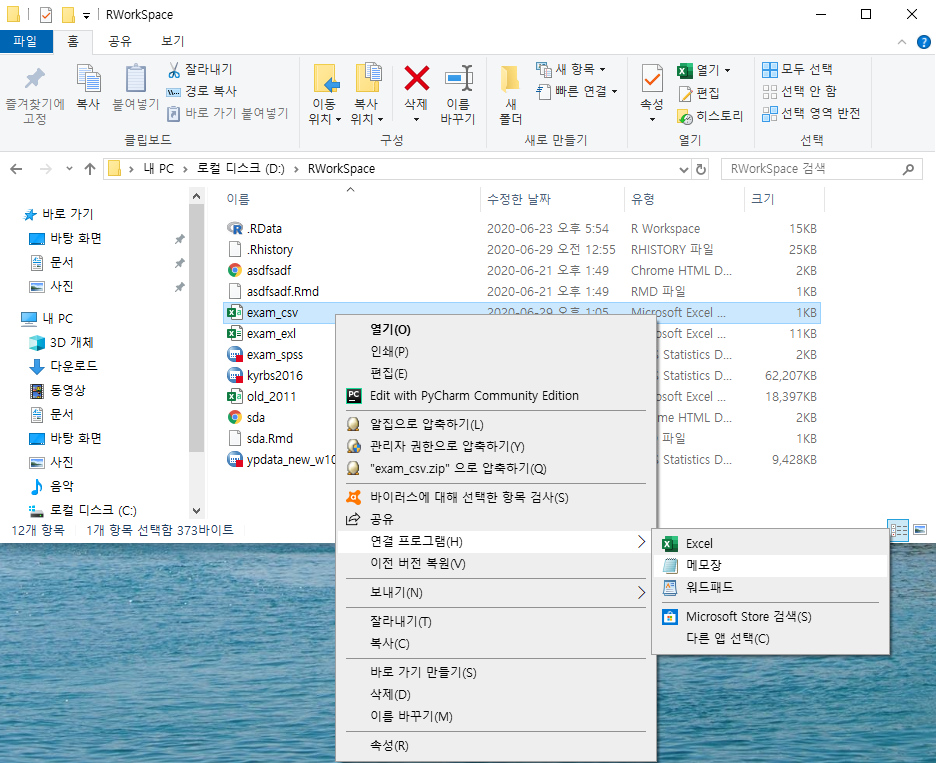
먼저 list.files()를 실시하여, 워킹 디렉터리에 위치한 파일의 정확한 이름을 확인하자.
##Error in type.convert.default(data[[i]], as.is = as.is[i], dec = dec, : '<82><82><98>'에서 유효하지 않은 멀티바이트 문자열이 있습니다
자 아주 간단한 파일이지만, 갑자기 "Error in type.convet.default(data[[i]], as.is = as.is[i], dec = dec, : '<ec><82><ac><eb><82><98>' 에서 유효하지 않은 멀티바이트 문자열이 있습니다."라며 오류가 뜬다!
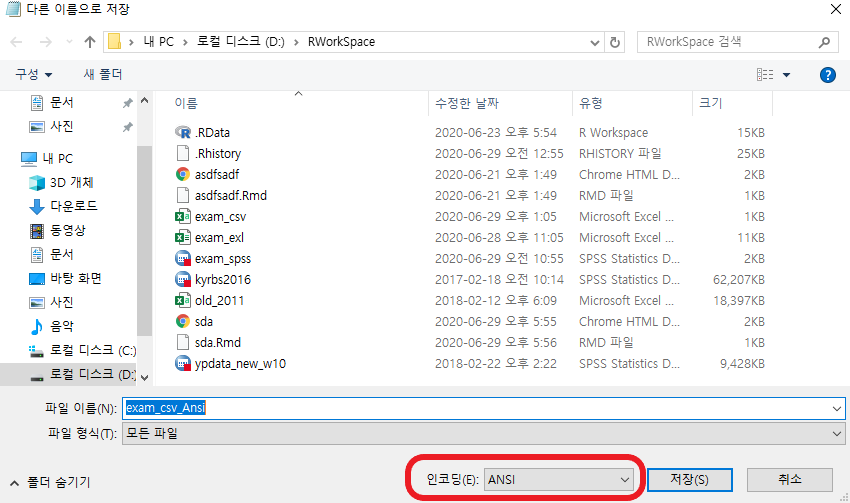
위 오류가 발생한 이유는, office 365 엑셀의 인코딩 문제인데, 일반적으로는 fileEncoding과 encoding 파라미터를 손봐주면 된다.
개인적으로는 위의 방법을 추천하지만, 경우에 따라서 좀 더 고급진 방법을 써야 할 수도 있을 것이다.
위 인코딩 문제는 간단하게 말해서 Windows에서 한글이 제대로 인식이 안되고, RStudio에서도 한글이 인식이 제대로 안돼서 발생하는 문제라고 할 수 있는데, R의 System 설정을 손대는 함수 중 언어를 손대는 함수인 Sys.locale()을 이용해서 이를 해결할 수 있다.
Sys.setlocale() : 로케일을 설정하는 함수로, 로케일은 사용자의 언어, 사용자 인터페이스의 언어를 정해주는 함수이다.
주요 Parameter : Sys,setlocale(category = "LC_ALL", locale = "")
Sys.setlocale("LC_ALL", "C") # 언어를 제거해버리자
data = read.csv("exam_csv.csv", header = TRUE, stringsAsFactors = TRUE, encoding = "UTF-8")
data
지난 포스트에서 기계학습(Machine Learning)에 대해 간략하게 알아보았다. 이번 포스트에선 기계학습을 수월하게 할 수 있게 해주는 텐서플로우(Tensorflow)에 대해 알아보도록 하자.
텐서플로우(Tensorflow)란?
텐서플로우는 구글에서 2015년에 공개한 기계학습 라이브러리로, 일반인들도 기계학습을 사용할 수 있을정도로 난이도가 낮고, 아주 강력한 성능을 가지고 있다.
단, 텐서플로우는 딥러닝 알고리즘인 인공신경망이 한 번 학습되기 시작하면 신경망의 구조가 고정되어버리기 때문에 특정 프로젝트에 최적화하여 사용하는데 한계가 있다.
최적화까지 감안하여 기계학습을 하기 위해선, 신경망의 구조까지 스스로 학습하며 변하는 페이스북 인공지능팀에서 개발한 파이토치(PyTorch)를 사용해야한다(텐서플로우와 파이토치의 성능차이는 상당히 큰 편이다).
텐서플로우는 참고 자료가 더 많고, 사용자가 파이토치보다 텐서플로우가 많은 편이므로, 텐서플로우를 먼저 학습하고, 그 후에 파이토치를 학습할 예정이다.
GPU, CPU 2가지 버전이 존재하며, GPU는 tensorflow-gpu라는 패키지를 따로 다운로드 받아야한다.
GPU는 NVIDIA의 CUDA를 사용하므로, NVIDIA 그래픽 카드가 필수이다.
본 포스트에서는 텐서플로우 Version 2.0.0으로 학습할 예정이다.
텐서플로우2는 Keras를 기반으로 작동한다.
※ CPU와 GPU를 왜 구분해서 사용하는 것일까???
CPU와 GPU의 차이를 간단하게 설명하자면 다음과 같다.
CPU는 아~~~주 머리가 좋은 친구로, 전교 10등 안에 들어가는 수학 천재인 친구다. 수능에서 4점짜리 문제들도 쉽게 풀정도로 어려운 수학 문제도 큰 힘을 들이지 않고 풀 수 있는 친구지만, 당연히 숫자가 적고, 한 번에 할 수 있는 일이 많지가 않다.
GPU는 기본적인 수학 능력을 갖춘 평범한 친구들이다. 수능에서 2점짜리 문제 같이 간단한 수학 문제라면 손 쉽게 풀 수 있지만, 어려운 수학 문제를 푸는데는 한 세월이 걸린다. 숫자가 1,000명 정도로 엄청나게 많다.
자, 이를 더 간추려 말해보면 CPU는 머리가 좋지만 숫자가 적고, GPU는 머리는 평범하지만 숫자가 많은 친구들이다.
Python이나 R은 기본적으로 CPU 연산을 하며, CPU 연산을 하다보니 아무리 어려운 문제라 할지라도 크게 힘들이지 않고 풀 수 있지만, 머신러닝에서는 이야기가 달라진다. 딥러닝에서 사용되는 가장 대표적인 알고리즘인 인공신경망은 기본적으로 행렬 연산을 통해 계산되는데, 이러한 행렬 연산은 더하기, 빼기, 곱하기, 나누기와 같은 기본적인 사칙연산을 수십 만번 실시한다고 생각하면 된다.
자, 사칙연산 수십 만번을 머리가 엄청 좋은 한 명에게 시키는 것과 평범하지만 사칙연산은 충분히 해내는 천 명에게 시키는 것, 이 둘 중 무엇이 더 효율적일까?? 당연히 사칙연산을 충분히 해낼 수 있는 천 명에게 문제를 주는 것이 훨씬 빠르지 않겠는가.
이처럼 기계학습의 특징은 어려운 연산도 물론 있지만, 이 어려운 연산은 CPU에게 맡기면 되고, 쉬운 연산은 GPU에게 맡기는 방식을 사용한다. 즉, 컴퓨터의 자원을 이분화시켜 사용하는 것이 기계학습의 특징이다.
텐서플로우(cpu) 설치 방법
텐서플로우만 설치하는 것은 난이도가 상당히 낮은 편이다.
텐서플로우는 버전 2.0.0을 설치할 것이다.
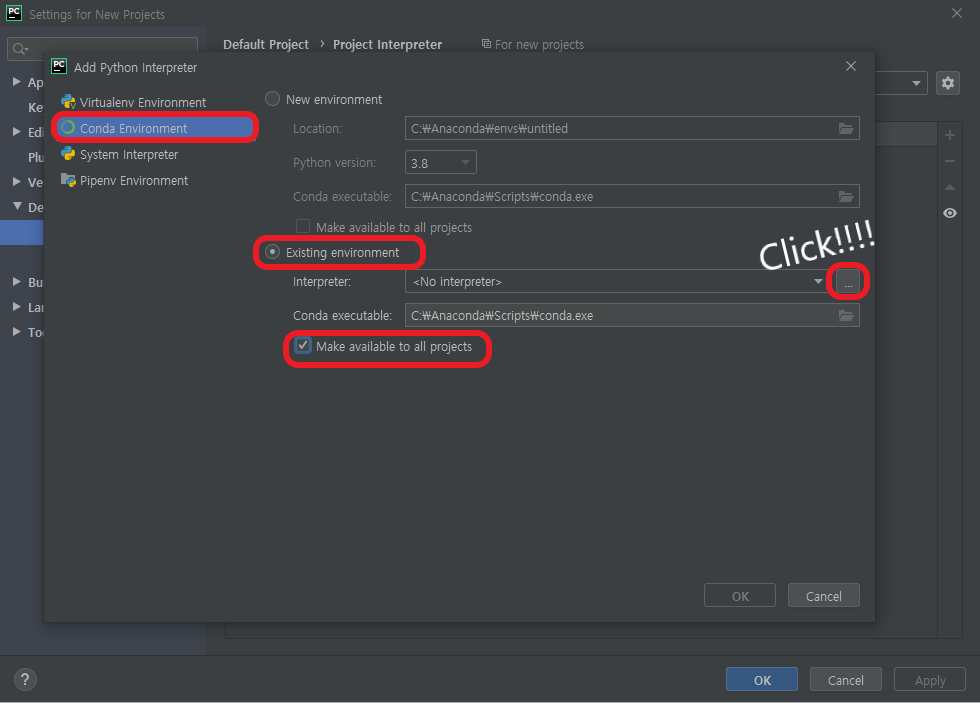
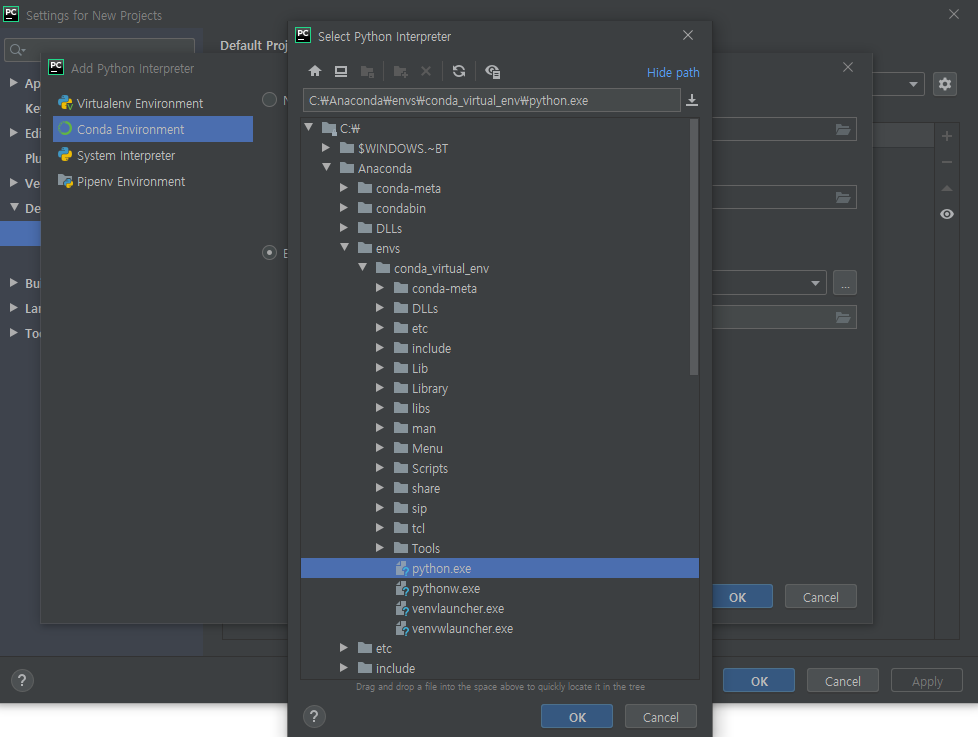
PyCharm의 UI를 이용해서 설치하기 File > Settings > +버튼 > tensorflow 검색 및 선택 > Specify version 체크 > 드롭박스에서 버전 2.0.0으로 선택 > Install Package 클릭
터미널에서 설치하기(아나콘다 가상환경을 만든 경우 *추천) cmd 실행 > conda env list(가상환경 목록 확인) > conda activate 가상환경이름 > pip install tensorflow==2.0.0
텐서플로우-gpu 설치 방법
tensorflow-gpu 설치를 위해서는 몇 가지 사전 작업이 필요하다.
