이번 포스팅에서는 타이타닉 데이터의 Name 변수에 있는 Mr, Mrs, Ms를 추출해 Class라는 변수를 생성하고, 이를 Label로 사용하여 분류기를 만들어보도록 하겠다.
1. Class 추출.
이전에 만들었던 함수들을 사용해서 쉽게 데이터셋을 만들어보자.
Name 변수의 내용은 다음과 같다.
# Name 데이터의 생김새
>>> Rawdata.Name.head(20)
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
5 Moran, Mr. James
6 McCarthy, Mr. Timothy J
7 Palsson, Master. Gosta Leonard
8 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)
9 Nasser, Mrs. Nicholas (Adele Achem)
10 Sandstrom, Miss. Marguerite Rut
11 Bonnell, Miss. Elizabeth
12 Saundercock, Mr. William Henry
13 Andersson, Mr. Anders Johan
14 Vestrom, Miss. Hulda Amanda Adolfina
15 Hewlett, Mrs. (Mary D Kingcome)
16 Rice, Master. Eugene
17 Williams, Mr. Charles Eugene
18 Vander Planke, Mrs. Julius (Emelia Maria Vande...
19 Masselmani, Mrs. Fatima
Name: Name, dtype: object
데이터를 보면, 처음 등장하는 ", "와 ". " 사이에 해당 인물이 속하는 Class가 나온다.
이를 뽑아내 보자.
# Inport Module
import pandas as pd
import numpy as np
import os
from tensorflow.keras.layers import (Dense, Dropout, BatchNormalization)
from tensorflow import keras
from copy import copy
################################## Function ##################################
def import_Data(file_path):
result = dict()
for file in os.listdir(file_path):
file_name = file[:-4]
result[file_name] = pd.read_csv(file_path + "/" + file)
return result
def make_Rawdata(dict_data):
dict_key = list(dict_data.keys())
test_Dataset = pd.merge(dict_data["gender_submission"], dict_data["test"], how='outer', on="PassengerId")
Rawdata = pd.concat([dict_data["train"], test_Dataset])
Rawdata.reset_index(drop=True, inplace=True)
return Rawdata
##############################################################################
# Rawdata Import
file_path = "./Dataset"
Rawdata_dict = import_Data(file_path)
# Rawdata 생성
Rawdata = make_Rawdata(Rawdata_dict)
# Name에서 Class 추출
Class1 = Rawdata["Name"].str.partition(", ")[2]
Rawdata["Class"] = Class1.str.partition(". ")[0]
판다스의 str 모듈에 있는 partition 함수를 사용하여, 원하는 문자를 가지고 왔다.
Series.str.partition(sep): 함수는 맨 처음 등장하는 sep의 단어로 해당 열의 데이터를 분리하여, 3개의 열을 생성한다.
Class에 어떤 데이터들이 존재하는지 빈도 표를 출력하여 확인해보자.
# Class 데이터 빈도분석 결과
>>> Rawdata.Class.value_counts()
Mr 757
Miss 260
Mrs 197
Master 61
Rev 8
Dr 8
Col 4
Ms 2
Major 2
Mlle 2
Jonkheer 1
Capt 1
Don 1
Sir 1
the Countess 1
Mme 1
Dona 1
Lady 1
Name: Class, dtype: int64
해당 데이터는 Mr, Miss, Mrs뿐만 아니라 95개 데이터가 15개의 분류에 속하는 것을 볼 수 있다.
확실하게 Miss에 속하는 Ms, Mlle, Lady를 하나로, Mrs에 속하는 것이 확실한 the Countess, Dona, Jonkheer, Mme를 하나로 묶고, Mr를 제외한 나머지는 버리도록 하자.
이전 포스트에서 원-핫 벡터를 사용한, 데이터 셋을 만들었으나, 그 성능이 생각보다 크지 않았다.
데이터 셋의 상태는 실제로 더 좋아졌으나, 적절한 하이퍼 파라미터나, 적합한 모델을 만들지 못해서 발생한 문제일 수 있다.
