리눅스 서버에 분석 환경 구축
분석을 하기 위해선 분석을 할 수 있는 환경을 만드는 것이 가장 중요하다. 아무리 수많은 분석 기법들을 알고 있더라도, 스스로 분석 환경을 구축하지 못한다면 아무것도 진행할 수 없기 때문이다.
이전 포스트까지는 일반적으로 사용자가 사용하는 컴퓨터(Local)에 분석 환경을 구축하는 것에 대해 알아보았다. 그러나, 대용량 데이터를 다루는 현장에서는 Local PC로 데이터 분석을 진행하는 것엔 한계가 있기 때문에 분석용 서버에서 분석을 진행하게 된다.
그러나, 대부분의 서버는 보안을 위해 오프라인으로 구축되어 있으며, 우리에게 익숙한 OS인 Windows가 아닌 Ububtu, CentOS와 같은 Linux로 설치되어 있으며, 쓸모없는 자원 낭비를 막기 위해 CLI레벨로 구성되어 있어, 실행 시 그냥 검은 화면만 나온다(우리에게 익숙한 윈도우 화면은 GUI레벨이다).
일반적으로 서버의 환경 설정은 도커(Docker)를 이용하여 구축하지만, 단순히 파이썬(Python) 기반의 분석 환경을 구축하고자 한다면, 앞서 학습했던 아나콘다 가상 환경(Virtual Environment)만 사용해도 충분하다.
이번 포스트에서는 오프라인 우분투(Ubuntu) 서버에 딥러닝 분석 환경을 구축하는 과정을 학습해보도록 하겠다.
1. 준비물과 진행 과정
오프라인 서버 분석 환경 구축과 연습에는 인터넷이 되는 Local PC 하나만 있으면 충분하다. 분석 서버를 단순하게 설명해보면, "성능이 엄청나게 좋지만 인터넷이 안 되는 리눅스 OS가 설치된 컴퓨터"라고 할 수 있다.
앞으로 우리가 진행할 과정을 간단하게 요약해보면 다음과 같다.
- 인터넷이 되는 윈도우 컴퓨터에 분석 서버와 동일한 리눅스 배포 버전 가상 머신 설치
(이번 포스트에서는 Ubuntu 18.04를 대상으로 하겠다.) - 가상 머신에 아나콘다를 설치
- 가상 환경 생성 후, 필요한 패키지 모두 설치 및 이를 압축하여 외부로 내보내기
- 사용하고자 하는 텐서플로우(파이토치) 버전에 맞는 Cuda, Cudnn 다운로드
- 압축된 가상환경, 아나콘다 설치 파일, Cuda, Cudnn을 인터넷이 안되는 리눅스 서버에 이동시키기
(가상 머신을 새로 만들고, 인터넷 선을 뽑은 후 진행하면, 오프라인 우분투 서버가 된다.) - 이동된 파일 모두 설치
꽤 복잡해 보이지만, 익숙하지 않아서 그렇지, 앞서 다뤄봤던 윈도우 환경에서 분석 환경 설정하는 방법과 동일하다.
2. 가상 머신(우분투) 설치하기 - wsl2
가상 머신을 설치하는 방법을 두 가지 소개해보자면, 다음과 같다.
- Virtual Machine 프로그램을 사용하여, 가상 머신 만들기
- wsl2를 사용하여, 가상 머신 만들기
Virtual Machine 프로그램을 사용하면, 내 컴퓨터에 작은 컴퓨터를 만드는 것처럼 진행할 수 있지만, 과정이 꽤 복잡하고, 자원을 분리해서 사용하며, 가상 머신 종료 등의 과정이 꽤 번거롭기 때문에, 이번 포스트에서는 마이크로 소프트의 wsl2를 사용해서 가상 머신을 만들어보도록 하겠다.
2.1. wsl2(Windows Subsystem for Linux 2)
- wsl2는 Linux용 Windows 하위 시스템의 약자로, Virtual Machine보다 쉽게 가상 머신을 만들 수 있다.