NVIDIA 그래픽 카드
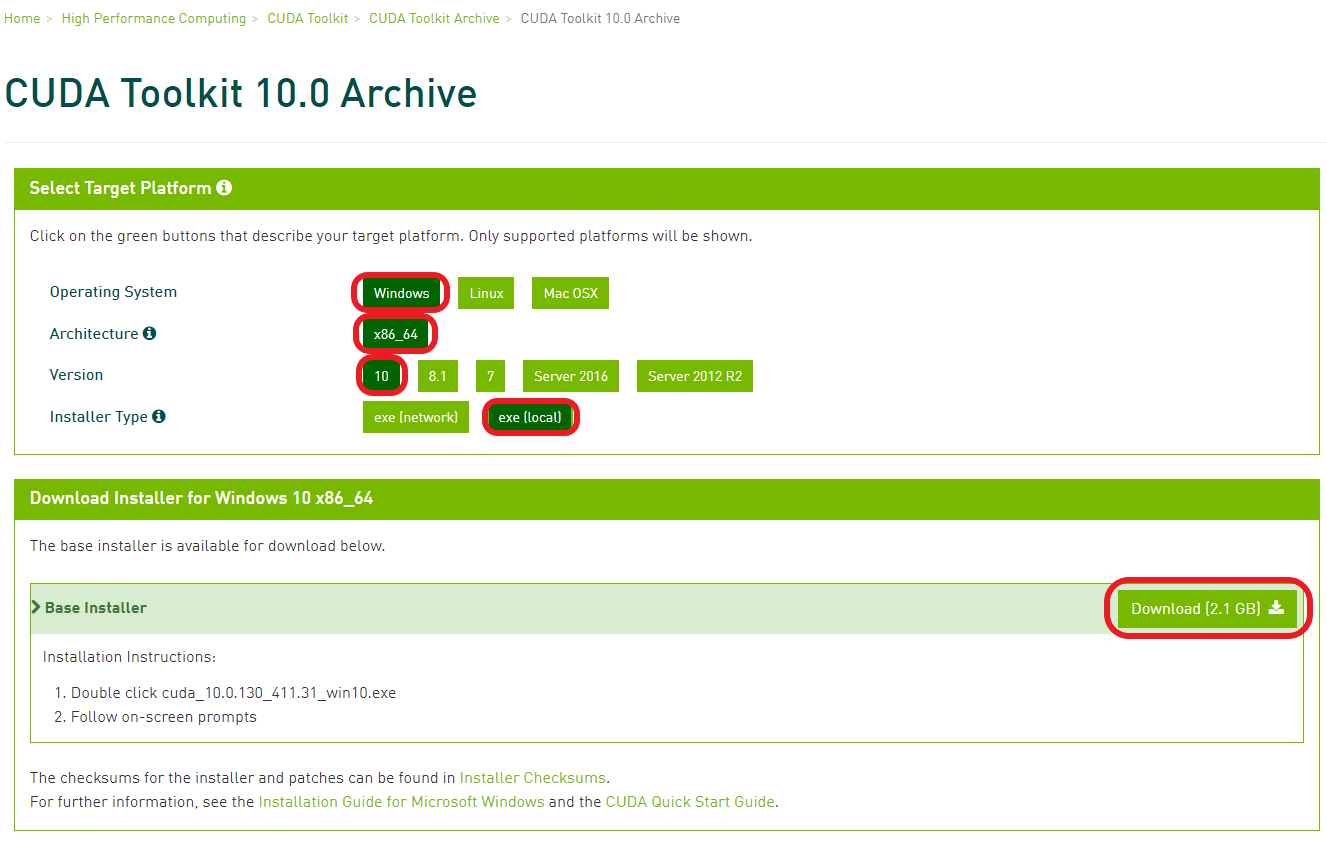
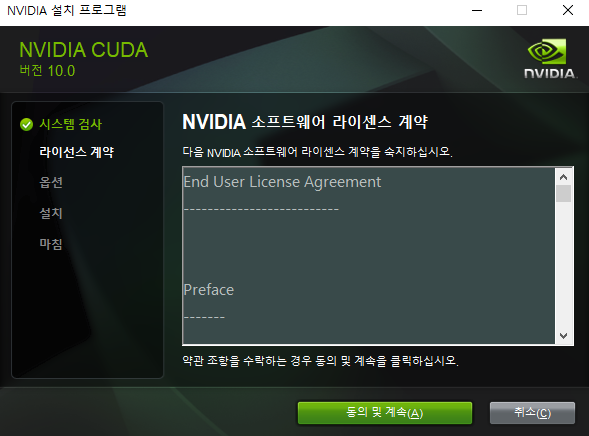
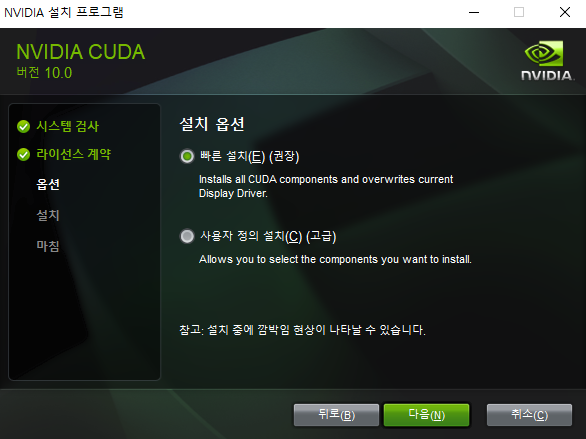
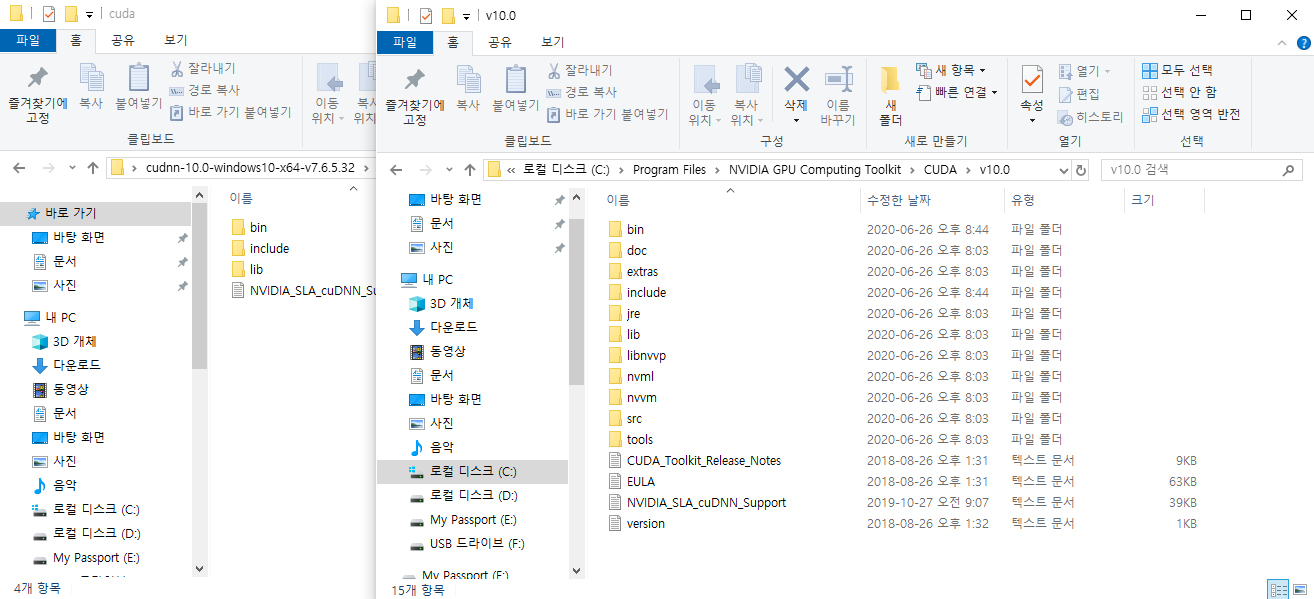
CUDA Toolkit 10.0 Version 설치
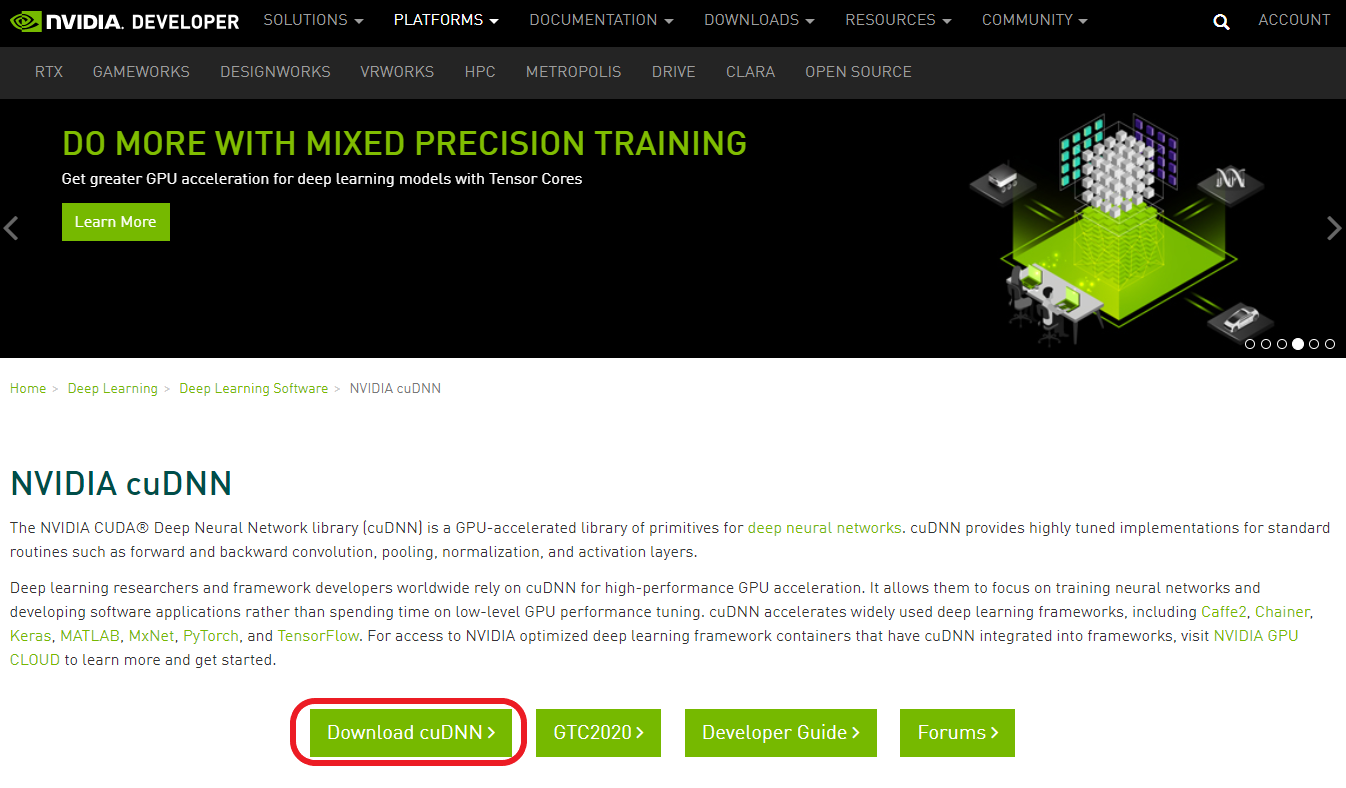
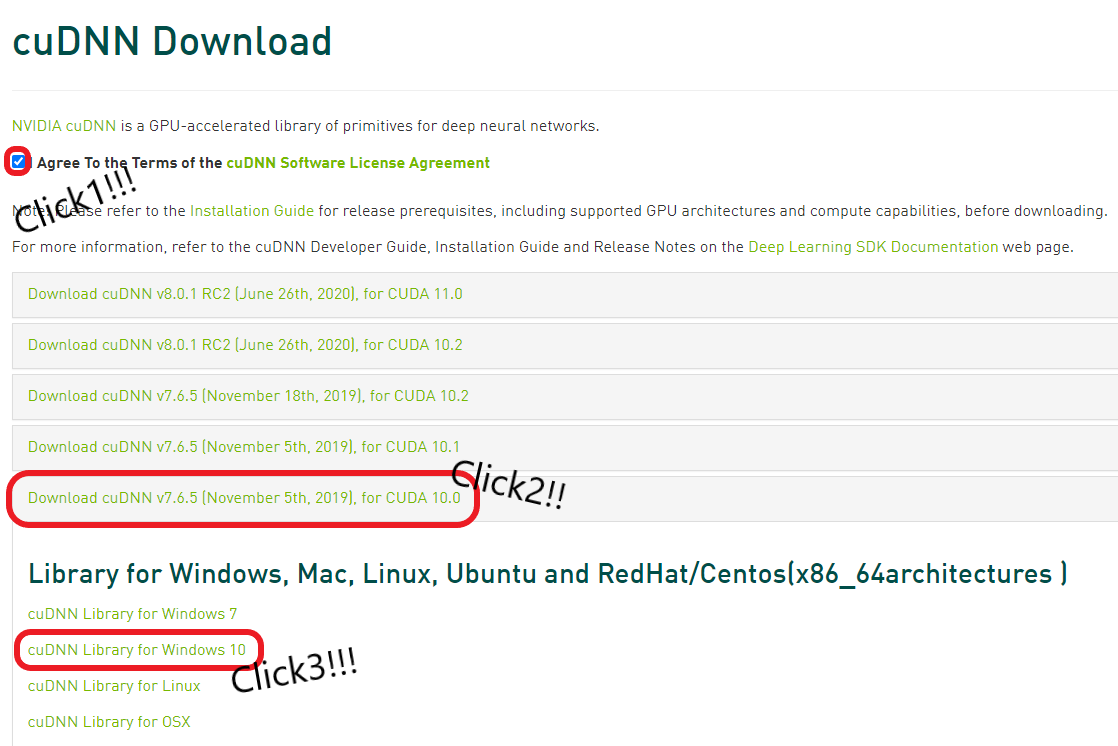
cuDNN 설치
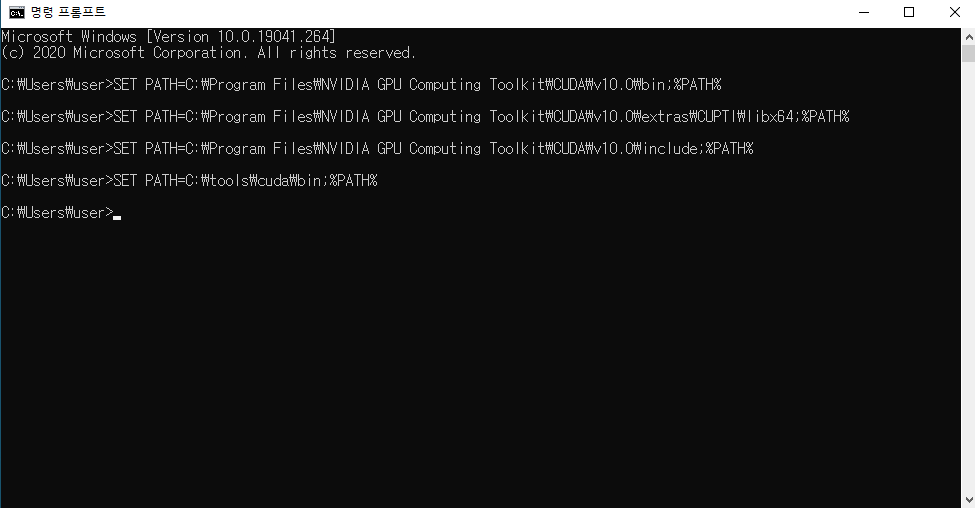
PATH 설정
tensorflow-gpu는 gpu를 이용해서 연산하므로, 컴퓨터 환경에 gpu 셋팅을 해줘야한다.
NVIDIA 그래픽 카드가 설치되어있다는 전재하에 설치 해보도록 하겠다.
CUDA Toolkit의 버전은 11까지 나왔지만, 아직 호환성에 문제가 있는지 제대로 설치가 되지 않는다. 또한, 우리는 텐서플로우 버전 2.0으로 작업할 예정이므로, 이에 맞는 CUDA Toolkit Version 10.0을 사용해보도록 하자.
이 영화에서 흥미로운 부분은 영화 밖 관객과 영화 안 관객이 조커에게 갖는 인식이 다르다는 것이다.
훗날 조커가 될 아서 플렉은 정신 질환과 장애, 불안정한 일자리, 건강이 좋지 않은 홀어머니를 모시고 사는 편치 않은 삶을 살고 있지만, 다른 이들을 행복하게 만드는 사람이 되기 위해 노력하는 삶을 지내고 있다.
지하철에서 만난 어린아이를 웃기기 위해 얼굴로 장난을 치거나, 웃긴 개그들을 정리해놓은 개그 노트를 만들고, 개그맨이라는 꿈을 향해 어떻게든 노력하며, 망상 속이긴 했지만 행복한 삶을 꿈꾸는 그런 사람이다.
하지만, 사회는 아서 플렉에게 그리 호의적이지 않았고, 광대 분장을 하고 입간판을 들고 광고를 하는 그는 강도질을 당하거나, 건장한 백인 남성들에게 둘러싸여 위협을 받거나, 그의 잘못이 없음에도 불구하고 일방적으로 그를 해고해버리는 등, 아서 플렉을 둘러싼 사회는 그를 하루하루 꿈으로부터 밀어내고 있다.
영화가 절정에 도달아 아서 플렉이 결국 조커로 각성하여, 추가 살인을 저지르고 폭동의 심볼이 되었을 때, 관객들은 사회의 부조리에 희생당하고 결국 사회에 폭발적인 분노를 표출한 조커에게 감정 이입하여 조커로부터 카타르시스를 느끼게 되며, 영화 안의 관객들은 조커라는 괴물에게 공포를 느끼게 된다.
자, 이번엔 빅데이터 분석가의 관점에서 위 내용을 바라보도록 하자, 만약 살인범인 아서 플렉에 대해 영화 내부의 인물이, 그가 어째서 살인범이 되게 되었는지에 대해 분석해본다면 어떤 결과가 나올까?
영화 안에 있는 인물들이 아서 플렉에 대해 얻을 수 있는 정보는 다음과 같다. "흡연자, 편모가정, 빈곤층, 정신 장애 보유, 신체 기형 보유, 일용직 노동자" 이러한 특징을 가진 사람들과 그렇지 않은 사람들을 비교해보니, "이런 특징을 가진 사람들이 그렇지 않은 사람보다 범죄를 저지를 확률이 높다! 그러니 이런 특성을 가지고 있는 사람들을 감시해야 한다!"라는 결론을 내릴 수 있다.
영화 밖 관객인 당신은 위 결론에 대해 동의할 수 있는가? "아서 플렉을 괴물로 만든 것은, 그에게 친절하게 굴지 않은, 그를 둘러싼 사회지 않느냐!!"라는 생각을 하며, 반발을 할 수도 있을 것이다.