이번엔 하이퍼 파라미터를 하나하나 잡아보도록 하자.
0. 학습 이전까지 코드 정리
# Import Module
import pandas as pd
import numpy as np
import os
from tensorflow.keras.layers import Dense
from tensorflow import keras
from copy import copy
# 필요한 Data를 모두 가져온다.
def import_Data(file_path):
result = dict()
for file in os.listdir(file_path):
file_name = file[:-4]
result[file_name] = pd.read_csv(file_path + "/" + file)
return result
# Rawdata 생성
def make_Rawdata(dict_data):
dict_key = list(dict_data.keys())
test_Dataset = pd.merge(dict_data["gender_submission"], dict_data["test"], how='outer', on="PassengerId")
Rawdata = pd.concat([dict_data["train"], test_Dataset])
Rawdata.reset_index(drop=True, inplace=True)
return Rawdata
# 불필요한 컬럼 제거
def remove_columns(DF, remove_list):
# 원본 정보 유지를 위해 copy하여, 원본 Data와의 종속성을 끊었다.
result = copy(Rawdata)
# PassengerId를 Index로 하자.
result.set_index("PassengerId", inplace = True)
# 불필요한 column 제거
for column in remove_list:
del(result[column])
return result
# 결측값 처리
def missing_value(DF):
# Cabin 변수를 제거하자
del(DF["Cabin"])
# 결측값이 있는 모든 행은 제거한다.
DF.dropna(inplace = True)
# 원-핫 벡터
def one_hot_Encoding(data, column):
# 한 변수 내 빈도
freq = data[column].value_counts()
# 빈도가 큰 순서로 용어 사전 생성
vocabulary = freq.sort_values(ascending = False).index
# DataFrame에 용어 사전 크기의 column 생성
for word in vocabulary:
new_column = column + "_" + str(word)
data[new_column] = 0
# 생성된 column에 해당하는 row에 1을 넣음
for word in vocabulary:
target_index = data[data[column] == word].index
new_column = column + "_" + str(word)
data.loc[target_index, new_column] = 1
# 기존 컬럼 제거
del(data[column])
# 스케일 조정
def scale_adjust(X_test, X_train, C_number, key="min_max"):
if key == "min_max":
min_key = np.min(X_train[:,C_number])
max_key = np.max(X_train[:,C_number])
X_train[:,C_number] = (X_train[:,C_number] - min_key)/(max_key - min_key)
X_test[:,C_number] = (X_test[:,C_number] - min_key)/(max_key - min_key)
elif key =="norm":
mean_key = np.mean(X_train[:,C_number])
std_key = np.std(X_train[:,C_number])
X_train[:,C_number] = (X_train[:,C_number] - mean_key)/std_key
X_test[:,C_number] = (X_test[:,C_number] - mean_key)/std_key
return X_test, X_train
# Data Handling
############ Global Parameter ############
file_path = "./Dataset"
remove_list = ["Name", "Ticket"]
##########################################
# 0. Rawdata 생성
Rawdata_dict = import_Data(file_path)
Rawdata = make_Rawdata(Rawdata_dict)
# 1. 필요 없는 column 제거
DF_Hand = remove_columns(Rawdata, remove_list)
# 2. 결측값 처리
missing_value(DF_Hand)
# 3. One-Hot encoding
one_hot_Encoding(DF_Hand, 'Pclass')
one_hot_Encoding(DF_Hand, 'Sex')
one_hot_Encoding(DF_Hand, 'Embarked')
# 4. 데이터 쪼개기
# Label 생성
y_test, y_train = DF_Hand["Survived"][:300].to_numpy(), DF_Hand["Survived"][300:].to_numpy()
# 5. Dataset 생성
del(DF_Hand["Survived"])
X_test, X_train = DF_Hand[:300].values, DF_Hand[300:].values
# 6. 특성 스케일 조정
X_test, X_train = scale_adjust(X_test, X_train, 0, key="min_max")
X_test, X_train = scale_adjust(X_test, X_train, 3, key="min_max")
# 모델 생성
model = keras.Sequential()
model.add(Dense(128, activation = "relu"))
model.add(Dense(64, activation = "relu"))
model.add(Dense(32, activation = "relu"))
model.add(Dense(16, activation = "relu"))
model.add(Dense(1, activation = "sigmoid"))
# 모델 Compile
opt = keras.optimizers.Adam(learning_rate=0.005)
model.compile(optimizer=opt,
loss = "binary_crossentropy",
metrics=["binary_accuracy"])
1. 적절한 Epochs 잡기
혹시 과적합(Overfitting)이 발생한 것일지도 모르니 손실 값의 추이를 보자.
