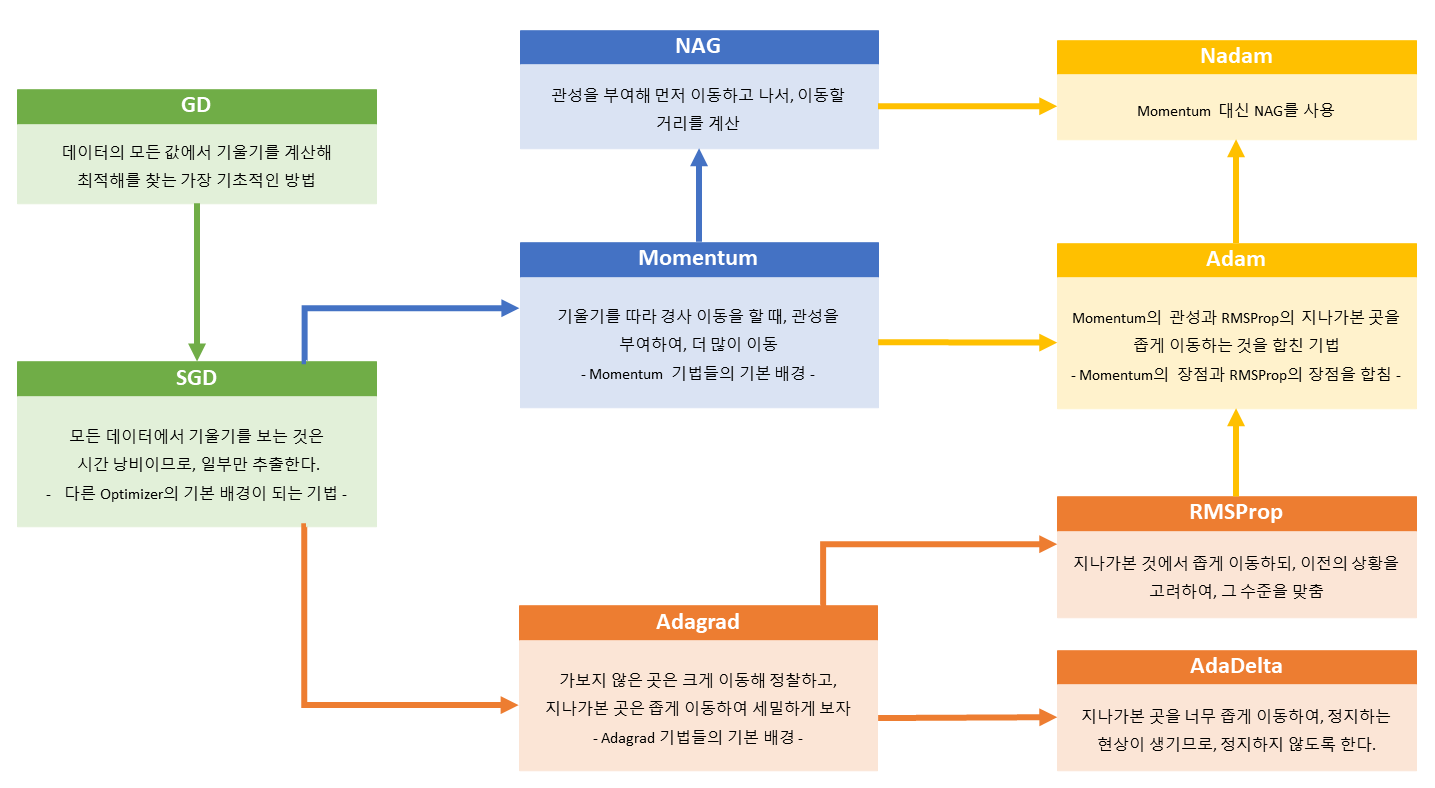
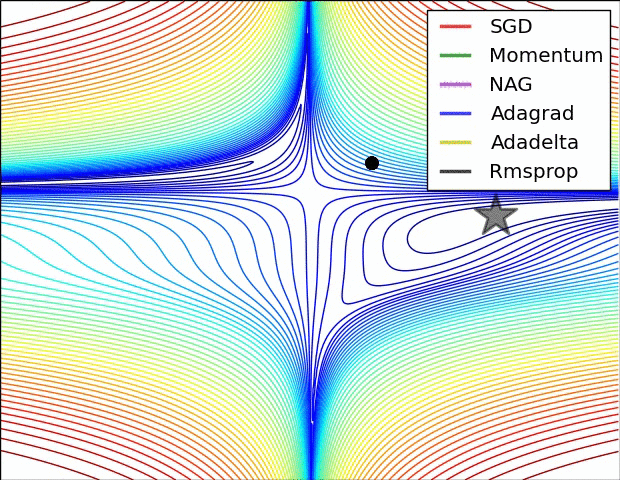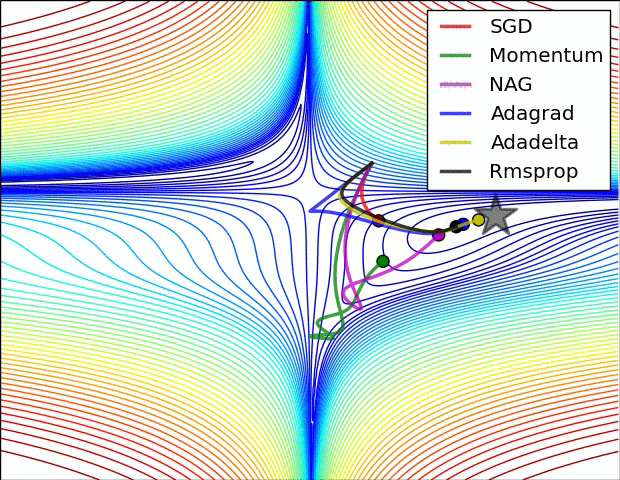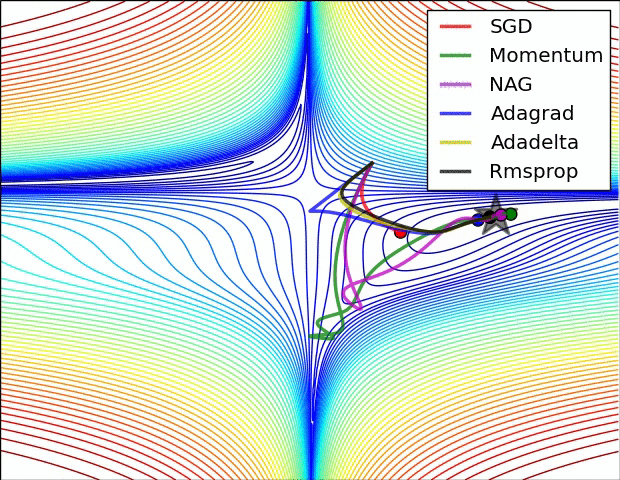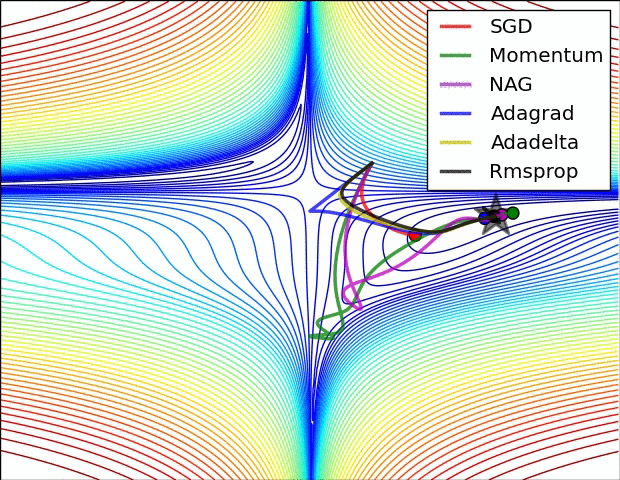