우리가 접하는 대부분의 데이터는 어떠한 사건의 본질, 그 현상 자체에 대한 것이 아닌, 연구자의 의도, 관점, 생각, 가설이라는 주관이 섞여있는 상태에서 생성이 된다. 그러다 보니, 우리는 실제 현상으로부터 상당히 거리가 떨어져 있을지도 모르는 데이터를, 실체라고 오판할 수 있으며, 본질에 다가가고자 하는 시도인 분석이, 도리어 본질로부터 멀어지는 행동이 될 수도 있다.
어떻게 하면 위 문제를 해결할 수 있을 것인가?
사람의 인식은, 어떠한 대상에 대하여, 자신의 지식, 경험 등을 기반으로, 대상을 분류하는 과정을 통해 이루어지며, 우리는 인식 능력이 좋은 사람을 "통찰력 있는 사람", "시야가 넓은 사람"이라고 종종 이야기한다.
하지만, 사람이 가질 수 있는 지식, 경험은 매우 한정적이고, 그 양 역시 많지 않으며, 그 대상에 대해 받아들이는 정보 역시 온전하다고 할 수 없다. 장님에게 코끼리를 설명하라고 하면, 다리를 만진 장님은 코끼리에 대해서 "코끼리는 기둥이다!"라고 할 것이고, 코끼리의 꼬리를 만진 장님은 "코끼리는 밧줄이다!"라고 할 것이며, 코끼리의 코를 만진 장님은 "코끼리는 두꺼운 뱀이다!"라고 할 것인데, 눈이 보이는 우리 역시도 한눈에 보이지 않는 어떠한 대상에 대해, 심지어 눈에 보인다고 할지라도, 우리가 정의 내리고자 하는 어떠한 현상의 경계, 본질을 인식할 수 없다.
예를 들어, 당신이 청년 실업의 본질을 알고 싶다면, 과연 그 청년 실업이라는 현상의 경계는 어디서부터 어디까지이겠는가? 그리고 당신이 비교적 정확한 경계를 찾아낸다고 할지라도, 그 경계가 불변하겠는가?
자, 사람의 인식이 가진 한계가 위와 같다고 하면, 기계 즉, 컴퓨터에게 실제 현상에 관련된 것인지 아닌지는 모르겠지만 발생한 모든 데이터를 주고 그 데이터들을 분류해보라고 하면 어떨까?
사람 한 명이 처리할 수 있는 데이터의 한계가 있고, 여럿이서 데이터를 공동으로 처리하는 경우, 의사소통의 문제 등으로 인해, 현상을 이해하는데 문제가 생길 수 있다면, 어마어마하게 좋은 컴퓨터에게 어마어마한 양의 데이터(빅 데이터)를 주고, 그 어마어마한 양의 데이터를 어떤 규칙에 따라 학습시키고, 데이터들을 분류해 나가다 보면, 조커와 같은 살인자 집단이 갖는 공통된 패턴을 찾아낼 수 있고, 보다 본질에 대한 명확한 이해를 할 수 있지 않을까?
위 내용들을 단순화시켜 말하자면, 무엇인지 모르는 본질이 숨어있을 엄청나게 거대한 빅 데이터를, 컴퓨터에게 주고, 빅 데이터를 학습시켜서 컴퓨터가 그 안 속에 숨어있는 어떠한 패턴을 찾아내게 하는 것. 이 일련의 활동이 기계 학습(Machine Learning)이며, 우리는 데이터 자체에서 패턴을 찾아낼 수 있다.
우리는 이 기계 학습을 통해서, 우리가 지금까지 알지 못했던 빅 데이터 속에 숨겨져 있는 어떠한 패턴, 이론, 변수 등을 찾아내어, 지금까지의 이론을 기반으로 하여 시작하는 연구에서, 실제 데이터를 통해서 이론을 찾아내는 연구로 현상에 대해 접근하는 방법을 바꿔서 다가갈 수 있다.
이 것이 우리가 기계학습을 공부해야 하는 이유이며, 기계학습으로 해낼 수 있는 가능성이 바로 이것이라 말할 수 있다.
자, 지금까지 기계 학습(Machine learning)이 무엇인지에 대해 이야기해보았다. 위키피디아나 책에서 나온 정의는 잘 와 닿지가 않아, 기계학습에 대한 필자의 생각을 정리해본 내용이다. 보다 자세한 내용은 위키피디아나 책을 찾아보길 바라며, 이제 천천히 기계학습에 대해 본격적으로 접근해보도록 하자.
본 블로그에서 기계학습 부분은 파이썬을 이용해서 실습할 예정이므로, 다음 포스트에서는 파이썬 기계학습의 대명사인 텐서플로우(Tensorflow) 설치 방법에 대해 학습해보도록 하겠다.