모델은 적합한 epochs를 넘어 학습하게 된다면, train Dataset에 지나치게 맞춰져서, Test set을 제대로 분류하지 못하는 문제가 발생할 수 있다.
용어 사전의 크기가 크면 클수록 벡터의 크기가 커지므로, 벡터 저장을 위한 필요 공간이 커진다.
즉, 단어가 1,000개라면, 단어 1,000개 모두 벡터의 크기가 1,000이므로, 입력될 텐서가 지나치게 커진다.
단어를 단순하게 숫자로 바꾸고 해당 인덱스를 1로 나머지를 0으로 만든 것이므로, 의미, 단어 간 유사도를 표현하지 못한다.
3. 문자형 변수를 One-Hot 벡터로 치환해보자.
원-핫 벡터 생성은 그 알고리즘이 상당히 단순하므로, 직접 구현해보도록 하겠다.
생성될 원-핫 벡터는 대상 변수의 구성 원소의 빈도를 감안하여 생성하도록 하겠다.
DataFrame을 기반으로 작업하였으므로, DataFrame의 성질을 이용해보자.
def one_hot_Encoding(data, column):
# 한 변수 내 빈도
freq = data[column].value_counts()
# 빈도가 큰 순서로 용어 사전 생성
vocabulary = freq.sort_values(ascending = False).index
# DataFrame에 용어 사전 크기의 column 생성
for word in vocabulary:
new_column = column + "_" + str(word)
data[new_column] = 0
# 생성된 column에 해당하는 row에 1을 넣음
for word in vocabulary:
target_index = data[data[column] == word].index
new_column = column + "_" + str(word)
data.loc[target_index, new_column] = 1
# 기존 컬럼 제거
del(data[column])
이전 포스트에서 타이타닉 데이터가 어떻게 구성되어 있는지 확인해보았다. 이번 포스트에서는 타이타닉 데이터를 전처리해보고, 생존자 분류 모델을 만들어보자.
타이타닉 데이터 생존자 분류 모델 만들기
모든 데이터 분석에서도 그렇듯 딥 러닝 모델 생성에서도 제일 우선 되는 것은 데이터 전처리다.
머신러닝 모델을 만들 때의 순서는 다음과 같다.
데이터 셋의 특징을 잘 나타낼 수 있게 전처리를 한다(Data Handling).
학습이 제대로 되도록 데이터 셋을 잘 쪼갠다(Train, Validation, Test).
목적과 데이터에 맞는 모델을 생성한다.
학습 후, 모델의 성능을 평가하고, 성능을 업그레이드한다.
이번엔 각 영역이 미치는 영향이 얼마나 큰지를 시각적으로 보도록 하겠다.
0. 데이터 불러오기
이전 포스트에서 만들었던 데이터를 가져오는 코드를 정리해보자.
# Import Module
import pandas as pd
import numpy as np
import os
from tensorflow.keras.layers import Dense
from tensorflow import keras
# 모든 Data를 DataFrame의 형태로 dictionary에 넣어 가지고 온다.
def import_Data(file_path):
result = dict()
for file in os.listdir(file_path):
file_name = file[:-4]
result[file_name] = pd.read_csv(file_path + "/" + file)
return result
# 해당 경로에 있는 모든 파일을 DataFrame으로 가지고 왔다.
file_path = "./Dataset"
Rawdata_dict = import_Data(file_path)
1. 데이터 전처리
이전 포스트에서 파악한 데이터 셋의 내용을 기반으로, 데이터 셋을 전처리해보자.