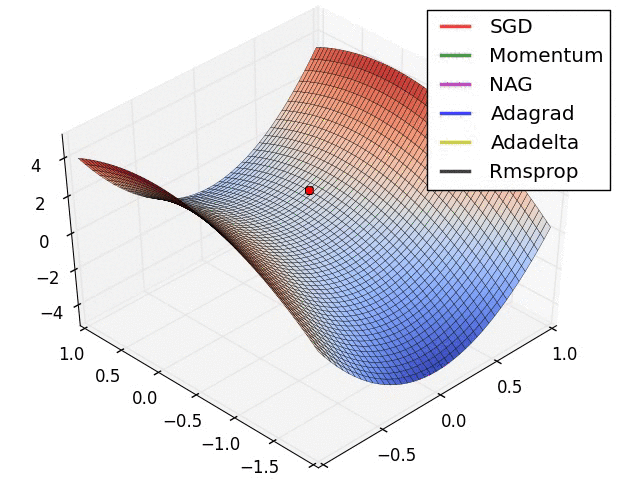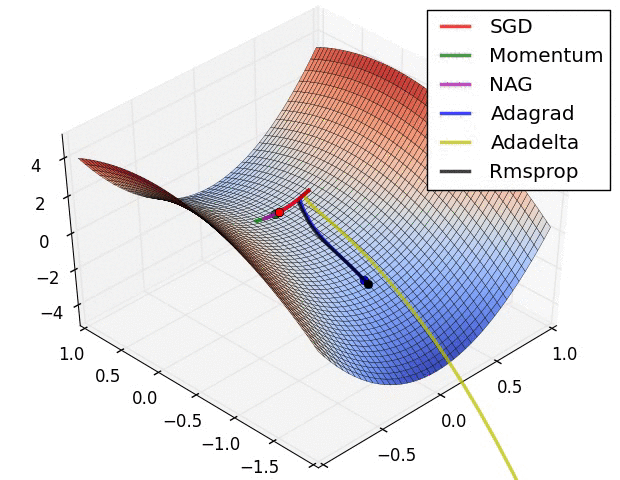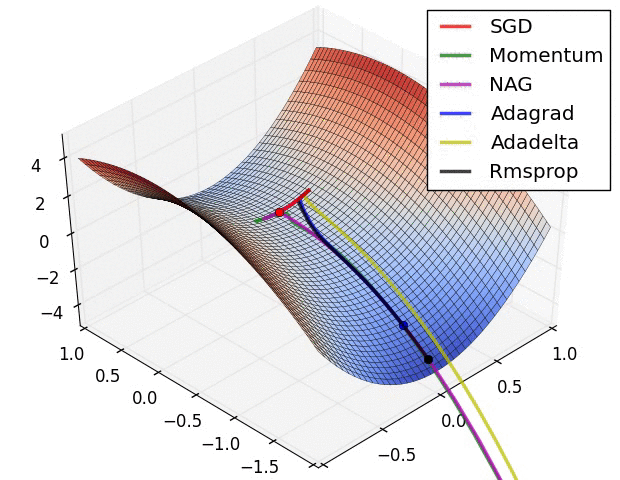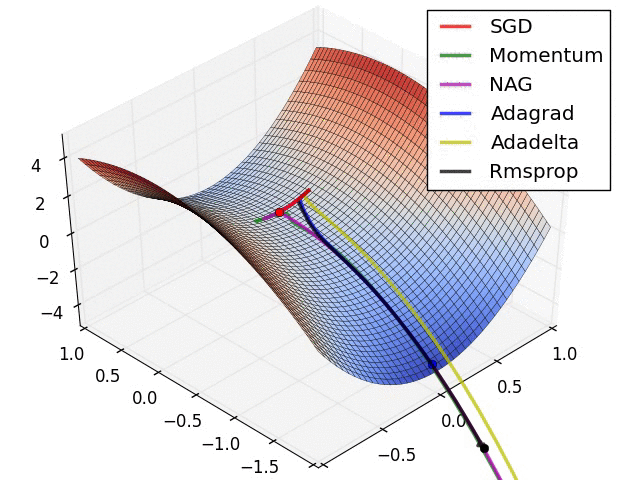
이전 포스트에서 모델을 생성해보고, 생성된 모델의 정보를 살펴보았다. 이번 포스트에서는 모델을 컴파일에 대해 학습해보도록 하겠다.
