728x90
반응형

이전 포스트까지 Wide & Deep Learning 모델을 사용해서 다중 입력 모델을 만들어보았다. 이번엔 이전 모델에 추가로 출력층을 추가하여 출력층을 2개로 만들어 보도록 하자.
다중 출력 모델
- 일반적으로 다중 출력 모델을 사용하는 이유는 다음과 같다.

- 프로세스가 서로 독립적인 경우:
동일한 데이터 셋에서 두 개 이상의 출력층을 생성하지만, 출력된 결과는 전혀 다른 작업을 위해 실행되는 경우로, 예를 들어 인터넷 사용 Log 데이터를 기반으로, 대상의 관심사 파악(분류 모델)과 인터넷 사용률 예측(회귀 모델)은 별개의 목적을 위해 진행된다. - 프로세스가 한 목적을 위해 상호 보완적으로 이루어지는 경우:
하나의 목적을 이루기 위해 두 개 이상의 출력 값이 필요하여, 동일한 데이터 셋에서 두 개 이상의 출력층을 뽑아내는 경우로, 예를 들어 영상 속 물건을 인식하는 모델을 만든다면, 영상 속 물건의 위치(회귀 모델)와 물건의 종류(분류 모델)를 동시에 파악해야 한다. - 규제 도구로써의 다중 출력 모델:
하위 네트워크가 나머지 네트워크에 의존하지 않고, 그 자체로 유용한 성능을 내는지 확인을 하기 위한 규제 기법으로 사용
이번 포스트에서는 Wide & Deep Learning model에 다중 출력 모델을 규제 도구로써 사용해보도록 하자.
1. 규제 도구로써의 다중 출력 모델

- 보조 출력층(Auxiliary Output)을 통해, 하위 네트워크가 나머지 네트워크에 의존하지 않고 그 자체로 유용한 것을 학습하는지 확인한다. 위 모델대로라면, Deep model에서의 출력된 값이 Wide model과의 연결로 인해, 원하는 결과를 뽑아내는 것인지, Deep model으로 인해 그러한 결과가 나왔는지 확인할 수 있다.
- 이를 통해, 과대 적합을 감소시키고, 모델의 일반화 성능이 높이도록 학습에 제약을 가할 수 있다.
2. 모델 생성 이전까지의 코드 가져오기
- 이전 포스트에서 만들었던, 모델 이전까지의 코드를 모두 가지고 온다.
- 입력층이 2개일 때는 입력 데이터를 목적에 맞게 나눴어야 했지만, 이번엔 출력층이 다른 데이터를 출력하는 것이 아니라, 보조 출력층(Auxiliary Output)과 주 출력층(Main Output)이 동일한 정답에 대해 어느 정도의 손실 값과 정확도를 내보내는지 알고 싶은 것이므로, Label dataset을 나누지 않아도 된다.
#################################### Import Module ####################################
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import callbacks
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import (Input, Dense, concatenate)
########################################################################################
#################################### Import Dataset ####################################
# 캘리포니아 데이터 가져오기
Rawdict = fetch_california_housing()
CaliFornia_DF = pd.DataFrame(Rawdict.data, columns=Rawdict.feature_names)
########################################################################################
#################################### Data Handling #####################################
# 데이터를 쪼개기 좋게 변수의 순서를 바꾸자
CaliFornia_DF = CaliFornia_DF[["HouseAge", "Population", "Latitude", "Longitude", "MedInc",
"AveRooms", "AveBedrms", "AveOccup"]]
# train, validation, test set으로 쪼갠다.
X_train_all, X_test, y_train_all, y_test = train_test_split(CaliFornia_DF.values, Rawdict.target, test_size = 0.3)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_all, y_train_all, test_size = 0.2)
# 정규화시킨다.
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)