여러분이 파이썬을 본격적으로 활용하다보면 어느 순간부터인가 모듈, 모듈화한다 등의 말을 듣게 될 것이다. 모듈은 함수(Function), 변수(Variable), 클래스(Class)를 이쁘게 잘 모아서 잘 포장해놓은 것을 말한다.
그리고, 이렇게 이쁘게 잘 정리해놓은 모듈에서 우린 언제든지 내가 원하는 기능을 뽑아서 사용할 수 있다. 자, 만약 당신이 R을 미리 학습하고 왔다면, R의 라이브러리(Library)가 떠오르지 않는가?
파이썬에서는 R의 library를 모듈(Module)이라 부르고, 우리는 언제든지 내가 필요한 모듈에서 내가 필요한 기능을 가져와서 사용할 수 있다. 앞서서 파이썬의 특징에 대해 설명할 때, 파이썬은 다양한 모듈(라이브러리라고 혼용하여 사용하였음.)들이 서로서로 의존성을 가지고 있으므로, 설치가 꽤나 어렵다고 했는데, 이번엔 그 어려운 모듈 설치를 한번 해보도록 하겠다. (환경은 이전까지 학습한 PyCharm에 아나콘다 가상환경으로 진행할 것이다.)
모듈 설치 방법은?
아나콘다, 파이참 이 2가지를 설치한 우리에겐 총 3가지의 모듈 설치방법이 있다.
1) pip로 설치하기
파이참 터미널에서 설치
파이참 좌측 하단을 보면 Terminal이라는 버튼이 있으며, 해당 버튼을 누르면 cmd창을 파이참에서 바로 사용할 수 있다.
우측의 Event Log에서는 코드 실행 후 발생한 특이사항들을 확인할 수 있다.
우측하단의 Event Log 버튼도 동일한 기능을 갖는다.
cmd 창을 바로 이용한다.
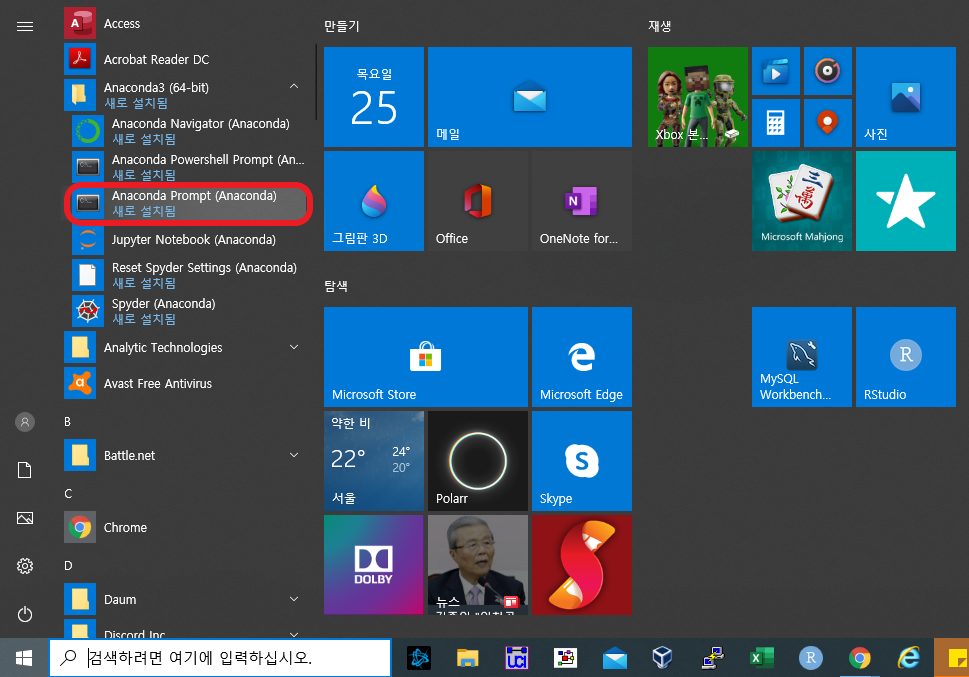
Anaconda를 설치하면서 생긴 Anaconda prompt 창을 사용해보자(그냥 cmd 창도 가능).
만약 이전 포스트의 내용까지 잘 따라왔다면, 아마 Anaconda prompt (가상환경이름)이라는 파일도 생겼을 것이다. 해당 파일을 클릭하면, 가상환경에 대한 prompt로 들어가게 된다.
pip install 모듈이름 : "모듈이름"을 pip로 설치한다.
pip uninstall 모듈이름 : "모듈이름"을 제거한다.
pip list : 현재 환경에 설치되어 있는 파이썬 모듈의 목록을 가지고 온다.
pip install --upgrade pip : pip를 최신 버전으로 업그레이드 한다(처음 pip를 쓰기 전이라면 꼭 해주도록 하자.)
pip --version : pip 버전 확인
pip란?
pip는 파이썬으로 작성된 패키지 소프트웨어를 설치, 관리하는 패키지 관리 시스탬이다. Python Package Index(PyPI)에서 많은 파이썬 패키지를 볼 수 있다(위키피디아).
그러나, pip는 앞서 다른 포스트에서 말했듯, 모듈 설치 시 충돌이 발생하면 이 부분을 무시해버리기 때문에 설치가 제대로 안될 위험이 있다.
그러므로, 가능한 conda를 써보도록 하자.
2) Conda 써보기
앞서 우리는 아나콘다를 깔았고, 가상환경을 깔았으므로, 아나콘다 prompt를 이용해서 설치해보도록 하겠다.
아나콘다 가상환경 프롬프트인 Anaconda prompt (가상환경이름)으로 들어가보자.
그냥 Anaconda의 명령 prompt는 (Base)... 로 시작하지만, 가상환경에서는 (가상환경이름).. 으로 시작한다는 차이가 있다.
파이썬은 모듈을 설치 및 관리할 때, 충돌이 일어나기 쉬우며, 충돌이 발생한 경우, 그때 그때마다 파이썬과 관련된 모든 파일을 삭제하여야할 수도 있지만, 가상환경을 사용하면, 해당 가상환경만 제거하면 된다.
conda install 패키지이름 : conda로 내가 원하는 패키지를 설치할 수 있다.
conda란?
아나콘다의 패키지 관리자로, 패키지 설치 시 현재 환경과 충돌 여부를 확인한다.
일반적으로 "conda install 패키지이름"으로 패키지를 설치해보고, 그 후에 "pip install 패키지이름"을 사용하는 것을 추천한다.
3) 파이참에서 설치해보자
파이참에서 터미널을 사용하지 않고, 파이참만의 방식으로도 설치가 가능하다.
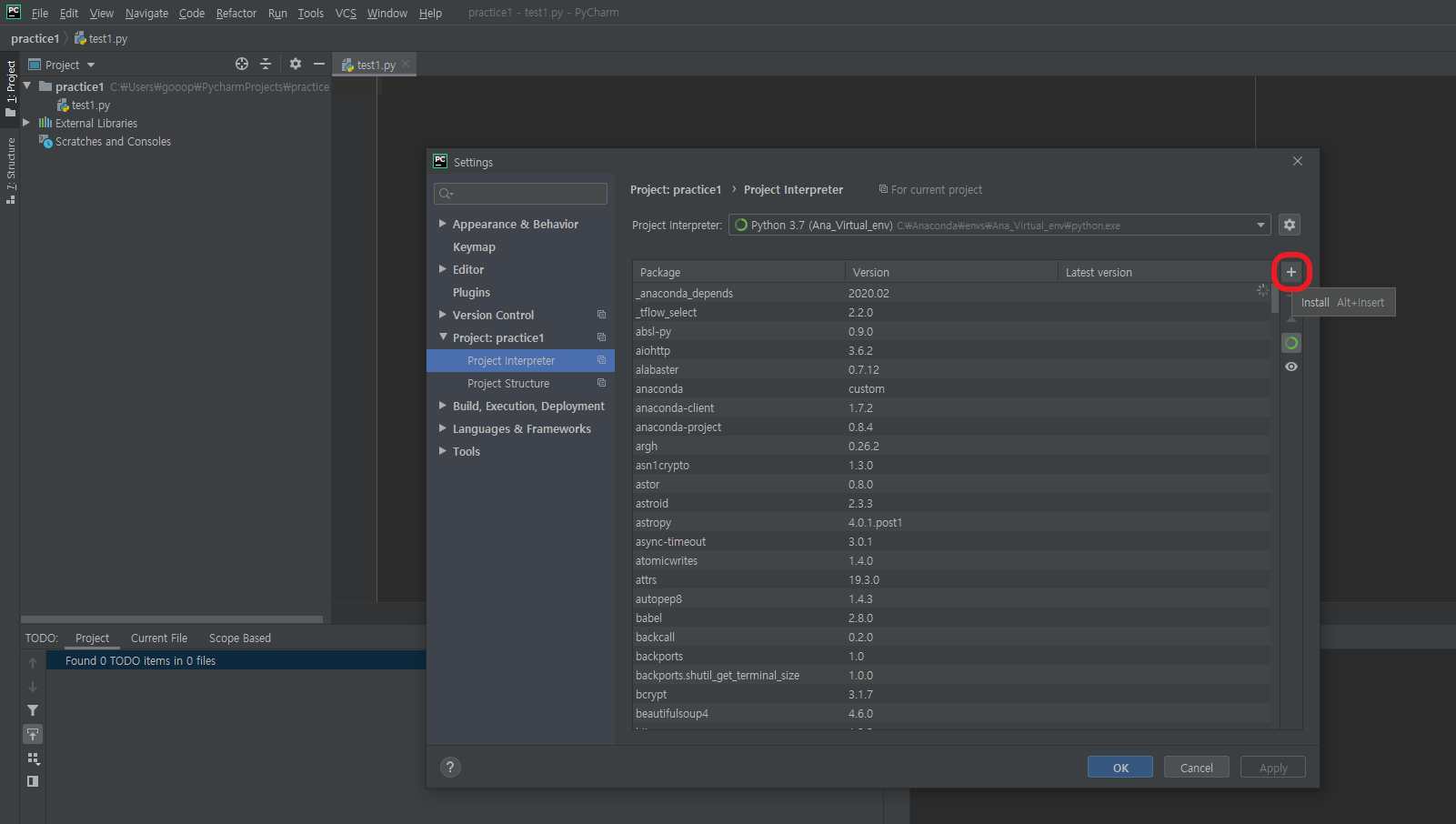
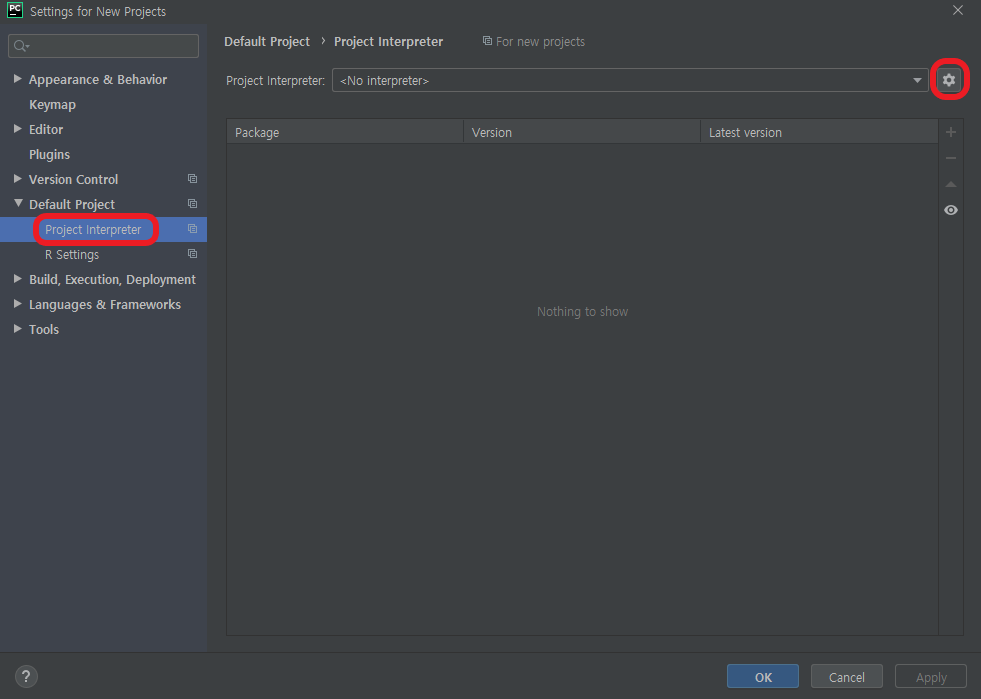
File > Settings을 클릭하고 들어가보자.