모델 컴파일
0. 이전 코드 정리
# Import Module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout, Flatten)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
지난 포스트에서 MNIST 데이터 셋을 사용하여, 검증 셋(Validation set)을 생성해보았다. 이번 포스트에서는 Keras의 중심인 모델을 만들어보도록 하겠다.
모델 생성
0. 이전 코드 정리
# Import Module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
################################### Function ###################################
# Data 시각화
def show_images(dataset, label, nrow, ncol):
# 캔버스 설정
fig, axes = plt.subplots(nrows=nrow, ncols=ncol, figsize=(2*ncol,2*nrow))
ax = axes.ravel()
xlabels = label[0:nrow*ncol]
for i in range(nrow*ncol):
image = dataset[i]
ax[i].imshow(image, cmap='gray')
ax[i].set_xticks([])
ax[i].set_yticks([])
ax[i].set_xlabel(xlabels[i])
# 빈 칸 없이 꽉 채우기
plt.tight_layout()
plt.show()
################################################################################
이전에 만들었던 모델들에 들어간 데이터들은 1차원 배열이 n개의 row로 구성된 형태였다.
>>> train_images.shape
(60000, 28, 28)
그러나, 이번 데이터셋은 28*28인 행렬이 60000개 row로 쌓인 형태다.
이때 평활(Flatten)이라는 개념이 추가로 등장한다.
모델을 먼저 만들어보자.
# 모델 생성
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28], name="Flatten"))
model.add(Dense(300, activation="relu", name="Hidden1"))
model.add(Dense(200, activation="relu", name="Hidden2"))
model.add(Dense(100, activation="relu", name="Hidden3"))
model.add(Dense(10, activation="softmax", name="Output"))
각 Layer를 구분하기 쉽도록 name이라는 parameter를 추가해주었다.
이전과 달리 Flatten이라는 Layer가 새로 추가되었다.
Flatten Layer는 입력된 2차원 배열을 1차원 배열로 만들어주는 전처리용 Layer다.
한 Row가 X = (1, 28, 28)인 데이터셋을 X.reshape(-1, 28*28)으로 형 변환해준다고 생각하면 된다.
>>> X = train_images[0]
>>> X.reshape(-1, 28*28).shape
(1, 784)
평활 Layer 통과는 각 Row에 적용되므로, 전체 데이터 셋의 형태가 (60000, 28, 28)에서 (60000, 784)로 바뀐다고 생각해도 좋다.
2. 은닉층 설정하기
지금까지의 포스팅에선 은닉층의 수와 은닉층에 있는 노드의 수를 정할 때, 어째서 이렇게 구성하였는지 설명하지 않았다. 이번에는 은닉층을 설정할 때, 무엇을 인지한 상태로 은닉층을 만들어야 하는지에 대해 학습해보도록 하겠다.
2.1. 은닉층의 개수
은닉층의 개수가 1개인 경우를 얕은 신경망이라고 하며, 2개 이상인 경우를 심층 신경망이라고 한다.
이론적으로 입력층, 은닉층, 출력층으로 3개의 층만 있는 경우에도 뉴런수만 충분하다면 아주 복잡한 함수도 모델링할 수 있다. George Cybenko(1989), Approximation by superpositions of a sigmoidal function - 조지 시벤코의 시벤코 정리: 뉴런 수만 무한하다면 은닉층 하나로 어떤 함수도 근사할 수 있다.
그러나, 심층 신경망은 얕은 신경망보다 적은 노드를 사용하여, 과적합 문제에서 비교적 자유롭고, 얕은 신경망보다 적은 epochs로 최적해에 수렴하게 된다.
이는 은닉층의 수가 늘어날수록, 저수준에서 고수준으로 체계적으로 구조를 모델링할 수 있기 때문이다.
예를 들어, 3개의 은닉층을 사용해 사람을 구분하는 모델을 만들고자 한다면, Hidden1에서는 가장 저수준의 구조인 사람과 배경을 구분하는 일을, Hidden2에서는 사람의 머리, 몸, 키 등을 구분하는 일을, Hidden3에서는 가장 고수준인 사람의 얼굴과 머리스타일을 구분하도록 모델링하게 된다.
이러한 계층 구조는 심층 신경망이 새로운 데이터에 대해 일반화하는 능력도 향상하게 해 준다.
계층 구조는 기존 모델에 추가 기능이 생긴 업그레이드된 모델을 만들 때, 기존 모델의 파라미터를 하위 은닉층에서 재사용해 훈련을 진행할 수 있다. 이를전이 학습(Transfer Learning)이라 한다.
2.2. 은닉층의 뉴런 개수
데이터 셋에 따라 다르긴 하지만 모델에서 은닉층의 뉴런 수를 정할 땐, 다음과 같은 경향이 있다.
일반적으로 첫 번째 은닉층을 제일 크게 하는 것이 도움된다.
만약 한 층의 뉴런 수가 지나치게 적다면, 전달되는 정보 중 일부가 사라져 버릴 수 있다.
깔때기 형태:은닉층의 구성은 일반적으로 각 층의 뉴런의 수를 점차 줄여가며, 깔때기처럼 구성한다. 이는 저수준의 많은 특성이 고수준의 적은 특성으로 합쳐질 수 있기 때문이다.
직사각형 형태: 모든 은닉층의 뉴런 수를 같게 함. 이렇게 모델링을 하는 경우, 깔때기 형태와 동일하거나 더 나은 성능을 내는 경우도 있다고 한다.
일반적으로 은닉층의 뉴런 수를 늘리는 것보다 은닉층의 수를 늘리는 쪽이 유리하다.
2.3. 스트레치 팬츠(Stretch pants) 방식
실제 필요한 것보다 은닉층의 수와 뉴런의 수를 크게 하고, 과대 적합이 발생하지 않도록, 조기 종료를 하거나 규제 기법을 사용하는 방법
말 그대로 "자기에게 맞는 바지를 찾는 것이 아닌, 큰 스트레치 팬츠를 사고 나중에 나에 맞게 줄이는 기법"이라 할 수 있다.