# 데이터 셋을 input layer의 수만큼 쪼갠다.
X_train_A, X_train_B = X_train[:, :1], X_train[:,1:]
X_valid_A, X_valid_B = X_valid[:, :1], X_valid[:,1:]
X_test_A, X_test_B = X_test[:, :1], X_test[:,1:]
########################################################################################
3. 모델 생성
######################################## Model ########################################
input_A = Input(shape=[1], name = "deep_input")
input_B = Input(shape=[7], name = "wide_input")
hidden1 = Dense(30, activation="relu", name = "hidden1")(input_A)
hidden2 = Dense(30, activation="relu", name = "hidden2")(hidden1)
concat = concatenate([input_B, hidden2], name = "concat")
output = Dense(1, name="main_output")(concat)
# 보조 출력층 생성
aux_output = Dense(1, name="aux_output")(hidden2)
model = keras.Model(inputs=[input_A, input_B], outputs=[output, aux_output])
########################################################################################>>> model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
deep_input (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
hidden1 (Dense) (None, 30) 60 deep_input[0][0]
__________________________________________________________________________________________________
wide_input (InputLayer) [(None, 7)] 0
__________________________________________________________________________________________________
hidden2 (Dense) (None, 30) 930 hidden1[0][0]
__________________________________________________________________________________________________
concat (Concatenate) (None, 37) 0 wide_input[0][0]
hidden2[0][0]
__________________________________________________________________________________________________
main_output (Dense) (None, 1) 38 concat[0][0]
__________________________________________________________________________________________________
aux_output (Dense) (None, 1) 31 hidden2[0][0]
==================================================================================================
Total params: 1,059
Trainable params: 1,059
Non-trainable params: 0
__________________________________________________________________________________________________- 앞서 학습했던 방법처럼 보조 출력층 생성 역시 Keras API 함수로 구현하는 것은 꽤 단순하다.
- 보조 출력층(aux_output)과 데이터를 받는 층(hidden2)을 연결시키고, model에서 outputs을 2개 다 잡아주면 된다.
4. 모델 컴파일
- 다중 입력 모델과 달리 다중 출력 모델에서는 모델 컴파일 방법이 바뀌게 된다.
- 이는, 컴파일에서 출력층에서 모델을 평가하게 되는 손실 함수를 결정하기 때문이고, 이 손실 함수는 출력층마다 다르게 설정해야 하기 때문이다.
# 모델 컴파일
model.compile(optimizer=Adam(learning_rate=0.005),
loss = ["msle", "msle"],
metrics=["accuracy"],
loss_weights=[0.9, 0.1])- 최적화나 모델 평가 지표는 출력층의 수와 상관없기 때문에 바뀌지 않는다.
- 손실 함수는 출력층이 2개가 되었으므로, 2개를 잡아줘야 한다(만약, 손실 함수를 하나만 잡아준다면, 모든 출력의 손실 함수가 같다고 가정한다 - 위 경우에는 출력층이 회귀모형이므로, msle로 같은 손실 함수를 사용하므로, msle 하나만 사용해도 된다).
- loss_weights: 출력 층별 손실 값의 가중치를 정해준다. 케라스는 기본적으로 출력된 손실 값들을 모두 더해 최종 손실을 구하며, 이를 기반으로 학습을 한다. 여기서 사용된 보조 출력은 규제로 사용되었기 때문에 주 출력이 더 중요하다. 그러므로, 주 손실 값에 더 많은 가중치를 부여하였다.
5. 모델 학습 및 평가
- 모델 학습과 평가에서의 차이는 Label 역시 각 출력층에 맞게 2개가 들어가야 한다는 것이다.
- 해당 다중 출력 모델은 규제 목적으로 보조 출력층을 추가한 것이므로, 동일한 데이터를 label로 사용해도 된다.
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)
# 학습
history = model.fit([X_train_A, X_train_B], [y_train, y_train],
epochs=300,
batch_size = 32,
validation_data=([X_valid_A, X_valid_B], [y_valid, y_valid]),
callbacks=[early_stop])Epoch 1/300
362/362 [==============================] - 3s 6ms/step - loss: 0.2162 - main_output_loss: 0.1988 - aux_output_loss: 0.3726 - main_output_accuracy: 0.0027 - aux_output_accuracy: 0.0023 - val_loss: 0.0697 - val_main_output_loss: 0.0633 - val_aux_output_loss: 0.1276 - val_main_output_accuracy: 0.0048 - val_aux_output_accuracy: 0.0048
Epoch 2/300
362/362 [==============================] - 1s 2ms/step - loss: 0.0650 - main_output_loss: 0.0584 - aux_output_loss: 0.1243 - main_output_accuracy: 0.0026 - aux_output_accuracy: 0.0026 - val_loss: 0.0619 - val_main_output_loss: 0.0544 - val_aux_output_loss: 0.1295 - val_main_output_accuracy: 0.0048 - val_aux_output_accuracy: 0.0048
Epoch 3/300
362/362 [==============================] - 1s 2ms/step - loss: 0.0584 - main_output_loss: 0.0509 - aux_output_loss: 0.1260 - main_output_accuracy: 0.0027 - aux_output_accuracy: 0.0027 - val_loss: 0.0598 - val_main_output_loss: 0.0522 - val_aux_output_loss: 0.1279 - val_main_output_accuracy: 0.0048 - val_aux_output_accuracy: 0.0048
Epoch 4/300
362/362 [==============================] - 1s 2ms/step - loss: 0.0555 - main_output_loss: 0.0480 - aux_output_loss: 0.1229 - main_output_accuracy: 0.0018 - aux_output_accuracy: 0.0018 - val_loss: 0.0591 - val_main_output_loss: 0.0514 - val_aux_output_loss: 0.1281 - val_main_output_accuracy: 0.0045 - val_aux_output_accuracy: 0.0048
...