Project: 프로젝트이름 > Project Interpreter를 눌러보면 아래와 같은 화면이 뜬다.
+ 버튼을 눌러보자.
+ 버튼을 누르면 설치돼있는 모듈은 파란색으로, 설치가 아직 안된 모듈은 하얀색으로 표시가 된다.
또한 Description을 보면 간략한 상세 정보를 볼 수 있다.
우측 하단 Specify version을 체크하면, 내가 원하는 버전으로 설치할 수 있다.
설치하고자 하는 패키지를 클릭하고 좌측 하단의 Install package를 클릭하면, 해당 패키지가 설치된다.
설치 진행 상황은 파이참의 최하단부에서 확인 가능하다.
설치 가능한 모든 패키지가 검색 가능하진 않다. 특정 패키지의 경우 파이참 UI를 이용해서 설치가 불가능하므로, 그런 경우 conda나 pip를 써서 설치하도록 하자.
만약, 파이썬 모듈을 설치하다가, 설치된 패키지들끼리 충돌을 일으키거나, 잘못된 패키지 설치 등으로 인해, 문제가 생겨서 환경을 처음부터 다시 셋팅하고자 한다면, 새로운 가상환경을 만들면 된다.
이번 포스트에서는 파이썬을 어떻게 설치하는지와 아나콘다에 내장된 주피터 노트북 실행 방법 등에 대해 알아보자.
파이썬(Python) 설치와 아나콘다(Anaconda)
지난 포스트에서 "파이썬은 의존성(Dependency) 문제 등으로 패키지 설치와 관리 등이 어렵다는 단점이 있다"라고 했었는데, 파이썬을 직접 설치하는 것이 아니라, 아나콘다(Anaconda)를 대신 설치하여 파이썬을 설치한다면, 위 문제가 상당 부분 해결된다.
아나콘다(Anaconda)란?
파이썬과 아나콘다의 가장 큰 차이는 패키지 종속성 관리 방법인데, 파이썬의 패키지 관리자인 pip는 패키지 설치 시 충돌이 발생하면 이 부분을 무시해버리지만, 아나콘다의 패키지 관리자인 conda는 패키지 설치 시 현재 환경과 충돌 여부를 확인한다. 그러다보니 pip로 패키지를 설치했을 때, 충돌을 일으키며 설치가 잘 안되는 패키지는 conda prompt를 이용하여 설치하면, 수월하게 설치되는 경우도 종종 있다.
또한 아나콘다는 상당한 양의 수학 및 과학 등에 관련된 패키지들을 기본적으로 포함하고 있기 때문에, 파이썬의 오프라인 설치 시, 한 패키지를 설치하기 위해 수십여개에 달하는 패키지들을 종속성을 확인하며, 하나하나 순서대로 깔아줘야하는 문제에서도 해방될 수 있다.
그러므로, 파이썬을 사용하고자 한다면, 파이썬을 직접 까는 것보다 아나콘다를 바로 깔아주도록 하자(파이썬이 깔린 상태에서 아나콘다를 깔면, 충돌이 발생할 수도 있다...)
아나콘다를 설치해보자.
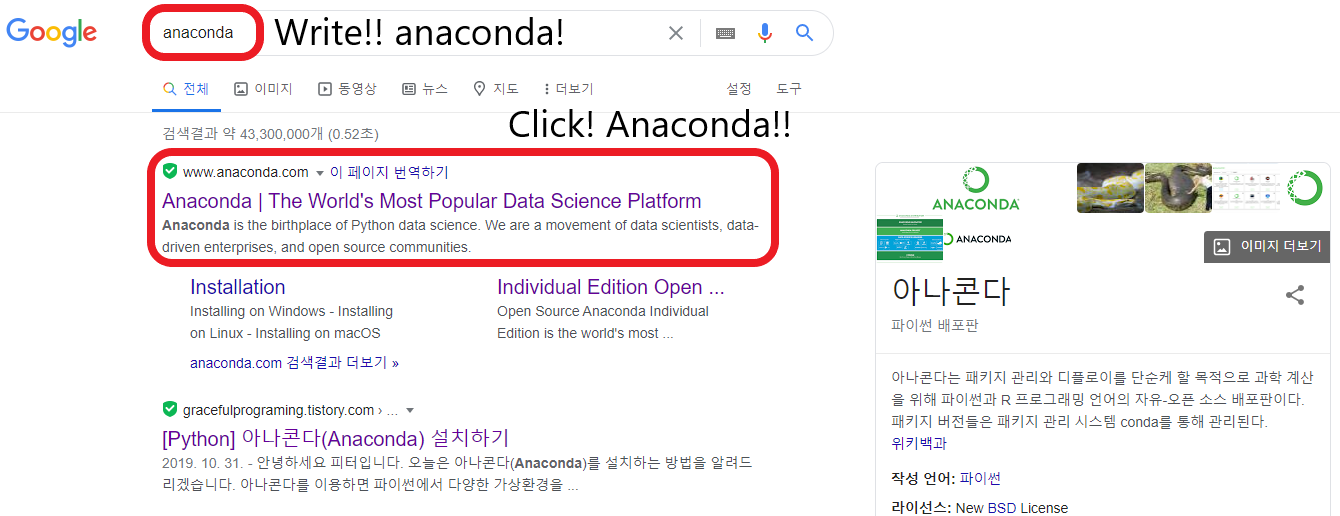
1. 아나콘다 싸이트에 들어가자!
보이는가! 파이썬과 아나콘다의 위용이! 영화로도 상영된 뱀의 한 종류인 아나콘다가 제일 위에 나오는 것이 아니라, Python 배포판 중 하나인 Anaconda가 먼저 나오는 것을 알 수 있다! (구글의 검색 알고리즘이 이용자의 활동 로그를 활용해, 이용자의 주요 관심사에 가까운 싸이트를 맨 위로 올려주는 것이 아니기를 바란다... 그리고 뱀인 아나콘다에 대한 유명 홈페이지가 없을 것 같기도하고...)
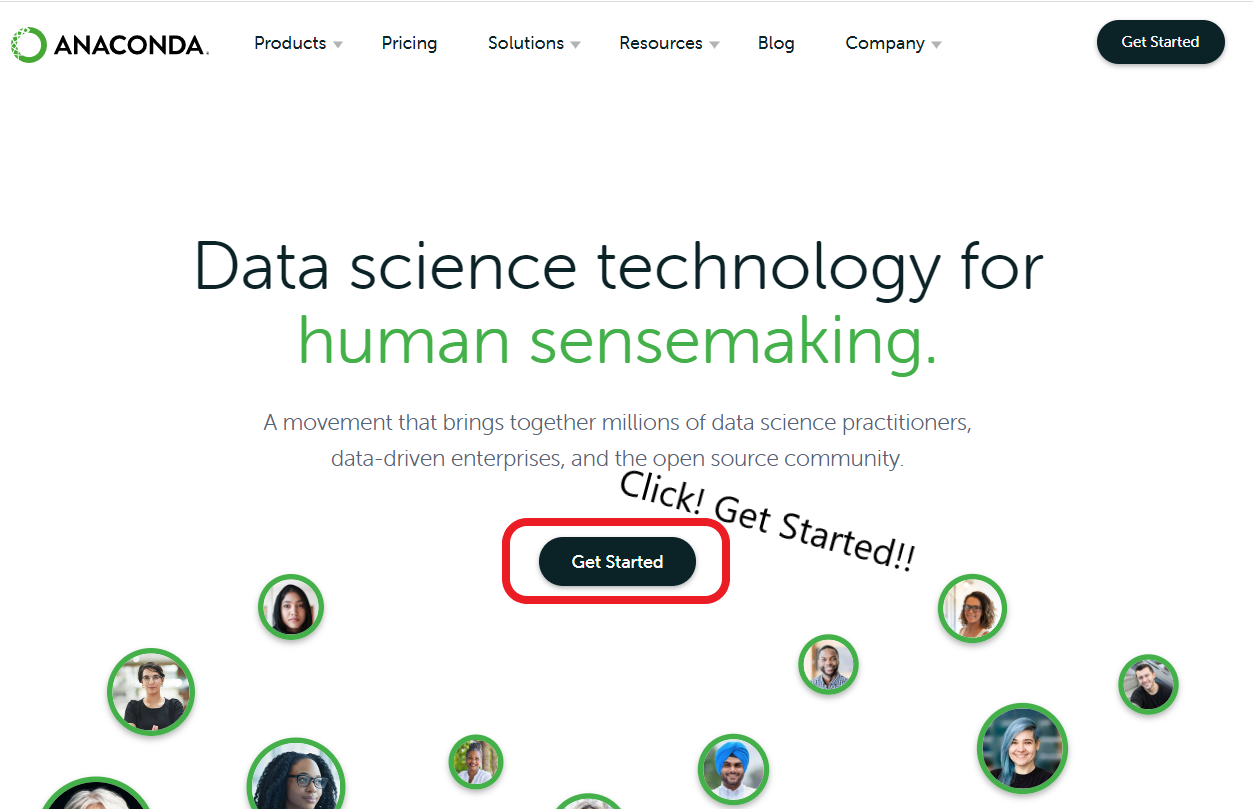
2. Get Started를 눌러보자!
우측 상단의 Get Started를 눌러도 상관 없다.
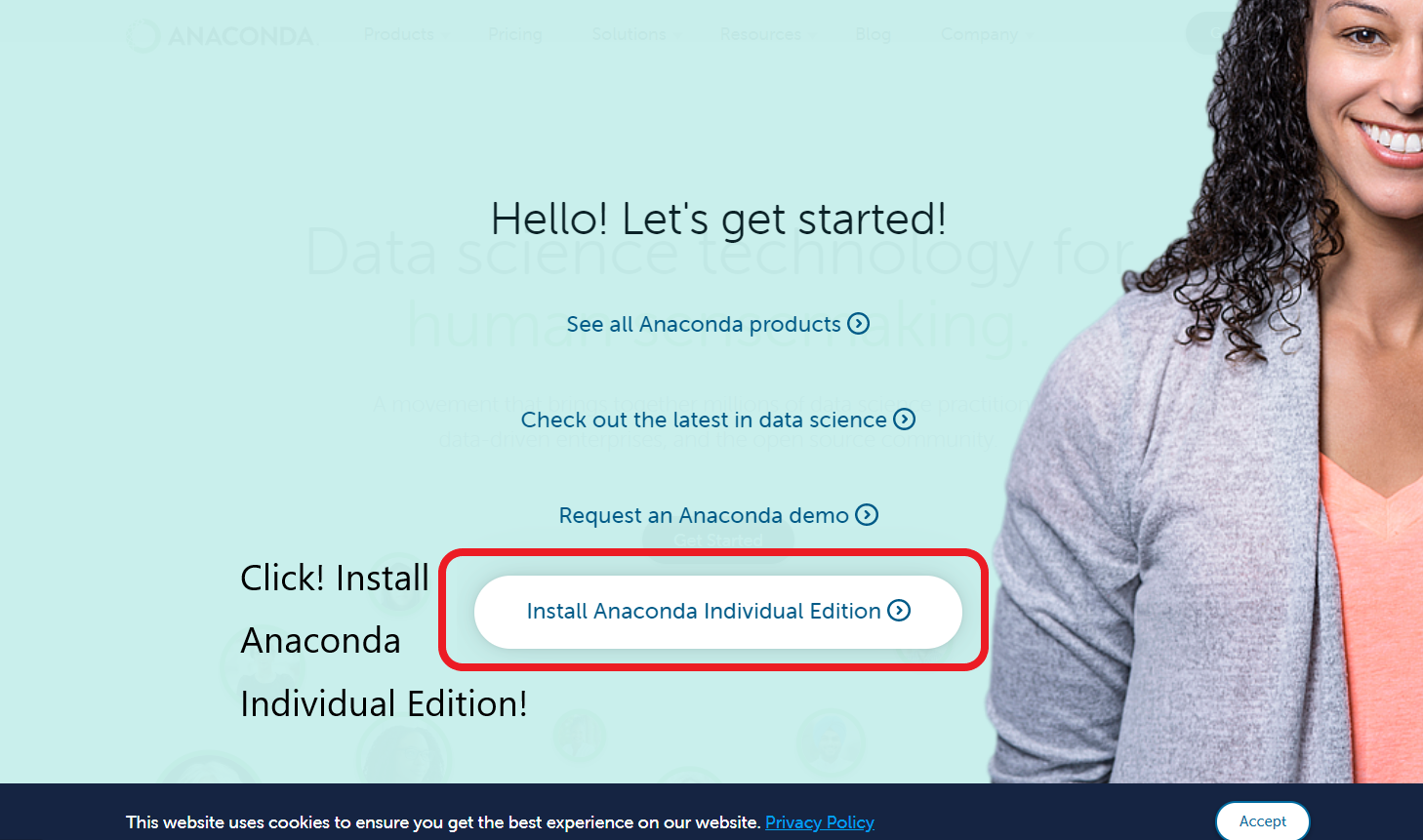
3. Install Anaconda Individual Edition을 클릭하자
4. Download을 클릭하자!
Download 아래엔 Anaconda의 특징에 대해 상세히 적혀 있다.