- 자원도 따로 나눌 필요가 없으며, 머신 종료 등의 번거로운 과정이 매우 간단한다.
- 윈도우에서 도커(Docker)나 리눅스 개발을 할 수 있다.
2.2. wsl2 설치 및 주의 사항
- wsl2 설치는 마이크로 소프트 공식 홈페이지에서 아주 쉽게 설명해주고 있으므로, 기본적으로 해당 웹사이트를 참고하기 바란다.
- wsl2는 다음과 같은 주의 사항을 반드시 따라야만 사용할 수 있다.
- 윈도우10 업데이트가 최신 버전일 것: 윈도우 업데이트 확인은 "시작 버튼의 설정 > 업데이트 및 보안"을 통해 확인할 수 있다. "업데이트 확인"을 해본 후, 윈도우 업데이트를 실시하고, 만약 wsl2가 정상적으로 설치되지 않는다면, 컴퓨터를 재부팅하여 업데이트를 마무리해주길 바란다.
- CPU가 너무 구형이 아닐 것: Hyper-V를 구동시켜야만, wsl2와 같은 가상 머신을 사용할 수 있다. 2010년대 이전 CPU는 Hyper-V를 지원하지 않는 경우가 꽤 많으므로, 주의하길 바란다.
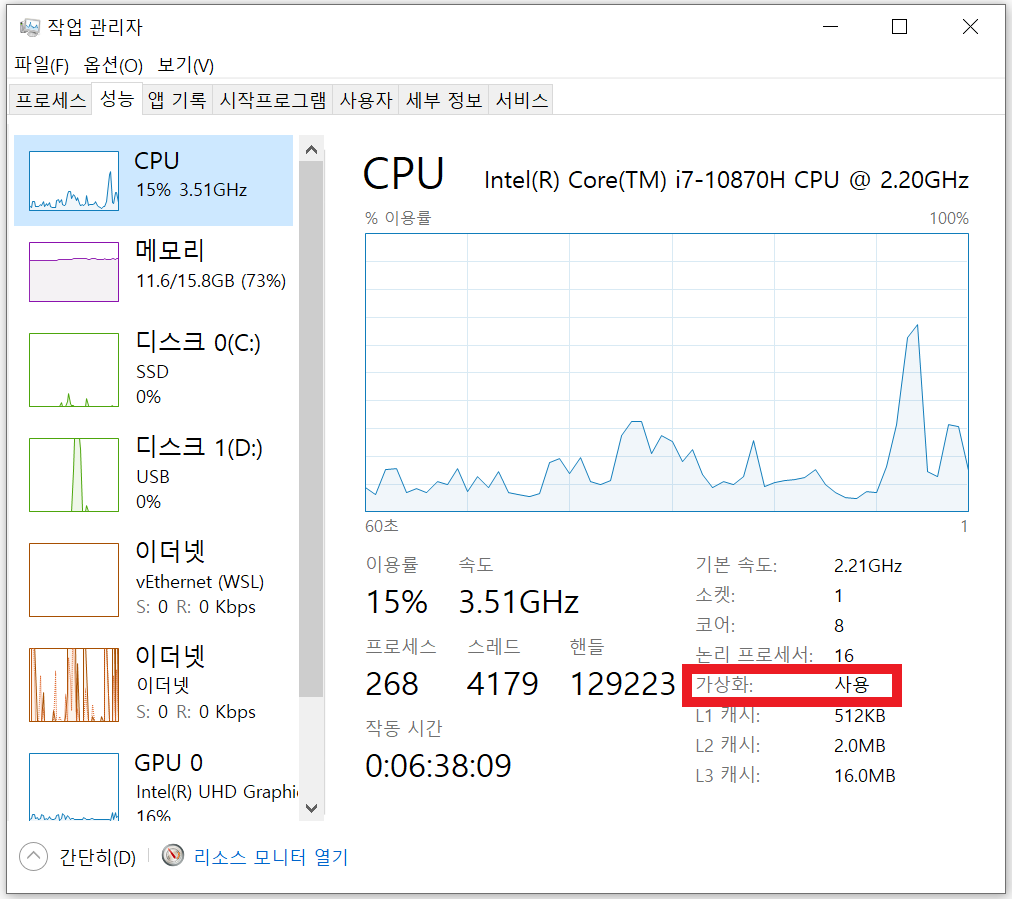
- 가상화 설정: "작업 관리자 > 성능"으로 들어가서 CPU의 가상화가 "사용"으로 되어 있는지 확인한다. 만약 사용이 안되어 있는 경우, BIOS에 들어가서 가상화를 설정해주어야 한다(메인보드 제조사마다 방식이 다르므로, 자신의 메인보드에 맞는 방법을 찾도록 하자).