해당 방식 사용 시, 모델에서 문제를 일으키는 병목층을 피할 수 있다.
3. 생성된 모델 정보
이전 포스트까지는 단순하게 모델을 생성하고 바로 학습으로 뛰어들었지만, 이번엔 모델의 요약 정보를 보고 진행해보자.
Layer (type)을 보면, 앞서 설정한 Layer의 이름과 어떤 Layer인지가 나온다.
Output shape에서 None은 아직 모르는 값으로, Input 될 데이터의 양을 의미한다.
Input Data는 2-d 배열인 행렬이지만, 1-d 배열로 학습이 진행되므로 shape은 1-d 배열인 것을 알 수 있다.
Param은 각 Layer별 파라미터의 수로, Dense Layer는 Input layer와 Output layer의 모든 노드를 연결하는 완전 연결 계층이기 때문에 연결된 선(Param)이 많다.
Hidden1은 이전 층의 Node가 784개이고, 자신의 Node가 300개이므로, 가중치(Weight)의 엣지가 784*300=235,200개 생성된다. 여기에 편향(Bias)의 엣지가 자신의 Node 수만큼 존재하므로, +300을 하여, 235,500개의 Param이 존재하게 된다.
위 모델 같이 파라미터의 수가 많은 경우, 과대 적합(Overfitting)의 위험이 올라갈 수 있으며, 특히 훈련 데이터의 양이 많지 않은 경우 이 위험이 증가하게 된다.
[참고 서적]
지금까지 모델을 생성하고, 그 정보를 보는 방법에 대해 학습해보았다. 다음 포스팅에서는 모델 컴파일과 학습을 진행해보도록 하겠다.
예를 들어, 수능을 준비하는 고3 학생에게 모의고사 문제가 5개가 있다면, 4개는 공부를 할 때 사용하고, 나머지 1개는 수능 전에 자신이 얼마나 잘 공부를 했는지 평가하는 용도로 사용하는 것이라 생각하면 된다.
최종 목표인 수능(Test set)을 보기 전에 자신의 실력을 평가하는 용도(학습된 파라미터 평가)로 사용되기 때문에 검증 셋을 얼마나 잘 추출하느냐는 꽤 중요한 문제다.
검증 셋은 파라미터 갱신에 영향을 주는 것이 아니라, 학습 과정에서 생성된 여러 모델 중 어느 모델이 가장 좋은지를 평가하는 용도로 사용된다.
검증 셋(Validation set)과 학습 셋(Train set)이 중복되면, 편향이 발생하여, 제대로 된 평가가 이루어지지 않을 수 있다. 이렇게 검증 셋과 학습 셋이 중복된 현상을 Leakage라고 한다.
2. 검증 셋의 효과
검증 셋을 사용한 학습 데이터의 평가는, 학습 과정에서 생긴 여러 모델들이 만들어낸 수많은 파라미터 중 최적의 파라미터를 선택하므로,파라미터를 튜닝하는 효과가 있다고 할 수 있다.
만약 학습 셋(Train set)으로만 학습하고, 시험 셋(Test set)으로만 모델을 검증한다면,모델은 시험 셋(Test set)에 과적합(Overfitting)된 모델이 될 수 있다.
시험 셋(Test set)은 모델의 성능을 평가하기 위해 사용되는 것이긴 하지만, 모델 성능 향상의 기준이 시험 셋이 돼버린다면, 시험 셋의 "모델 성능 평가"라는 목적이 "모델 성능을 맞추는 기준"으로 변질되게 된다. 이 경우, 검증 셋을 사용한다면, 이 문제를 해결할 수 있다.
3. 검증 셋 추출 방법
검증 셋 추출 방법에서 핵심은 "어떻게 검증 셋의 편향을 피하는가"이다.
예를 들어, 총 10개의 시험 단원이 있고, 여기서 랜덤 하게 문제를 뽑아, 수능 시험을 보러 가기 전 최종 평가를 하려고 한다. 그런데, 우연히 1~6단원 문제가 90% 가까이 나왔고, 7~10단원 문제가 10%밖에 나오지 않았다고 가정해보자. 이 시험 문제를 최종 기준으로 사용하는 것은 꼭 피해야 할 문제다.
즉, 최대한 검증 셋의 편향을 없애는 것이 다양한 검증 셋 추출 방법들이 생기게 된 이유라고 할 수 있다.
3.1. Hold-out
단순하게 일정 비율의 데이터 셋을 분리해내는 방법이다.
데이터의 양이 적을수록, 전체 데이터를 대표하지 못할 가능성이 높으며, 편향된 결과를 얻을 가능성이 있다.
3.2. Random subsampling
Hold-out을 완전 무작위 표본 추출로 반복 시행하고, 정확도의 평균으로 성능을 평가한다.
3.3. K-fold cross validation
데이터 셋을 중복되지 않는 K개의 집단으로 나눈다.
K개의 집단에서 1개의 집단을 검증 셋으로 사용하며, K번 검증 셋을 집단이 중복되지 않게 바꿔가며 정확도를 계산하고, 그 평균으로 성능을 평가한다.
데이터 셋이 많으면 많을수록 지나치게 시간을 많이 소모하므로, 빅데이터를 사용하는 현 트렌드에는 맞지 않다.
물론, 데이터의 양이 매우 적다면, 가지고 있는 모든 데이터를 학습과 평가에 사용할 수 있다는 장점이 있다.
3.4. Leave p-out cross validation
중복되지 않은 전체 데이터 n개에서 p개의 샘플을 검증 셋으로 사용하여 정확도를 계산하고, 그 결과의 평균으로 성능을 평가한다.
전체 경우의 수가 ${n}C{p}$개이기 때문에 k-fold cross validation보다 소모되는 시간이 K-fold cross validation보다 많다.
데이터 셋의 양이 매우 적은 경우에나 사용할만하다.