5. 내 OS에 맞는 버전을 설치하자.
지금 Anaconda 설치 방법을 따라오고 있는 사람은 대부분 Windows 사용자가 많을 것이다.
이번엔 Windows 환경에서 Python을 설치해보도록 하겠다.
파이썬3를 설치하도록 하겠다.
파이썬2와 파이썬3는 일부 코드가 다르며, 라이브러리에서도 상당히 차이가 난다. 그러다보니 파이썬2와 파이썬3는 호환이 되질 않는다.
파이썬3는 파이썬2에 있는 상당 수의 오류를 수정한 상태로 만들어졌다.
아직까진 파이썬2의 라이브러리가 더 많지만 파이썬3의 라이브러리 수가 점점 따라잡고 있으며, 파이썬3로 많이 넘어가고 있다.
Python 3.x가 Python3이며, Python 2.x가 Python2이다.
해당 블로그에선 파이썬3를 기반으로 학습을 하도록 하겠다.
Python 3.7 버전을 기반으로 학습을 진행하도록 하겠다.
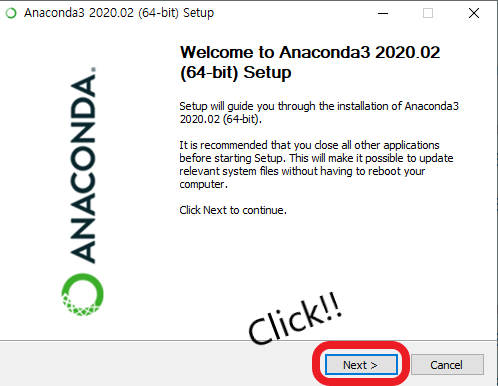
6. Ananonda 설치 시작!
Next > I Agree > Just Me (recommended) 체크!! 까지 하도록 하자!!
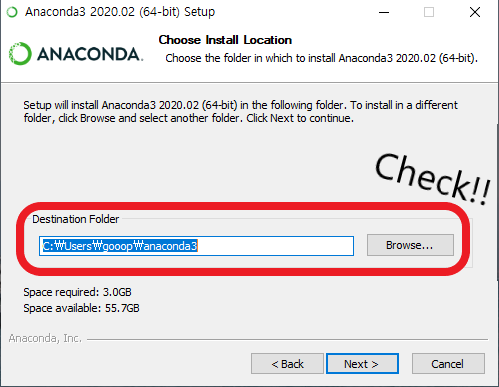
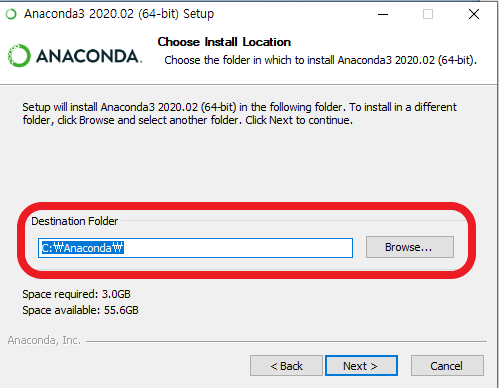
7. Anaconda 설치 경로 변경
Anaconda는 기본적으로 C:\Users\사용자계정\Anaconda3에 설치된다.
해당 위치에 설치되면 관리가 꽤나 불편하므로, C 드라이브 바로 아래에 Anaconda라는 파일을 생성하여, 그곳으로 옮겨주도록 하겠다.
Next를 눌러서 다음으로 넘어가주자!!
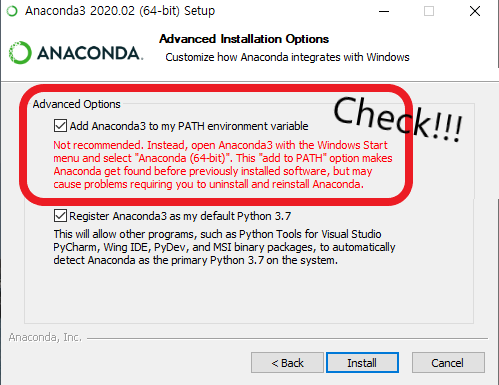
10. Add Anaconda3 to my PATH environment variable 체크!!!
PATH 환경 변수에 Anaconda를 추가할지 여부를 선택하는 것으로, 아나콘다 외에 다른 파이썬 인터프리터를 환경변수에 등록해서 사용하면 해당 체크 박스를 체크해선 안된다. 하지만 우리는 아나콘다를 주력으로 사용할 것이므로, 꼭 체크하도록 하자.
위 사항을 체크하면, 윈도우 CMD 창 경로와 상관없이 아나콘다를 파이썬으로 인식한다.
Install을 눌러서 설치를 시작하자!
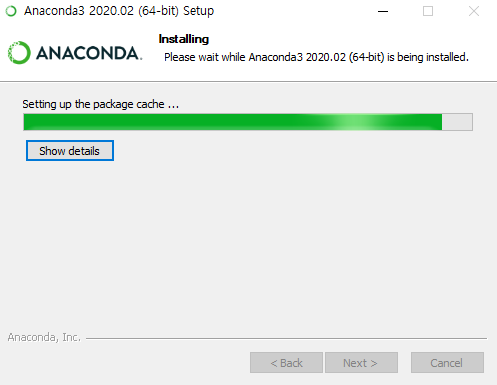
11. 설치를 기다리도록 하자.
아나콘다는 파이썬만 설치하는 경우보다 설치해야하는 라이브러리 등이 더 많기 때문에 시간이 꽤 오래걸린다.
차분히 기다려보도록 하자
12. Check Box를 해제하자!
자! 다음화면까지 나왔다면 이제 아나콘다 설치는 완료된 것이다.
Check가 돼있는데, 이는 아나콘다에 대한 설명 등이므로 체크박스를 해제하고 Finish를 누르도록 하자.
13. 자! Anaconda 설치가 완료되었는지 확인해보자!
시작메뉴에 Anaconda3가 생긴 것을 확인할 수 있다.
cmd를 열어서 파이썬이 잘 설치되었는지 확인해보자.
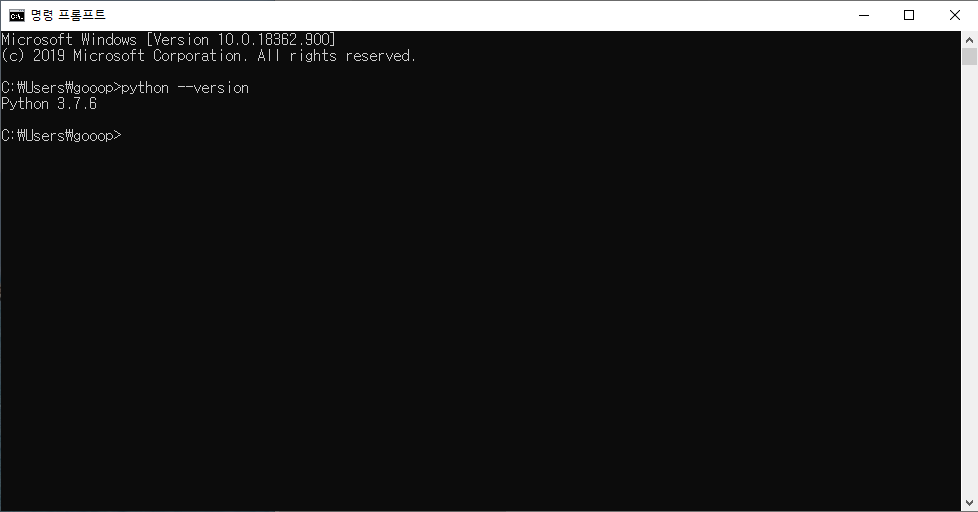
python --version 이라고 치니깐
Python 3.7.6으로 정상적으로 출력되었다.
주피터 노트북 실행하기
위 과정을 마치면 Python을 명령 prompt에서 실행할 수 있다.
하지만 이는 디버깅부터, 코드를 짜는 과정에서 발생하는 문제들을 하나하나 확인하는 모든 과정이 굉~~~장히 귀찮아지기 때문에, 효율적으로 파이썬을 쓸 수 있는 주피터 노트북을 사용해보도록 하자.
주피터 노트북은 아나콘다 설치 시 기본으로 설치된다.
가능하다면 인터넷 실행 시 기본 프로그램을 Chrome으로 바꿔주도록 하자.
시작 매뉴의 Jupyter Notebook (Anaconda)를 클릭해주도록 하자.
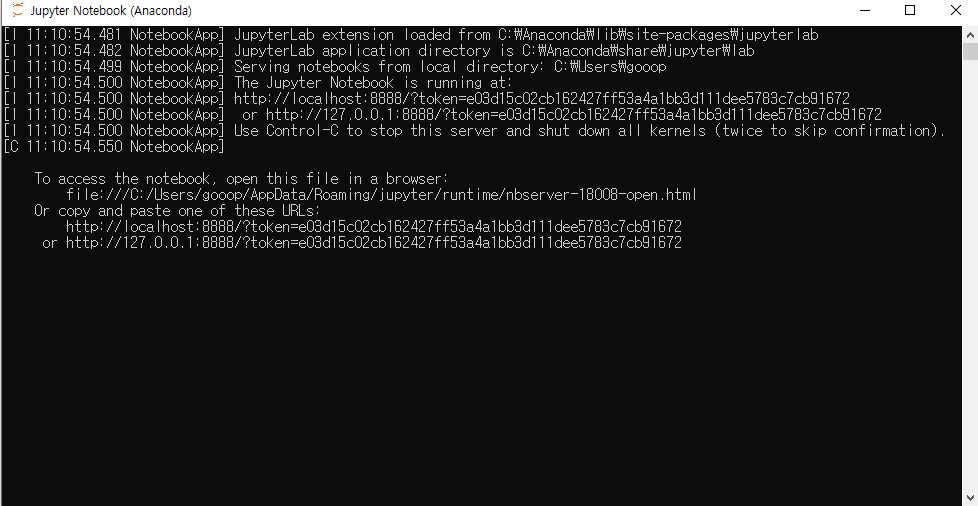
위와 같은 창이 뜨고!
위 와 같은 창이 Chrome에서 열렸다.
인터넷 기본 실행창을 Chrome으로 잡아주자 (Chrome은 메모리 점유량이 높긴하지만, 그만큼 창 자체의 속도가 빠르다. 코드 등이 길어지거나, 주피터 노트북 자체의 다양한 기능을 실행했을 시, 보다 편리하다.)
주피터 노트북의 장점과 단점
주피터 노트북은 하나의 서버에 여러명이 붙어서 동시에 작업을 할 수 있다는 장점이 있다.
서버에 파일을 올리고 내리는 것이 매우 간단하여, 리눅스와 같이 초보자가 파일 이동 등이 버거운 환경에서도 쉽게 파일 관리를 할 수 있다.
주피터 노트북은 쉘 단위로 코드를 단위 별로 실행할 수 있으므로, 코드 관리가 쉽다.
주피터 노트북의 단점으로는, 코드 자동 완성 기능이 없으므로(물론, 코드를 몇 자 치면, 비슷한 코드들이 올라오게 하는 기능이 있기는 하다.), 코드를 짤 때 조금 불편하다.