1.1. 데이터 셋 전처리가 쉽도록 한 덩어리로 만들자.
# 흩어져 있는 데이터를 모아 하나의 Rawdata로 만든다.
def make_Rawdata(dict_data):
dict_key = list(dict_data.keys())
test_Dataset = pd.merge(dict_data["gender_submission"], dict_data["test"], how='outer', on="PassengerId")
Rawdata = pd.concat([dict_data["train"], test_Dataset])
Rawdata.reset_index(drop=True, inplace=True)
return Rawdata
pd.merge(): 두 DataFrame을 동일한 Column을 기준(열 기준)으로 하나로 합친다.
pd.concat(): 모든 Column이 동일한 두 DataFrame을 행 기준으로 하나로 합친다.
DataFrame.reset_index(): DataFrame의 index를 초기화한다.
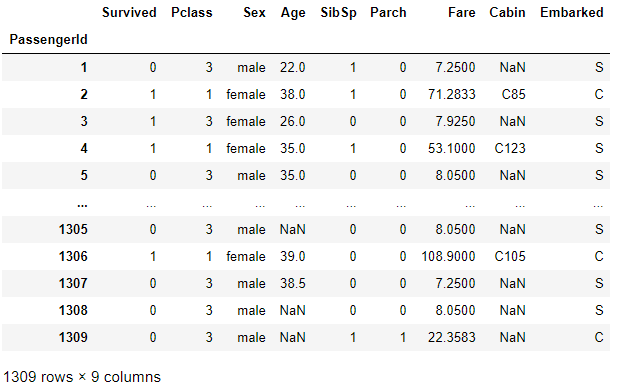
Rawdata = make_Rawdata(Rawdata_dict)
Rawdata
1.2. 불필요한 Column을 제거하자.
생존 여부에 절대 영향을 줄 수 없는 Column을 제거하여, Feature가 두드러지도록 만들자.
고객의 ID(PassengerId), 고객의 이름(Name), 티켓 번호(Tiket)는 생존 여부에 영향을 줄 가능성이 거의 없다고 판단된다. 그러므로, Dataset에서 제거하자.
from copy import copy
def remove_columns(DF, remove_list):
# 원본 정보 유지를 위해 copy하여, 원본 Data와의 종속성을 끊었다.
result = copy(Rawdata)
# PassengerId를 Index로 하자.
result.set_index("PassengerId", inplace = True)
# 불필요한 column 제거
for column in remove_list:
del(result[column])
return result
copy(Data): Data를 복사하여, 데이터의 종속성이 없는 데이터를 만들어낸다.
DataFrame.set_index(): 특정 column을 Index로 설정한다.
del(DataFrame[column]): DataFrame에서 해당 column을 제거한다.
이전 포스트에서 캐글에서 타이타닉 데이터를 다운로드하였다. 이번 포스트에서는 타이타닉 데이터를 파이썬으로 불러오고, 데이터가 어떻게 생겼고, 어떤 변수가 있는지를 확인해보자.
타이타닉 데이터 가져오기
이전에 받았던 타이타닉 데이터가 어떻게 생겼는지 보고, 변수들을 파악해보자.
1. 작업 파일 이동시키기
만약, 작성자와 같은 주피터 노트북 사용자라면, 아래와 같이 작업 파일과 같은 경로 안에 Data를 넣는 폴더를 만들어, 데이터를 넣어놓자.
현재 작업 중인 주피터 노트북 파일인 Report04_210209.ipynb와 같은 경로에 Dataset이라는 파일을 새로 만들었다.