여기서 p=1로 하면Leave one-out cross validation(LOOCV)라 하며, 소모 시간과 성능 모두 Leave p-out cross validation보다 우수하다고 한다.
3.5. Stratified Sampling
전체 데이터 셋을 구성하는 클래스별로 데이터를 일부 추출한다.
전체 데이터셋에서 클래스의 비율이 불균형할수록 편향을 줄여준다는 장점이 있다.
완전 무작위 표본 추출 시, 우연히 특정 클래스에 표본이 편중되는 현상을 피할 수 있다.
Stratified Sampling 역시 k-fold 방식처럼 k개의 집단을 생성하여 그 평균을 낼 수도 있다(Stratified k-fold cross validation).
3.6. Bootstrap
전체 데이터 셋에서 중복을 허용한 샘플링을 반복 실시해, 모집단으로부터 새로운 데이터 셋을 만들어 냄
지난 포스트에서 Tensorflow에서 왜 Keras를 사용하는지와 Keras의 코드 흐름이 어떻게 흘러가는지를 알아보았다. 지금까지의 Tensorflow 과제에서는 진행 과정을 큰 시야에서 보았다면, 이번 포스트부턴 디테일하게 각 부분이 어떻게 흘러가는지를 보도록 하겠다.
MNIST Dataset
LeCun 교수가 만든 MNIST Dataset은 머신러닝 학습에서 가장 기본적으로 사용되는 데이터로, Tensorflow, Pytorch와 같은 수많은 딥러닝 라이브러리의 예제에서 해당 데이터를 다루는 것을 볼 수 있다.
이번 학습에서는 MNIST 데이터에서 가장 대표적인 데이터인 손으로 쓴 숫자를 분류하는 모델을 만들어보도록 하겠다.
# Import Module
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Dense, BatchNormalization, Dropout)
from tensorflow.keras.datasets.mnist import load_data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
이번 포스팅에서는 타이타닉 데이터의 Name 변수에 있는 Mr, Mrs, Ms를 추출해 Class라는 변수를 생성하고, 이를 Label로 사용하여 분류기를 만들어보도록 하겠다.
1. Class 추출.
이전에 만들었던 함수들을 사용해서 쉽게 데이터셋을 만들어보자.
Name 변수의 내용은 다음과 같다.
# Name 데이터의 생김새
>>> Rawdata.Name.head(20)
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
5 Moran, Mr. James
6 McCarthy, Mr. Timothy J
7 Palsson, Master. Gosta Leonard
8 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)
9 Nasser, Mrs. Nicholas (Adele Achem)
10 Sandstrom, Miss. Marguerite Rut
11 Bonnell, Miss. Elizabeth
12 Saundercock, Mr. William Henry
13 Andersson, Mr. Anders Johan
14 Vestrom, Miss. Hulda Amanda Adolfina
15 Hewlett, Mrs. (Mary D Kingcome)
16 Rice, Master. Eugene
17 Williams, Mr. Charles Eugene
18 Vander Planke, Mrs. Julius (Emelia Maria Vande...
19 Masselmani, Mrs. Fatima
Name: Name, dtype: object
데이터를 보면, 처음 등장하는 ", "와 ". " 사이에 해당 인물이 속하는 Class가 나온다.
이를 뽑아내 보자.
# Inport Module
import pandas as pd
import numpy as np
import os
from tensorflow.keras.layers import (Dense, Dropout, BatchNormalization)
from tensorflow import keras
from copy import copy
################################## Function ##################################
def import_Data(file_path):
result = dict()
for file in os.listdir(file_path):
file_name = file[:-4]
result[file_name] = pd.read_csv(file_path + "/" + file)
return result
def make_Rawdata(dict_data):
dict_key = list(dict_data.keys())
test_Dataset = pd.merge(dict_data["gender_submission"], dict_data["test"], how='outer', on="PassengerId")
Rawdata = pd.concat([dict_data["train"], test_Dataset])
Rawdata.reset_index(drop=True, inplace=True)
return Rawdata
##############################################################################
# Rawdata Import
file_path = "./Dataset"
Rawdata_dict = import_Data(file_path)
# Rawdata 생성
Rawdata = make_Rawdata(Rawdata_dict)
# Name에서 Class 추출
Class1 = Rawdata["Name"].str.partition(", ")[2]
Rawdata["Class"] = Class1.str.partition(". ")[0]
판다스의 str 모듈에 있는 partition 함수를 사용하여, 원하는 문자를 가지고 왔다.
Series.str.partition(sep): 함수는 맨 처음 등장하는 sep의 단어로 해당 열의 데이터를 분리하여, 3개의 열을 생성한다.
Class에 어떤 데이터들이 존재하는지 빈도 표를 출력하여 확인해보자.
# Class 데이터 빈도분석 결과
>>> Rawdata.Class.value_counts()
Mr 757
Miss 260
Mrs 197
Master 61
Rev 8
Dr 8
Col 4
Ms 2
Major 2
Mlle 2
Jonkheer 1
Capt 1
Don 1
Sir 1
the Countess 1
Mme 1
Dona 1
Lady 1
Name: Class, dtype: int64
해당 데이터는 Mr, Miss, Mrs뿐만 아니라 95개 데이터가 15개의 분류에 속하는 것을 볼 수 있다.
확실하게 Miss에 속하는 Ms, Mlle, Lady를 하나로, Mrs에 속하는 것이 확실한 the Countess, Dona, Jonkheer, Mme를 하나로 묶고, Mr를 제외한 나머지는 버리도록 하자.
이전 포스트에서 R의 기본 함수를 사용해 결측 값을 다뤄보았다. 이번에는 결측 값 문제를 해결하는데 특화된 패키지인 naniar, VIM 패키지를 사용해서 결측 값을 보다 체계적으로 다뤄보도록 하자.
외부 패키지를 이용해서 결측 값을 다뤄보자.
R 기본 함수만으로도 결측 값을 파악하는데 큰 지장이 없긴 하지만, 결측 값을 위해 특화된 패키지들을 이용해서, 보다 단순하게 결측 값을 파악할 수도 있다.