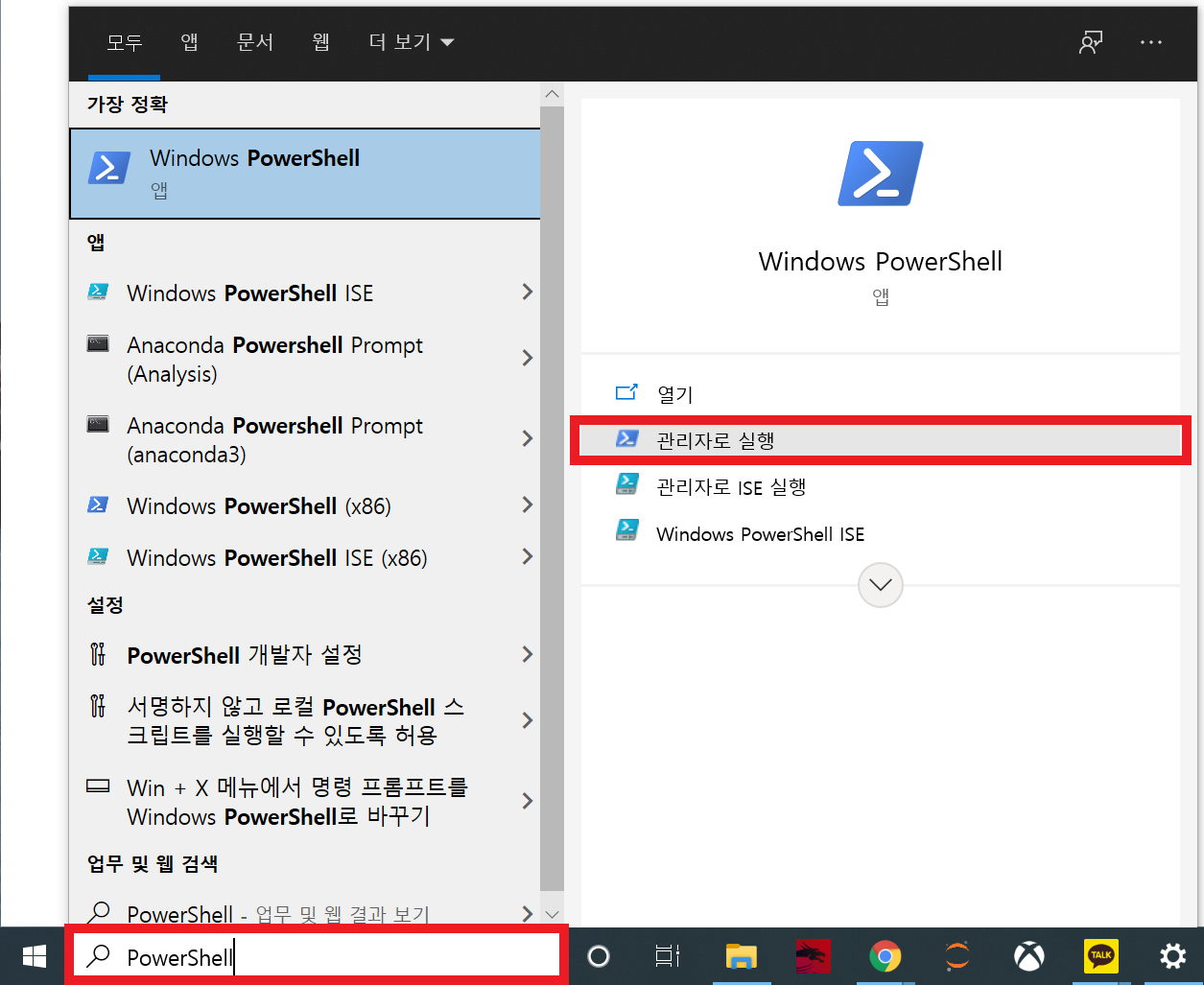
- 설명에서 헷갈릴 수 있는 부분은 "PowerShell의 관리자 권한 실행"이라 생각되는데, 시작 옆의 검색 기능을 이용하면 쉽게 할 수 있다.