이전에 다운로드하였던 titanic 압축파일 안에 있던 3 파일 "gender_submission.csv", "test.csv", "train.csv"을 Upload 시키자.
2. 데이터 불러오기
import pandas as pd
import numpy as np
import os
# Global Variable
file_path = "./Dataset"
# Function
def import_Data(file_path):
result = dict()
for file in os.listdir(file_path):
file_name = file[:-4]
result[file_name] = pd.read_csv(file_path + "/" + file)
return result
Rawdata_dict = import_Data(file_path)
os.listdir(디렉터리): 있는 파일 list를 가지고 온다.
pd.read_csv(파일 경로): 있는 csv파일을 가지고 온다.
데이터를 이름으로 하나하나 불러오지 않고, 특정 디렉터리 안에 있는 모든 파일들을 해당 파일의 이름으로 딕셔너리에 넣어 가지고 왔다.
이렇게 데이터 프레임을 딕셔너리로 관리하는 경우, 특정 목적에 맞는 데이터들을 보다 쉽게 관리할 수 있으며, 데이터의 이름을 특정 패턴을 가진 상태로 부여할 수 있다.
또한, 한 번에 특정 디렉터리 내 모든 파일들을 모두 가져올 수 있으므로, 데이터를 가지고 올 때도 꽤 편하다.
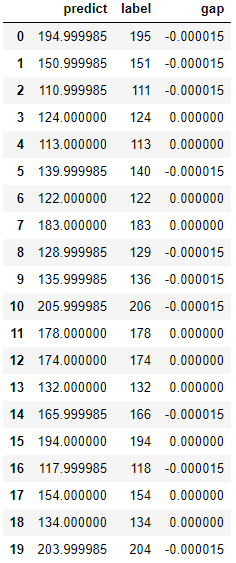
패턴을 거의 완벽하게 찾아내었으며, 정확도(Accuracy) 역시 0.000010789(e-05는 $10^{-5}$을 하라는 소리다.)로 거의 0에 근사하게 나왔다.
2. 정리
위 결과를 보면, 아무리 단순한 패턴이라 할지라도, 그 데이터 셋의 형태를 반영하지 못한다면, 정확히 그 결과를 찾아내지 못할 수 있다는 것을 알 수 있다.
인공지능은 흔히들 생각하는 빅데이터를 넣으면, 그 안에 숨어 있는 패턴이 자동으로 나오는 마법의 상자가 아니라, 연구자가 그 데이터에 대한 이해를 가지고 여러 시도를 해, 제대로 된 설계를 해야만 내가 원하는 제대로 된 패턴을 찾아낼 수 있는 도구다.
그러나, 실전에서는 지금처럼 우리가 이미 패턴을 알고 있는 경우는 없기 때문에 다양한 도구를 이용해서, 데이터를 파악하고, 적절한 하이퍼 파라미터를 찾아낸다.
넣을 수 있는 모든 하이퍼 파라미터를 다 넣어보는 "그리드 서치(Greed search)"나 랜덤 한 값을 넣어보고 지정한 횟수만큼 평가하는 "랜덤 서치(Random Search)", 순차적으로 값을 넣어보고, 더 좋은 해들의 조합에 대해서 찾아가는 "베이지안 옵티마이제이션(Bayesian Optimization)" 등 다양한 방법이 있다.
같은 알고리즘이라 할지라도, 데이터를 어떻게 전처리하느냐, 어떤 활성화 함수를 쓰느냐, 손실 함수를 무엇을 쓰느냐 등과 같은 다양한 요인으로 인해 다른 결과가 나올 수 있으므로, 경험을 많이 쌓아보자.
이전 포스트에서 만든 모델의 결과는 그리 나쁘진 않았으나, 패턴이 아주 단순함에도 쉽게 결과를 찾아내지 못했고, 학습에 자원 낭비도 많이 되었다.
왜 그럴까?
특성 스케일 조정
특성 스케일 조정을 보다 쉽게 말해보면, 표준화라고 할 수 있다.