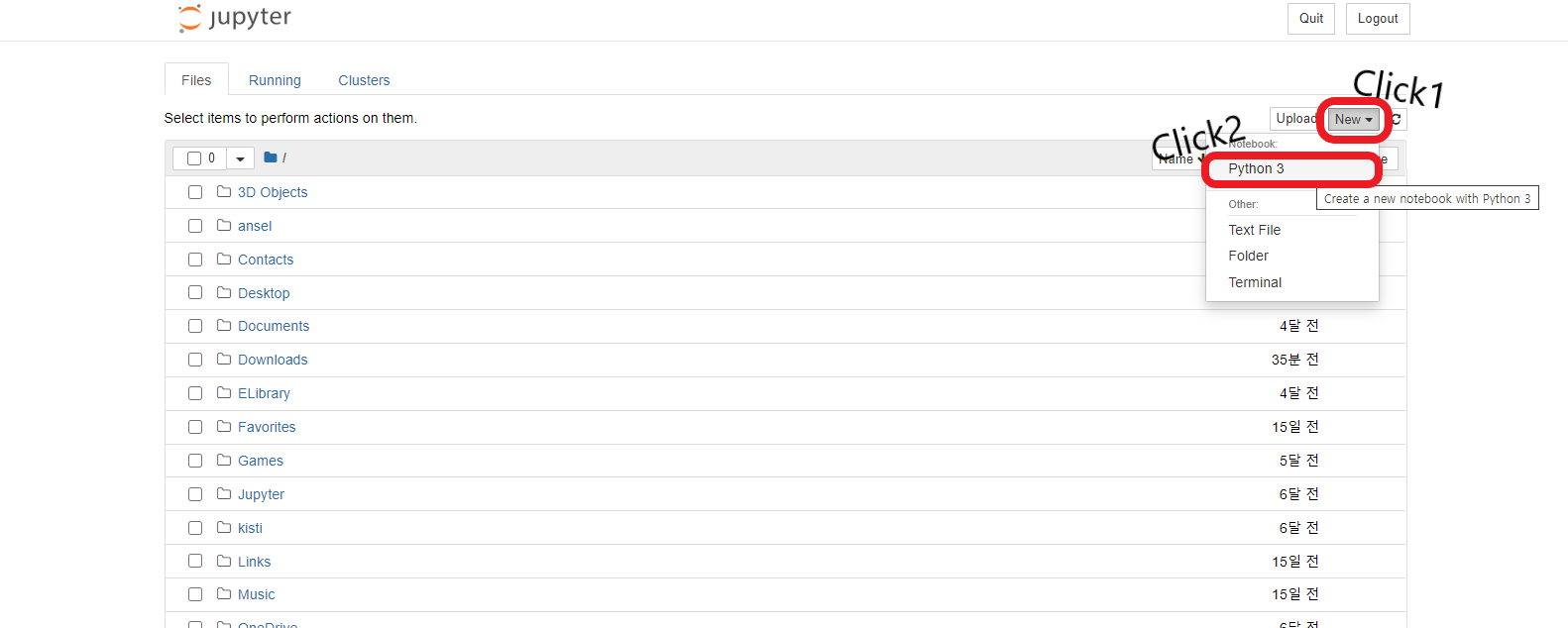
주피터 노트북에서 파이썬을 사용해보자.
New 버튼을 클릭하면 Python3, Text File, Folder, Terminal 이라는 버튼이 있다.
Python3는 Python3를 실행할 수 있는 창을 생성한다.
Text File은 메모장과 같은 파일을 생성한다.
Folder는 말 그대로 Folder를 생성한다. 이를 이용하면 파일 관리가 매우 편해진다.
Terminal을 클리하면 Terminal로 이동되며, 이를 통해 다양한 파일 이동, 삭제, 생성 등을 할 수 있다.
참고로 주피터 노트북으로 R과 같은 다른 언어도 실행 가능하다(이는 추후 진행해보도록 하겠다.)
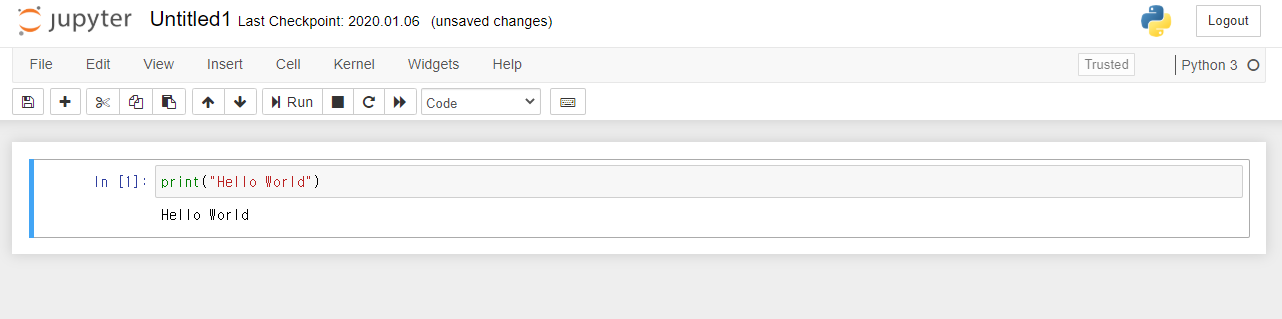
ln[ ]: 옆에 있는 네모 박스에 파이썬 코드를 넣으면, 파이썬 코드를 실행할 수 있다.
코드 실행 방법은 박스가 체크된 상태에서 Ctrl + Enter를 하거나 상단의 Run 버튼을 누르면 된다.
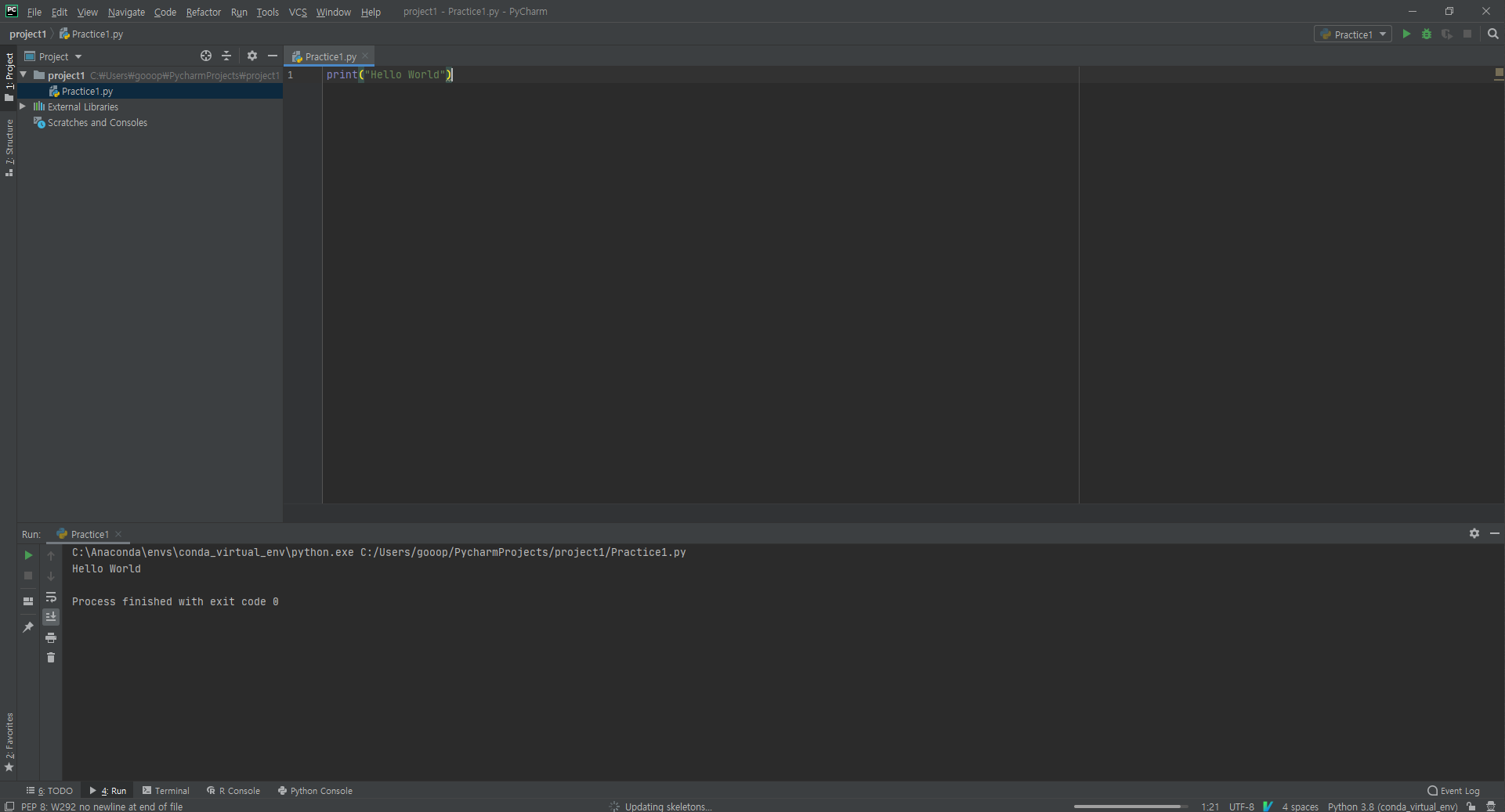
자, print("Hello World")를 타이핑 하고 실행해보자.
지금까지 파이썬과 아나콘다, 주피터 노트북에 대해 설치부터 그 사용법까지 간략하게 살펴보았다.
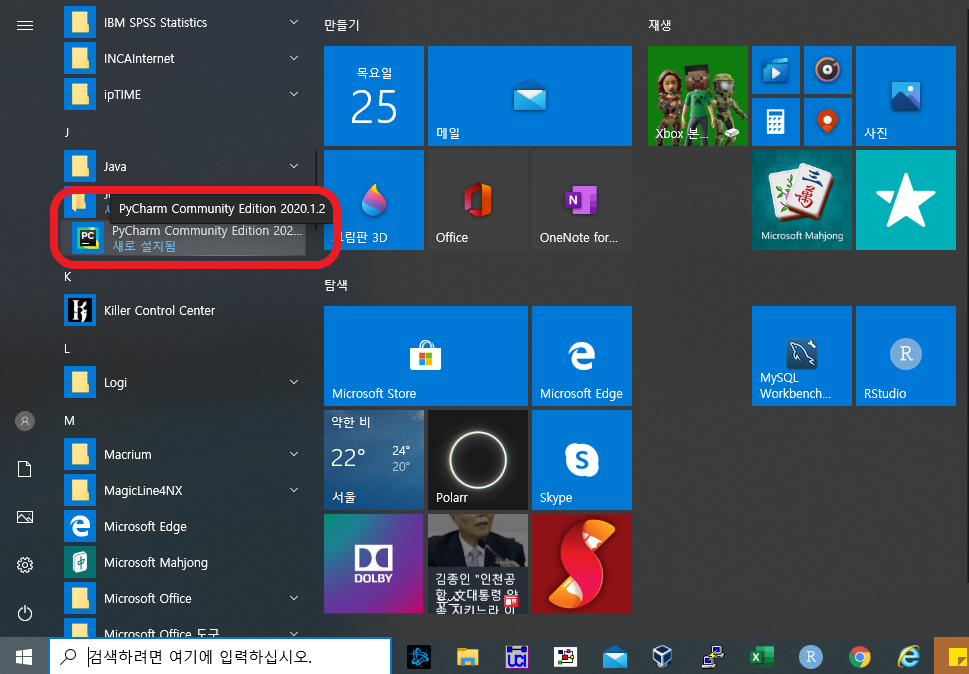
다음 포스트에서는 아나콘다를 보다 수월하게 쓸 수 있는 마치 R의 RStudio와 같은 환경인 파이참(Pycharm)에 설치와 그 사용법에 대해 학습해보도록 하자.
알파고와 이세돌의 대국이 있었던 2016년 이후로, 전 세계에서 가장 핫한 키워드를 꼽으라면, 인공지능과 빅데이터일 것이다.
인공지능 & 빅데이터 분야의 첨단을 달려가는 Data Scientist를 대상으로 2018년 캐글에서 조사한 Data Scientist들이 주로 사용하는 언어에서 압도적인 1위를 한 것은 Python인데, 대체 Python이 무엇이길래 이 빅데이터 시대에 그리도 인기가 좋은지 간략하게 알아보자.
크리스마스 주엔 연구실이 쉰다는 것을 잊고 출근한 귀도 반 로섬(Guido van Rossum)은 너무도 따분했고, 그 심심한 마음을 달래기 위해 만든 것이 그 유명한 파이썬이다. 심지어 이 이름마저도, 뱀과 아무 관련 없이, 제작자가 좋아하던 영국의 코미디 그룹인 몬티 파이썬에서 따온 것이라고 하니.
한국으로 따지자면 설 연휴에 심심하다고 코빅이라는 프로그래밍 언어를 만들어버렸고, 그 언어가 20년이 지나 전 세계적으로 널리 쓰이는 언어가 된 것이나 다름없다.
파이썬의 가장 큰 장점은 문법이 굉장히 쉽다는 것인데, 그 예시로 평소 R을 즐겨 사용했던 필자는, R로는 당신이 만든 코드를 상품화하기 힘들다란 말 한마디에, 파이썬을 공부한 첫날, 바로 파이썬으로 코드를 뒤집어엎는 것이 가능했을 정도로, 학습 난이도가 낮다는 것이다(물론 한 가지 언어를 다룰 수 있는 상황에서 새로운 언어를 익히는 것과 전혀 모르는 상태에서 익히는 것의 난이도는 천지차이다!).
또, R과 달리 UTF-8 기반이기에, 한글을 대상으로 한 텍스트 마이닝이 R보다 편하고, 데이터 타입 변환도 자유로워 오류도 적으며, 서버에서 작업할 때, 한 계정당 한 명만 작업이 가능한 R과 달리, 파이썬은 주피터 노트북 등을 통해, 여러 명이 동시에 붙을 수 있으며, 완성된 파이썬 코드를 동시에 여러 개 실행하여, 손쉽게 병렬 실행을 할 수 있다는 장점이 존재한다. (물론 이 병렬 실행에서 멀티 스레드 난이도는 크게 높지 않으나, py파일 하나당 1개의 코어만 점유한다는 한계점이 존재하기 때문에 마냥 쉽지만은 않다.)