- 이번 학습에서 Linux는 Ubuntu 18.04를 사용할 것이지만, 자신이 다루고자 하는 서버의 리눅스 환경이 다른 경우, 자신에게 맞는 것을 설치하면 된다(명령어는 크게 다르지 않으며, 명령어가 다르더라도 과정은 동일하다)
- 윈도우 터미널(Windows Terminal)을 마이크로소프트 스토어(Microsoft store)에서 설치하면, 보다 쉽게 wsl2의 기능을 사용할 수 있지만, 이번 포스트에서는 서버 환경과 동일한 상황에서 보기 위해 설치한 Ubuntu에서 진행해보겠다.
2.3. wsl2 설치 완료 후, 우분투 구동
- 우분투 설치 후, 설치된 파일을 실행해주자
- 실행 후, ID와 Password는 자신이 원하는 것으로 아무거나 입력해주면 된다.
- 그 후, 아래와 같은 화면으로 이동해주자.
3. 아나콘다 설치하기
- 설치된 가상 환경에 어떤 파일이 있는지 확인해보자.
ll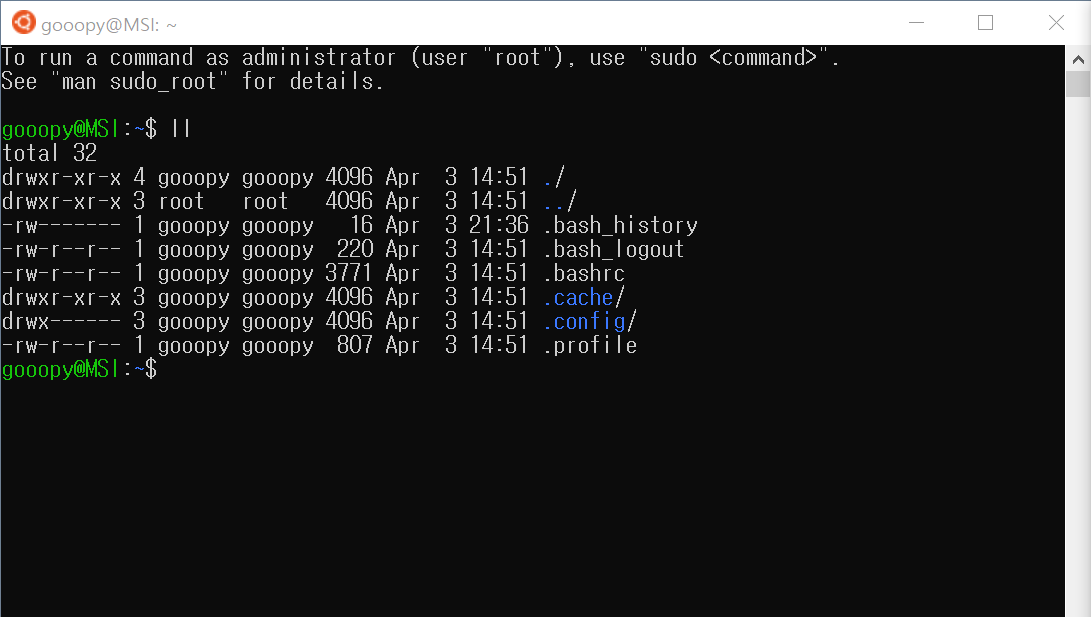
- ll: 현 디렉토리에 있는 파일들을 모두 보여주며, 해당 파일의 권한 등을 색으로 표현해준다.