사용할 패키지들을 설치하고, library 하여 분석 준비를 해보자.
학습에 사용할 데이터는 mlbench 패키지에 있는 BostonHousing 데이터와 moonBook 패키지의 acs 데이터다
mlbench 패키지의 BostonHousing: 다양한 기계 학습 벤치마킹을 위한 데이터가 있는 패키지로, BostonHousing은 보스턴의 주택 가격에 대한 데이터다.
moonBook 패키지의 acs: 의료 데이터가 주로 들어 있으며, acs는 환자의 데이터로, 요골동맥의 혈관 내 초음파 데이터인 radial 등이 있다.
# naniar 패키지 설치
>>> install.packages("naniar")
>>> install.packages("VIM")
# 학습용 데이터가 담긴 Packge
>>> install.packages("mlbench")
>>> install.packages("moonBook")
# 사용할 패키지 library
>>> library("naniar")
>>> library("VIM")
>>> library("moonBook")
>>> library("mlbench")
# 데이터 생성
>>> data("BostonHousing")
>>> data("acs")
# 원본 유지를 위해 사용할 변수에 Data를 담아놓음.
>>> Boston_df = BostonHousing
>>> acs_df = acs
1. naniar 패키지의 결측 값 기술 통계량
naniar 패키지를 사용하면, 결측 값의 기술 통계량을 보다 편하게 구할 수 있다.
대상 데이터에 임의로 결측 값을 부여해보자.
# sample 함수를 사용하여 ptratio, rad 변수의 임의의 위치에 결측값을 생성하였다.
Boston_df[sample(1:nrow(Boston_df), 30, replace = FALSE), "ptratio"] <- NA
Boston_df[sample(1:nrow(Boston_df), 50, replace = FALSE), "rad"] <- NA
sample(x, size, replace = FALSE): 데이터의 전체 수만큼의 연속된 벡터(index와 동일한 벡터)에 원하는 크기만큼 sample을 랜덤 하게 추출했다. replace = FALSE로 두어 비 복원 추출을 실시했다.
# 0.대상 데이터 안에 결측값이 존재하는지 확인
>>> any_na(Boston_df)
[1] TRUE
>>> any_na(Boston_df$zn)
[1] FALSE
>>> any_na(Boston_df$ptratio)
[1] TRUE
# 1.대상 데이터의 결측값에 대한 Boolean값 반환
>>> are_na(Boston_df[1:30,"ptratio"])
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE
[14] FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
[27] FALSE FALSE FALSE FALSE
# 2.대상 데이터 안에 결측값의 갯수 반환
>>> n_miss(Boston_df)
[1] 80
>>> n_miss(Boston_df$ptratio)
[1] 30
# 3.대상 데이터 안에 결측값의 비율 반환
>>> prop_miss(Boston_df)
[1] 0.01129305
>>> prop_miss(Boston_df$ptratio)
[1] 0.05928854
# 4.대상 데이터에서 결측값이 아닌 값의 수
>>> n_complete(Boston_df)
[1] 7004
>>> n_complete(Boston_df$ptratio)
[1] 476
# 5. 데이터 프레임 내 결측값의 빈도표 출력
>>> miss_var_summary(Boston_df)
# A tibble: 14 x 3
variable n_miss pct_miss
<chr> <int> <dbl>
1 rad 50 9.88
2 ptratio 30 5.93
3 crim 0 0
4 zn 0 0
5 indus 0 0
6 chas 0 0
7 nox 0 0
8 rm 0 0
9 age 0 0
10 dis 0 0
11 tax 0 0
12 b 0 0
13 lstat 0 0
14 medv 0 0
# 6. 데이터 프레임 내 결측값의 누적 빈도 출력
>>> miss_var_cumsum(Boston_df)
# A tibble: 14 x 3
variable n_miss n_miss_cumsum
<chr> <int> <int>
1 crim 0 0
2 zn 0 0
3 indus 0 0
4 chas 0 0
5 nox 0 0
6 rm 0 0
7 age 0 0
8 dis 0 0
9 rad 50 50
10 tax 0 50
11 ptratio 30 80
12 b 0 80
13 lstat 0 80
14 medv 0 80
any_na(x): 데이터에 결측 값이 존재하는지 Boolean으로 출력
are_na(x): 데이터 내 결측 값은 TRUE로 결측 값이 아닌 값은 FALSE로 출력
prop_miss(x): 데이터 내 결측 값의 비율
n_complete(x): 데이터 내 결측 값이 아닌 데이터의 수
miss_var_summary(x): 데이터 프레임의 결측 값 빈도표 출력
miss_var_sumsum(x): 데이터 프레임의 결측 값 누적 빈도 표 출력
2. 중복 결측 값 보기
각 변수 당, 결측 값의 양이 적다할지라도, 한 데이터 셋 안에 있는 결측 값의 양은 굉장히 많을 수 있다.
만약 한 모델 안에 m개(m≥2)의 변수가 들어가는 경우, 그 모델은 m개 변수의 결측 값을 모두 가정하지 않으면, 잘못된 결과를 도출할 위험이 있다.
때문에 원하는 변수에서 결측 값이 몇 개나 중복되는지를 알아야 한다.
결측 값의 중복량 파악은 Boolean을 이용하면 쉽게 할 수 있다.
# DataFrame 상태에서 apply, Boolean, sum의 성질을 이용
>>> table(apply(is.na.data.frame(Boston_df), MARGIN = 1, sum))
0 1 2
431 70 5
# Matrix로 변환하여 행의 합인 rowSums() 사용.
>>> table(rowSums(as.matrix(is.na.data.frame(Boston_df))))
0 1 2
431 70 5
위 방법을 통해 쉽게 중복된 결측 값의 수를 알 수 있고, 그로 인해 최대로 제거될 변수의 수를 알 수 있다.
그러나, 어떤 변수들에서 결측 값이 중복되는지를 파악하긴 어렵다.
때문에 결측 값 시각화를 통해, 변수별 결측 값의 분포를 볼 필요가 있다.