물론 파이썬의 단점이 아예 없는 것은 아니다. 파이썬은 다른 컴파일 언어에 비해 느리고, 프로그래밍을 처음 해보는 사람에게 추천하는 쉬운 언어임에도 워낙 오래되었다 보니, 사용하고자 하는 패키지끼리 호환성 문제가 발생해 잘 돌아가던 코드가 안 돌아가는 일이 종종 발생하고, 몇몇 패키지는 세팅을 하다가 파이썬을 만지고 있는 시간보다 리눅스를 만지고 있는 시간이 더 긴 경우도 있다.
자! 파이썬에 대해선 여기까지 알아보도록 하고, 보다 자세한 내용은 위키피디아나 책을 참고하길 바란다. 이제부터 Data Scientist들에게 가장 사랑받는 언어인 파이썬에 대해 쭉! 학습해보도록 하자.
: dplyr 패키지는 데이터 전처리에서 굉~~~~장히 많이 쓰이는 패키지로, dplyr과 tidyr, reshape2, stringr 이 4가지 패키지만 다룰 수 있어도 데이터 핸들링은 거의 다 할 수 있다고 해도 과언이 아니다.
특히 tidyr, reshape2, stringr은 보다 원초적인 상황(데이터가 지저분하게 섞여 있거나, 텍스트 마이닝을 하는 상황)에서 주로 쓰인다면, dplyr은 공공데이터포털 등과 같은 어느정도 정제된(한 셀에 하나의 원소만 들어가 있는) 원시자료를 사용할 때, dplyr 하나만 있어도 충분하다고 할 정도로 다양한 기능을 제공한다고 할 수 있다.
이제 dplyr 패키지가 얼마나 중요한지는 알겠는데, 데이터 전처리가 대체 무엇이길래 dplyr 패키지가 중요하다는 것일까? 이번엔 데이터 전처리에 대해서 간략하게 알아보자.
데이터 전처리(Data Preprocessing)란?
데이터 전처리는 데이터 가공(Data Manipulation), 데이터 핸들링(Data Handling), 데이터 랭글링(Data Wrangling), 데이터 먼징(Data Munging) 등 다양한 이름으로 불리며, 원시적인 상태의 데이터를 내가 원하는 형태로 바꿔주는 모든 과정을 말한다.
데이터 전처리는 데이터에서 내가 원하는 정보를 찾아내는 데이터 분석의 모든 과정에서 약 80% 가까운 비중을 차지할 정도로 매우 중요한 작업이며, 우리가 아는 회귀분석, 랜덤포레스트, 군집분석 등과 같은 멋들어진 이름을 가진 분석 기법들은 이 데이터 전처리 작업을 거치지 않는다면, 실시할 수 없다.
몇 몇 데이터 분석가는 데이터 전처리를 단순하고, 귀찮고, 아까운 시간이 소모되는 과정이라고도 생각하는데, 데이터 전처리 과정에서 데이터를 세세하게 뜯어보며 내가 원하는 형태로 만들어가다보면, 데이터 자체에 대한 이해와 데이터 자체의 특성을 이용해 보다 효율적이고 논리적인 변수를 만들어낼 수 있고, 사용하고자 하는 분석 기법에 맞게 데이터를 만들어주는 과정에서 분석 기법에 대한 심층적인 이해와 같이 다양한 insight를 얻을 수도 있다.
그만큼 데이터 전처리는 중요하고, 데이터 전처리 과정에서 코딩 실력 역시 많이 늘게 되므로, 꼭 데이터 전처리의 필수 패키지인 dplyr를 공부해보도록 하자.
dplyr 패키지의 특징
R 데이터 타입의 꽃이라고 할 수 있는 데이터 프레임 처리에 특화된 패키지이다.
C++ 을 기반으로 만들어졌기 때문에 매우 빠르다.
파이프 라인(%>%)이라는 연산자를 사용할 수 있으며, 그로인해 코드의 가독성이 매우 크게 올라간다.
파이프 라인의 단축키는 Alt + Shift + m 이다.
R을 효과적으로 사용하려면 apply함수(다음에 자세히 다루겠다.)의 기능을 아주 쉽게 쓸 수 있다.
rename() : dplyr 패키지의 rename()이란 함수로, 기존의 dataframe에서 컬럼의 이름을 바꾸려면, colnames()란 함수를 이용해서 벡터로 새로운 컬럼명이 포함된 컬럼의 이름 벡터를 넣어줘야했지만, rename()함수는 내가 원하는 컬럼의 이름만 바꿀 수 있다.
주요 Parameter rename(data, afterColumnName1 = beforeColumnName1, afterColumnName2 = beforeColumnName2) 바꾼 후 컬럼의 이름 = 바꾸기 전 컬럼 이름으로 넣으면 된다.
연속형 변수 중에 결측값이 가장 적을 것으로 예측되는 height에 대해 요약 통계량을 생성해보자.
## `summarise()` regrouping output by 'gender' (override with `.groups` argument)
## # A tibble: 5 x 8
## # Groups: gender [3]
## gender isHuman height_sum height_mean height_sd height_min height_max `n()`
## <chr> <chr> <int> <dbl> <dbl> <int> <int> <int>
## 1 feminine Human NA NA NA NA NA 9
## 2 feminine NonHum~ 1353 169. 33.1 96 213 8
## 3 masculine Human NA NA NA NA NA 26
## 4 masculine NonHum~ NA NA NA NA NA 40
## 5 <NA> <NA> NA NA NA NA NA 4
분석 결과 대부분이 <NA>로 표시된 것을 알 수 있다.
<NA>는 값이 없음을 의미한다.
데이터 분석을 하기 위해선 이러한 내가 원하지 않는 결과가 나온 경우 그 원인을 파악해보아야한다.
위에서 말했듯이 summarise() 함수는 분석하려는 대상인 데이터 안에 결측값(<NA>)이 단 하나라도 있는 경우, 요약통계량을 <NA>로 출력한다. 이 경우 na.rm = TRUE를 각 요약 통계량 안에 삽입하여, 다시 결과를 출력해보자.
해당 결과가 나온 원인을 알기 위해 gender와 isHuman에 대한 결측값 여부에 대한 빈도분석을 실시해보자.
is.na(백터) : 벡터 안에 결측값이 있는 경우, 해당 결측값을 TRUE로 결측값이 아닌 값을 FALSE로 나타낸다.
table(is.na(벡터)) :위 함수를 이용하면, 해당 벡터 안에 몇 개의 결측값이 존재하는지 쉽게 알 수 있다.
# is.na()함수를 이용해서 결측값의 갯수를 파악해보았다.
table(is.na(starwars$gender))
## FALSE TRUE
## 83 4
table(is.na(starwars$isHuman))
## FALSE TRUE
## 83 4
두 함수 모두 결측값이 각각 4개 존재하는 것으로 나타났다.
스칼라에서 공부한 Boolean의 성격을 이용해보면, 두 변수의 결측값이 동일한 객체(행)에 대한 것인지를 볼 수 있다.
# 두 변수의 결측값이 중복되는 것인지 확인해보자.
gender = is.na(starwars$gender)
isHuman = is.na(starwars$isHuman)
table(gender + isHuman)
## 0 2
## 83 4
gender와 isHuman이라는 2개의 벡터를 is.na()를 이용해서 TRUE와 FALSE 2개의 인자로 구성된 벡터를 만들었다.
두 벡터를 합치는 경우, 객체(행)에 대한 위치는 두 벡터 모두 동일하므로, 2개 벡터가 같은 객체에 대해 결측값으로 구성된 경우 2가 나올 것이며(TRUE + TRUE = 2), 2개 벡터가 서로 다른 객체에 대해 결측값이 있는 경우 1이 나올 것이다.(TRUE + FALSE = 1)
결과가 0과 2로 이루어져있으며, 2의 숫자가 4개인 것을 보면, gender와 isHuman의 결측값을 가진 객체가 일치하는 것을 알 수 있다.
※ summarise 함수에서 na.rm = TRUE의 주의 사항
gender와 isHuman의 결측값이 동일한 객체(행)에 대해 존재한다는 것을 알았으므로, 이번엔 결측값이 있는 행들을 분석 대상에서 제외하고 보도록 하자.
일반적으로 결측값 제거는 함부로 해서는 안되지만, 이는 사회과학에서 그 결측값의 발생이 어떠한 의도에 의해 발생했을 위험이 있기 때문이다.
해당 데이터는 할리우드 영화인 Starwars에서 캐릭터들의 이름과 키, 몸무게, 머리카락색과 같은 개인정보가 담긴 데이터이다. 결측값이 발생한 대상에 대해 구체적으로 보도록 하자.
위, 아래 표를 비교해보면 총합, 평균, 표준편차, 최소값, 최댓값은 동일하나, n()이 서로 다르고 , 5번째 행이 위엔 없으나 아래에 있는 것을 볼 수 있다.
이는 위의 na.omit()을 이용해서 결측값이 있는 행을 모두 제거한 결과는 행에 서 결측값이 있는 것을 모두 제거하였기 때문에, gender, isHuman, height 이 3가지 변수 중에 <NA>를 하나라도 가진 객체를 분석 대상에서 아예 제거해버렸기 때문에 키에 대한 n()을 제외한 모든 요약 통계량은 같게 나오지만, n()은 na.rm이라는 인자가 아예 존재하지 않기 때문에 다른 결과가 나온 것이다.
즉, 간단하게 말하자면 n()는 결측값이 있던 없던 대상의 수를 세버려기 때문에 height에 결측값이 있다할지라도 수를 세어버리고, na.omit()으로 결측값이 있는 행을 모두 제거한 결과는 성별, 종족이 측정된 값이며, 키를 측정한 대상에 한정한 결과를 가져오는 것이다.
na.rm은 단순하게 해당 벡터에 대해서만 결측값을 제거하므로, na.rm을 적용할 수 없는 n()은 조금 조심해서 사용하도록 하자.
위 문제를 명확하게 해결하기 위해선 분석 대상에 대한 명확한 정의가 필요하다.
데이터 합치기
left_join() : 두 데이터 프레임을 동일한 열을 기준으로 열로 합치는 경우 left_join()을 사용한다.
left_join(기준이 되는 합쳐지는 쪽, 합칠 데이터)
기준이 될 ID와 같은 동일한 컬럼이 필요하다.
left_join()을 응용하여 특정 변수를 기준으로 새로운 변수를 추가할 수 있다.
데이터는 한 번에 2개만 합치는 것이 가능하다.
cbind()는 열의 길이만 같다면 통으로 합치지만, left_join()은 기준 변수를 제외한 변수들이 기준 변수의 위치에 맞춰서 합춰진다.
즉, left_join()에서 기준으로 사용할 열에 일치하는 값만 존재한다면(전부 존재 하지 않아도 된다.) 두 데이터 프레임의 길이가 서로 다르더라도 붙일 수 있다.
기준이 되는 합쳐지는 쪽과 합칠 데이터에 대하여, 기준 컬럼의 인자가 동일한 집합이 아닌 경우에도 합쳐지며,기준이 되는 합쳐지는 쪽의 기준 컬럼에 없는 인자들은 모두 NA로 합쳐진다.
bind_rows() : 두 데이터 프레임의 열 이름이 동일한 경우 행을 위주로 합치는 경우, bind_rows()를 사용한다.
세로로 합치는 경우, 합치는 두 데이터의 변수명이 일치해야한다.
동일하지 않다면 rename()을 하거나, 일치하지 않는 변수를 제거해주자.
합칠 두 데이터 프레임의 컬럼별 변수 타입이 동일해야한다.
특히 character와 factor는 단순하게 눈으로 비교해서는 같게 보이므로, 꼭 주의하도록 하자.
# 한 열이 동일한 2개의 데이터 프레임을 한 열을 기준으로 합쳐보자.
mid_examResult = data.frame(name = c("민철", "재성", "현승", "기훈", "윤기"), midterm = c(60, 80, 90, 70, 85))
final_examResult = data.frame(name = c("민철", "재성", "현승", "기훈", "윤기"), finalterm = c(80, 75, 88, 65, 90))
left_join(mid_examResult, final_examResult)
이번 포스트에서 공부한 rename, mutate, filter, select, arrange, group_by, summarise, left_join, bind_rows는 개인적으로 dplyr 패키지에서 이것만 알아도 충분하다 싶어서 뽑은 함수들이며, 추후 dplyr에 대해 더 학습을 하다가, 괜찮은 함수가 있다면, 그 함수들도 추가해보도록 하겠다.