Epoch 54/300
362/362 [==============================] - 0s 1ms/step - loss: 0.0522 - main_output_loss: 0.0444 - aux_output_loss: 0.1227 - main_output_accuracy: 0.0024 - aux_output_accuracy: 0.0024 - val_loss: 0.0556 - val_main_output_loss: 0.0476 - val_aux_output_loss: 0.1276 - val_main_output_accuracy: 0.0045 - val_aux_output_accuracy: 0.0048
Epoch 55/300
362/362 [==============================] - 1s 1ms/step - loss: 0.0524 - main_output_loss: 0.0446 - aux_output_loss: 0.1225 - main_output_accuracy: 0.0026 - aux_output_accuracy: 0.0026 - val_loss: 0.0540 - val_main_output_loss: 0.0460 - val_aux_output_loss: 0.1263 - val_main_output_accuracy: 0.0045 - val_aux_output_accuracy: 0.0048
Epoch 56/300
362/362 [==============================] - 1s 2ms/step - loss: 0.0525 - main_output_loss: 0.0448 - aux_output_loss: 0.1215 - main_output_accuracy: 0.0024 - aux_output_accuracy: 0.0024 - val_loss: 0.0539 - val_main_output_loss: 0.0458 - val_aux_output_loss: 0.1265 - val_main_output_accuracy: 0.0048 - val_aux_output_accuracy: 0.0048
Epoch 57/300
362/362 [==============================] - 0s 1ms/step - loss: 0.0535 - main_output_loss: 0.0457 - aux_output_loss: 0.1234 - main_output_accuracy: 0.0033 - aux_output_accuracy: 0.0033 - val_loss: 0.0543 - val_main_output_loss: 0.0463 - val_aux_output_loss: 0.1264 - val_main_output_accuracy: 0.0045 - val_aux_output_accuracy: 0.0048>>> model.evaluate([X_test_A, X_test_B], [y_test, y_test])
194/194 [==============================] - 0s 1ms/step - loss: 0.0533 - main_output_loss: 0.0454 - aux_output_loss: 0.1241 - main_output_accuracy: 0.0029 - aux_output_accuracy: 0.0032
[0.05328081175684929,
0.04541592299938202,
0.12406466901302338,
0.0029069767333567142,
0.0032299740705639124]- 이전과 달리 값이 굉장히 많이 나오기 때문에 이를 파악하기 어려울 수 있는데, 그 내용은 생각보다 상당히 단순하다.
- 손실 값은 loss: 0.0533, main_output_loss: 0.0454, aux_output_loss: 0.1241이 나왔다.
- 여기서 loss만 신경 쓰면 된다. 위에서 우리는 main_output_loss와 aus_output_loss의 가중치를 0.9, 0.1로 부여하였는데, loss는 각 손실 값에 해당하는 가중치를 곱하여 합한 값이기 때문이다.
$$ 0.0533 = 0.9*0.0454 + 0.1*0.1241 $$
- Deep model의 손실 값과 Wide & Deep Learning model의 손실 값을 동시에 반영하여, 총 손실 값을 계산하였으므로, Deep model이 Wide model과의 결합 없이도 우수한 성능을 보이는 것을 알 수 있다.
- 주 출력층의 Accuracy는 0.0029, 보조 출력층의 Accuracy도 0.0032로 Deep model, Wide & Deep Learning model 모두 Accuracy가 괜찮게 나왔다. 이로 인해 Deep model 자체만으로도 우수한 성능을 보이는 것을 알 수 있다.
5.1. 손실 값과 정확도를 시각화해보자.
def Drawing_Scalars(history_name):
history_DF = pd.DataFrame(history_name.history)
# 그래프의 크기와 선의 굵기를 설정해주었다.
history_DF.plot(figsize=(12, 8), linewidth=3)