(만약, 위와 같은 화면이 나오지 않는다면, cd를 입력하고 enter를 쳐서, 기본 디렉토리로 이동해주자)
3.1. Download 디렉토리 생성
- Download 디렉토리를 생성하여, 앞으로 다운로드할 파일들이 저장될 공간을 분리해주자.
(필수는 아니지만 디렉토리 정리가 잘될수록 관리가 쉬워지므로, 가능하면 꼭 해주도록 하자.)
mkdir Download
ll
- mkdir 디렉토리_이름: "디렉토리_이름"을 현 디렉토리에 생성한다.
3.2. 아나콘다 설치 파일을 Download 디렉토리에 설치하자
- 아나콘다를 설치하는 방법은 이전에 다뤘던 "python 파이썬과 아나콘다" 포스트와 거의 유사하다.
- 해당 포스트를 참고하여 아래 화면으로 이동해보자.
(아나콘다 버전에 따라 UI가 조금씩 달라질 수 있지만, 기본적인 방법은 같다)
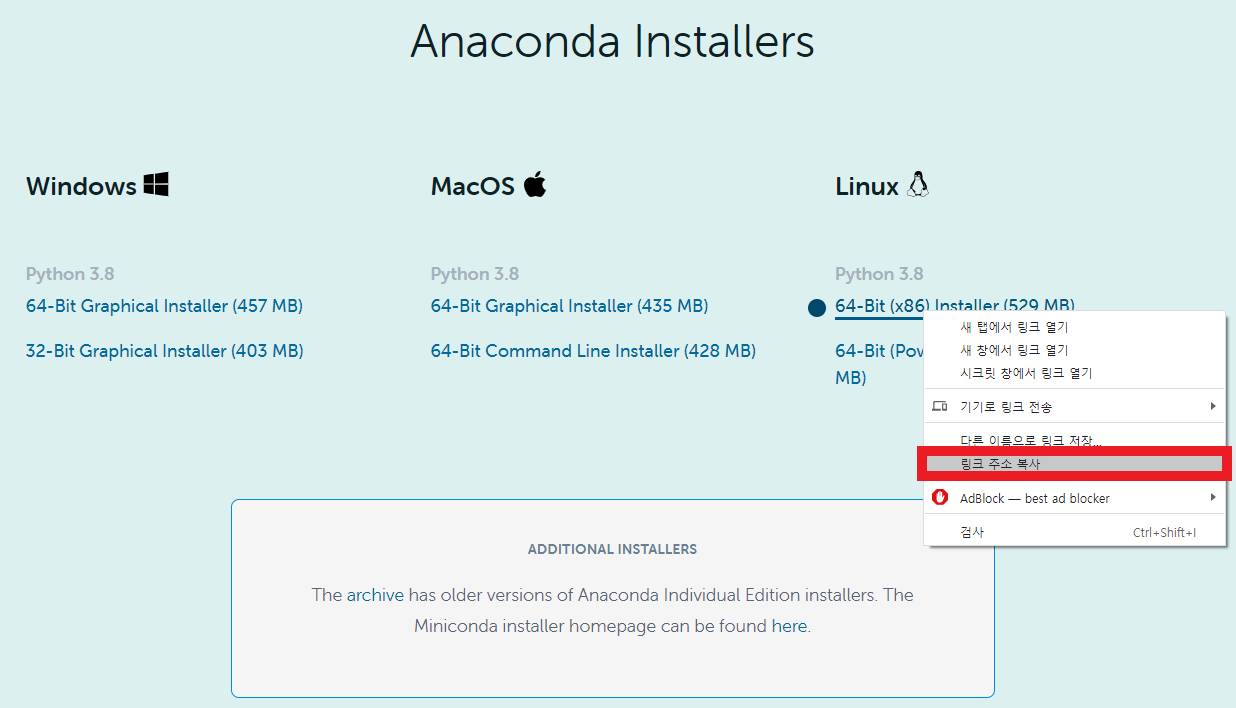
- Ubuntu는 Linux의 버전 중 하나이므로, Linux installer를 누르면 된다.