3. 간단한 결측값 시각화
데이터의 크기가 크고, 결측 값의 양이 많다면, 결측 값의 분포를 파악하기 힘들다.
시각화를 통해 결측 값 데이터가 어떻게 생겼는지 본다면, 어떠한 데이터들에 결측 값이 모여있는지를 보기 쉽고, 그로 인해 결측 값을 감안한 표본 축소나
moonBook의 acs 데이터는 본래 결측 값이 존재하는 데이터이므로, 이 데이터를 사용하여, 결측 값 분포를 보도록 하자.
naniar 패키지 설치 시, 함께 설치되는 패키지인 visdat에는 vis_miss()라는 결측 값 시각화 함수가 있다.
# 시각화
vis_miss(acs_df)
vis_miss(x) 함수를 이용하면, 쉽게 데이터 안에 결측 값이 어떻게 분포해있는지 알 수 있다.
그러나, 결측 값이 있는 행이 흩어진 상태로 나오므로, 보기 조금 어려울 수 있다.
# 시각화
vis_miss(acs_df, cluster = TRUE)
vis_miss(x, cluster = TRUE): cluster 파라미터를 TRUE로 잡으면, 공통된 결측 값이 있는 행들을 Cluster로 잡아주므로, 더 쉽게 데이터를 파악할 수 있다.
4. VIM 패키지를 사용한 결측 값 시각화
vis_miss()는 코드가 매우 쉽지만, 기능이 많지 않다는 단점이 있다.
만약, 데이터의 결측 값을 보다 심도 깊게 보고자 한다면, VIM 패키지를 사용하면 된다.
VIM은 Visualization and Imputation of Missing Values의 약자로, 말 그대로 결측 값의 시각화와 결측값 대체에 특화된 패키지라고 할 수 있다.
4.1. 중복된 결측 값의 분포
# VIM을 사용한 시각화
aggr(acs, col=c("white", "red"), prop=FALSE, number=TRUE, sortVars = TRUE,
cex.axis=.8, gap=1, ylab=c("Histogram of NA", "Pattern"))
기능이 보다 많다 보니, 파라미터가 많은데, 그 내용은 다음과 같다.
col = c("white", "red"): 결측 값이 없는 셀, 있는 셀의 색깔
prop = FALSE: 비율로 출력할지(TRUE), 빈도로 출력할지(FALSE)
number = TRUE: 결측 값의 개수를 숫자로 출력할지 여부
sortVars = TRUE: 결측 값의 개수로 정렬함
cex.axis = .8: 글자 크기
gap = 1, 두 그래프의 간격
ylab = c("title1", "title2"): 그래프의 이름
위 그래프에서 좌측 그래프는 단순한 히스토그램이니 설명은 생략하도록 하겠다.
우측 그래프는 공통된 결측 값의 빈도를 나타낸다. 예를 들어 EF, height, BMI, weight은 공통 결측 값을 47개 가지고 있다.
지금까지 외부 라이브러리를 사용하여, 결측 값을 보다 효과적으로 파악하는 방법을 알아보았다. 다음 포스트에서는 결측 값을 채워 넣는 방법인 Single Imputation에 대해 알아보도록 하겠다.
파이썬을 처음 사용하는 데이터 분석가가 제일 먼저 공부해야 할 라이브러리를 한 가지 꼽으라면, 많은 사람들이 판다스(Pandas)를 선택할 것이다.
판다스는 R과 마찬가지로 데이터 프레임(DataFrame)을 사용해서, 데이터를 시각화, 분석을 할 수 있는데, R의 데이터 프레임이 그렇듯 매우 직관적이고, 데이터를 가지고 놀기 좋은 R의 기능을 대부분 사용할 수 있기 때문에 데이터 분석가에게 있어 필수 라이브러리라고 할 수 있다.
사족으로 판다스라고 하면, 동물인 판다가 먼저 떠오를 텐데, 판다스는 동물에서 따온 이름이 아닌, 계량 경제학에서 사용하는 "패널 데이터(Panner Data)"에서 따온 이름이다.
사회 과학에서 자주 다뤄지는 패널 데이터를 간략히 설명하자면, 횡단 데이터인 한 시점에서의 데이터 셋이 종단 데이터로 규칙적인 기간을 간격으로 여러 개 존재하는 데이터를 말한다. 즉, 종단 + 횡단의 성격을 갖는 데이터가 패널 데이터다. 이는 판다스가 한 시점에서 뿐만이 아닌 시계열 데이터에도 강한 면모를 가진다는 뜻이기도 하다.
판다스는 대용량 데이터를 다룰 때나, 서비스를 위해 0.5초, 1초 내의 빠른 연산이 필요한 상황에선 취약한 모습을 보이기 때문에 만능이라고 할 수는 없으나, 판다스는 데이터의 흐름이나 데이터의 특징 파악이 매우 쉬우므로, 먼저 판다스로 코드를 짜고, 속도가 매우 빠른 Numpy로 코드를 수정하면, 이를 쉽게 해결할 수 있다.
1. 판다스의 데이터 타입
판다스는 크게 2개의 고유 데이터 타입을 가지고 있다.
하나는 데이터 프레임(DataFrame)이고, 다른 하나는 시리즈(Series)이다.
어떻게 생겼는지만 간략히 봐보자.
import pandas as pd
from sklearn.datasets import load_iris
# 붓꽃(iris) 데이터를 가져와보자.
iris_dict = load_iris()
DF = pd.DataFrame(iris_dict["data"], columns=iris_dict["feature_names"])
DF
이전 포스트에서 원-핫 벡터를 사용한, 데이터 셋을 만들었으나, 그 성능이 생각보다 크지 않았다.
데이터 셋의 상태는 실제로 더 좋아졌으나, 적절한 하이퍼 파라미터나, 적합한 모델을 만들지 못해서 발생한 문제일 수 있다.
이번엔 하이퍼 파라미터를 하나하나 잡아보도록 하자.