# 교차선을 그린다.
plt.grid(True)
plt.legend(loc = "upper right", fontsize =15)
plt.title("Learning Curve", fontsize=30, pad = 30)
plt.xlabel('Epoch', fontsize = 20, loc = 'center', labelpad = 20)
plt.ylabel('Variable', fontsize = 20, rotation = 0, loc='center', labelpad = 40)
# 위 테두리 제거
ax=plt.gca()
ax.spines["right"].set_visible(False) # 오른쪽 테두리 제거
ax.spines["top"].set_visible(False) # 위 테두리 제거
plt.show()
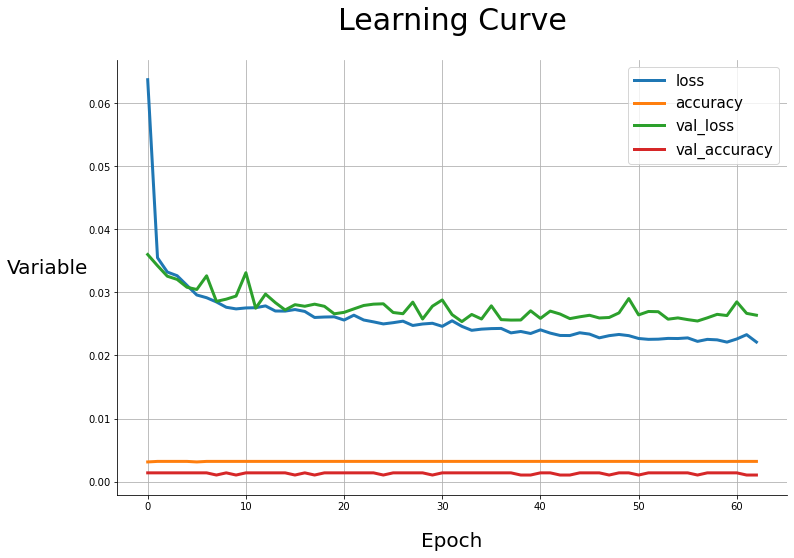
Drawing_Scalars(history)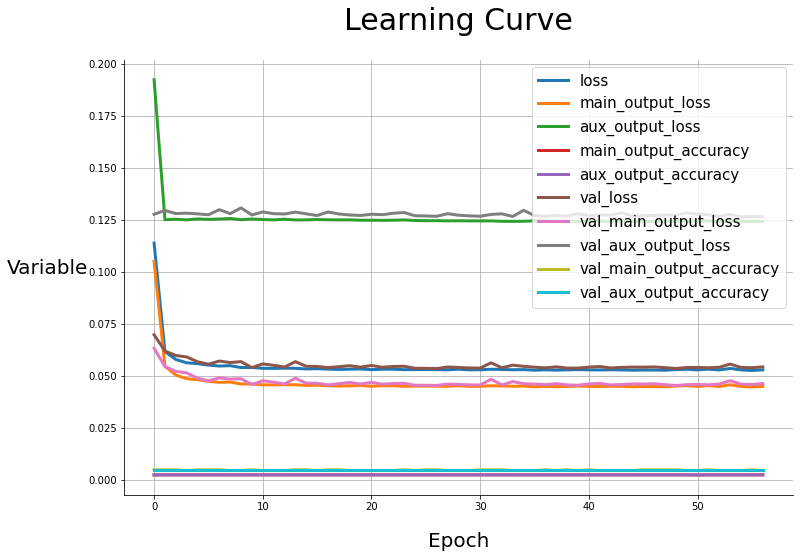
- 굉장히 많은 지표들이 추가되었지만, Early Stopping의 기준으로 사용한 val_loss를 본다면, patience가 30이었으므로, epochs 27에서 모델이 수렴하였다는 것을 알 수 있다.
[참고 자료]

이번 포스트에서는 다중 출력 모델을 Wide & Deep Learning model에서의 규제 기법으로 사용해보았다. Deep model의 결괏값에 대한 평가가 모델 전체 평가에 반영되었으므로, Deep Model의 일반화가 잘 이루어진 모델이 만들어졌다고 할 수 있다.
지금까지 Wide & Deep Learning 모델을 기반으로 다중 입력, 다중 출력 모델을 만드는 방법과 이를 통해 Wide & Deep Learning Model을 더 잘 사용할 수 있도록 해보았다.
728x90
반응형
'Machine Learning > TensorFlow' 카테고리의 다른 글
| Tensorflow-4.2. Wide & Deep Learning(2) - 다중입력모델 (0) | 2021.02.24 |
|---|---|
| Tensorflow-4.1. Wide & Deep Learning(1) - 함수형 API 사용하기 (0) | 2021.02.23 |
| Tensorflow-4.0. 다층 퍼셉트론을 이용한 회귀모형 만들기 (0) | 2021.02.23 |
| Tensorflow-3.8. 이미지 분류 모델(8)-모델 저장과 불러오기 (0) | 2021.02.17 |
| Tensorflow-3.7. 이미지 분류 모델(7)-조기 종료와 콜벡 (0) | 2021.02.17 |