이번에 학습한 대상은 변수(다른 정보에 대한 벡터 성분)가 1개밖에 없어서 그나마 나았으나, 만약, 키와 몸무게가 변수로 주어져 벡터의 원소로 들어갔다고 생각해보자.
키나 몸무게는 그 자리 수가 너무 큰 값이다 보니, 파라미터 역시 그 값의 변화가 지나치게 커지게 되고, 그로 인해 제대로 된 결과를 찾지 못할 수 있다.
또한 키와 몸무게는 그 단위마저도 크게 다르다 보니, 키에서 160이 몸무게에서의 160과 같다고 볼 수 있다. 그러나 모두가 알다시피 키 160은 대한민국 남녀 성인 키 평균에 못 미치는 값이며, 몸무게 160은 심각한 수준의 비만이다. 전혀 다른 값임에도 이를 같게 볼 위험이 있다는 것이다.
이러한 표준화가 미치는 영향은 손실 함수에서 보다 이해하기 쉽게 볼 수 있는데, 이로 인해 발생하는 문제가 바로 경사 하강법의 zigzag 문제다.
$w_1$과 $w_2$의 스케일 크기가 동일하다면(값의 범위가 동일), 손실 함수가 보다 쉽게 최적해에서 수렴할 수 있다.
$w_1$과 $w_2$의 스케일 크기가 많이 다르다면, 손실 함수는 쉽게 최적해에 수렴하지 못한다.
1. 특성 스케일 조정 방법
특성 스케일 조정 방법은 크게 2가지가 있다.
첫 번째는 특성 스케일 범위 조정이고, 두 번째는 표준 정규화를 하는 것이다.
A. 특성 스케일 범위 조정
특성 스케일 범위 조정은 말 그대로, 값의 범위를 조정하는 것이다.
바꿀 범위는 [0, 1]이다.
이 방법에는 최솟값과 최댓값이 사용되므로 "최소-최대 스케일 변환(min-max scaling)"이라고도 한다.
범위 축소에 흔히들 사용되는 해당 방법은, 가장 쉽게 표준화하는 방법이지만, 값이 지나치게 축소되어 존재하던 이상치가 사라져 버릴 수 있다.
특히나, 이상치가 존재한다면, 이상치보다 작은 값들을 지나치게 좁은 공간에 모아버리게 된다.
B. 표준 정규분포
표준 정규분포는 평균 = 0, 표준편차 = 1로 바꾸는 가장 대표적인 표준화 방법이다.
공식은 다음과 같다.
$$ x_{std} = \frac{x_i - \mu_x}{\sigma_x} $$
위 공식에서 $x_i$는 표준화 대상 array다.
표준 정규분포로 만들게 되면, 평균 = 0, 표준편차 = 1로 값이 축소되게 되지만, 여전히 이상치의 존재가 남아 있기 때문에 개인적으론 표준 정규분포로 만드는 것을 추천한다.
특성 스케일 조정에서 가장 중요한 것은, 조정의 기준이 되는 최솟값, 최댓값, 평균, 표준편차는 Train Dataset의 값이라는 것이다. 해당 방법 사용 시, Train Dataset을 기준으로 하지 않는다면, Test Dataset의 값이 Train Dataset과 같아져 버릴 수 있다.
2. 표준 정규분포를 이용해서 특성 스케일을 조정해보자.
# Import Module
import pandas as pd
import numpy as np
from tensorflow import keras
from tensorflow.keras.layers import Dense
# Dataset Setting
def f(x):
return x + 10
# Data set 생성
np.random.seed(1234) # 동일한 난수가 나오도록 Seed를 고정한다.
X_train = np.random.randint(0, 100, (100, 1))
X_test = np.random.randint(100, 200, (20, 1))
# Label 생성
y_train = f(X_train)
y_test = f(X_test)
# Model Setting
model = keras.Sequential()
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='linear'))
# Compile: 학습 셋팅
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=opt, loss = 'mse')