0. 학습 이전까지 코드 정리
# Import Module
import pandas as pd
import numpy as np
import os
from tensorflow.keras.layers import Dense
from tensorflow import keras
from copy import copy
# 필요한 Data를 모두 가져온다.
def import_Data(file_path):
result = dict()
for file in os.listdir(file_path):
file_name = file[:-4]
result[file_name] = pd.read_csv(file_path + "/" + file)
return result
# Rawdata 생성
def make_Rawdata(dict_data):
dict_key = list(dict_data.keys())
test_Dataset = pd.merge(dict_data["gender_submission"], dict_data["test"], how='outer', on="PassengerId")
Rawdata = pd.concat([dict_data["train"], test_Dataset])
Rawdata.reset_index(drop=True, inplace=True)
return Rawdata
# 불필요한 컬럼 제거
def remove_columns(DF, remove_list):
# 원본 정보 유지를 위해 copy하여, 원본 Data와의 종속성을 끊었다.
result = copy(Rawdata)
# PassengerId를 Index로 하자.
result.set_index("PassengerId", inplace = True)
# 불필요한 column 제거
for column in remove_list:
del(result[column])
return result
# 결측값 처리
def missing_value(DF):
# Cabin 변수를 제거하자
del(DF["Cabin"])
# 결측값이 있는 모든 행은 제거한다.
DF.dropna(inplace = True)
# 원-핫 벡터
def one_hot_Encoding(data, column):
# 한 변수 내 빈도
freq = data[column].value_counts()
# 빈도가 큰 순서로 용어 사전 생성
vocabulary = freq.sort_values(ascending = False).index
# DataFrame에 용어 사전 크기의 column 생성
for word in vocabulary:
new_column = column + "_" + str(word)
data[new_column] = 0
# 생성된 column에 해당하는 row에 1을 넣음
for word in vocabulary:
target_index = data[data[column] == word].index
new_column = column + "_" + str(word)
data.loc[target_index, new_column] = 1
# 기존 컬럼 제거
del(data[column])
# 스케일 조정
def scale_adjust(X_test, X_train, C_number, key="min_max"):
if key == "min_max":
min_key = np.min(X_train[:,C_number])
max_key = np.max(X_train[:,C_number])
X_train[:,C_number] = (X_train[:,C_number] - min_key)/(max_key - min_key)
X_test[:,C_number] = (X_test[:,C_number] - min_key)/(max_key - min_key)
elif key =="norm":
mean_key = np.mean(X_train[:,C_number])
std_key = np.std(X_train[:,C_number])
X_train[:,C_number] = (X_train[:,C_number] - mean_key)/std_key
X_test[:,C_number] = (X_test[:,C_number] - mean_key)/std_key
return X_test, X_train
# Data Handling
############ Global Parameter ############
file_path = "./Dataset"
remove_list = ["Name", "Ticket"]
##########################################
# 0. Rawdata 생성
Rawdata_dict = import_Data(file_path)
Rawdata = make_Rawdata(Rawdata_dict)
# 1. 필요 없는 column 제거
DF_Hand = remove_columns(Rawdata, remove_list)
# 2. 결측값 처리
missing_value(DF_Hand)
# 3. One-Hot encoding
one_hot_Encoding(DF_Hand, 'Pclass')
one_hot_Encoding(DF_Hand, 'Sex')
one_hot_Encoding(DF_Hand, 'Embarked')
# 4. 데이터 쪼개기
# Label 생성
y_test, y_train = DF_Hand["Survived"][:300].to_numpy(), DF_Hand["Survived"][300:].to_numpy()
# 5. Dataset 생성
del(DF_Hand["Survived"])
X_test, X_train = DF_Hand[:300].values, DF_Hand[300:].values
# 6. 특성 스케일 조정
X_test, X_train = scale_adjust(X_test, X_train, 0, key="min_max")
X_test, X_train = scale_adjust(X_test, X_train, 3, key="min_max")
# 모델 생성
model = keras.Sequential()
model.add(Dense(128, activation = "relu"))
model.add(Dense(64, activation = "relu"))
model.add(Dense(32, activation = "relu"))
model.add(Dense(16, activation = "relu"))
model.add(Dense(1, activation = "sigmoid"))
# 모델 Compile
opt = keras.optimizers.Adam(learning_rate=0.005)
model.compile(optimizer=opt,
loss = "binary_crossentropy",
metrics=["binary_accuracy"])
1. 적절한 Epochs 잡기
혹시 과적합(Overfitting)이 발생한 것일지도 모르니 손실 값의 추이를 보자.
모델은 적합한 epochs를 넘어 학습하게 된다면, train Dataset에 지나치게 맞춰져서, Test set을 제대로 분류하지 못하는 문제가 발생할 수 있다.
용어 사전의 크기가 크면 클수록 벡터의 크기가 커지므로, 벡터 저장을 위한 필요 공간이 커진다.
즉, 단어가 1,000개라면, 단어 1,000개 모두 벡터의 크기가 1,000이므로, 입력될 텐서가 지나치게 커진다.
단어를 단순하게 숫자로 바꾸고 해당 인덱스를 1로 나머지를 0으로 만든 것이므로, 의미, 단어 간 유사도를 표현하지 못한다.
3. 문자형 변수를 One-Hot 벡터로 치환해보자.
원-핫 벡터 생성은 그 알고리즘이 상당히 단순하므로, 직접 구현해보도록 하겠다.
생성될 원-핫 벡터는 대상 변수의 구성 원소의 빈도를 감안하여 생성하도록 하겠다.
DataFrame을 기반으로 작업하였으므로, DataFrame의 성질을 이용해보자.
def one_hot_Encoding(data, column):
# 한 변수 내 빈도
freq = data[column].value_counts()
# 빈도가 큰 순서로 용어 사전 생성
vocabulary = freq.sort_values(ascending = False).index
# DataFrame에 용어 사전 크기의 column 생성
for word in vocabulary:
new_column = column + "_" + str(word)
data[new_column] = 0
# 생성된 column에 해당하는 row에 1을 넣음
for word in vocabulary:
target_index = data[data[column] == word].index
new_column = column + "_" + str(word)
data.loc[target_index, new_column] = 1
# 기존 컬럼 제거
del(data[column])