- Tensorflow를 사용할 것이므로 64Bit를 다운로드 받아야한다.
- "마우스 오른쪽 클릭 > 위 빨간 박스를 클릭"하여, 다운로드 받을 파일의 링크 주소를 복사하자.
cd Download
wget https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.sh
ll- 리눅스 화면에서 복사는, 복사하고 싶은 구간 드래그이며, 붙여 넣기는 커서에 마우스 오른쪽 클릭을 하면 된다.
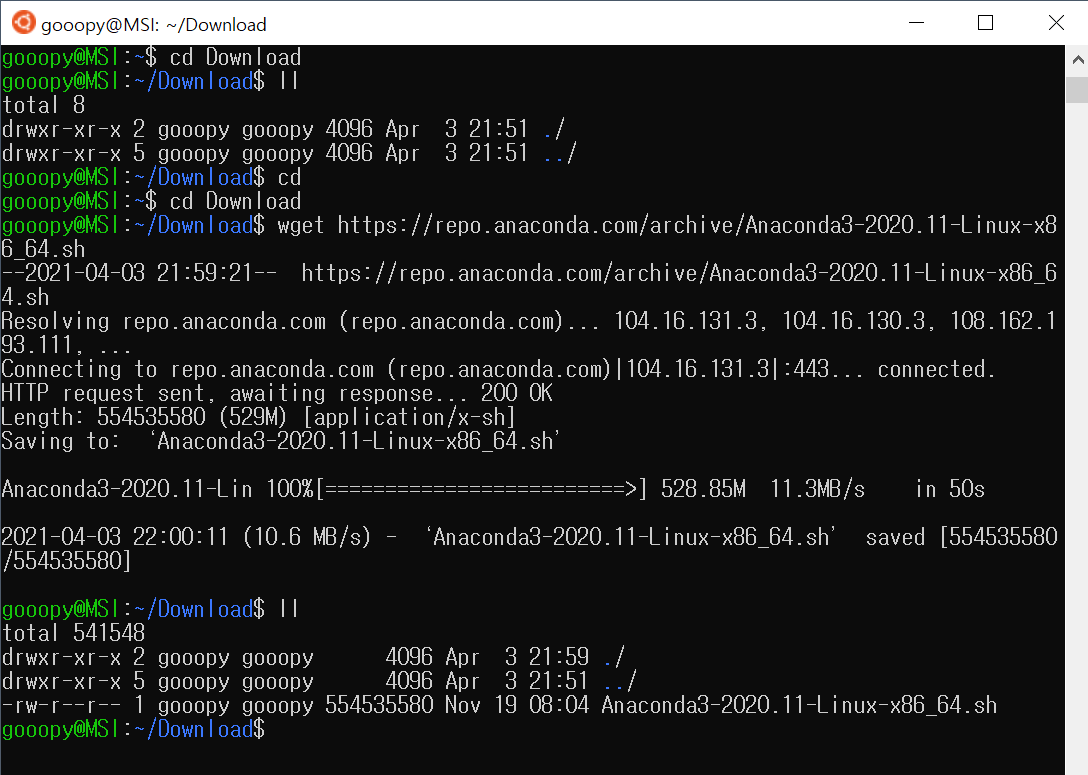
- wget 링크_주소: 인터넷에서 "링크_주소"에 해당하는 파일을 다운로드한다.
3.3. 아나콘다 설치 파일 권한 부여 및 실행
- 설치된 아나콘다 설치 파일의 색을 보면, 흰색으로 되어 있는 것을 볼 수 있다.
- 해당 파일을 실행하기 위해 권한을 부여해보도록 하자.
chmod 755 Anaconda3-2020.11-Linux-x86_64.sh
ll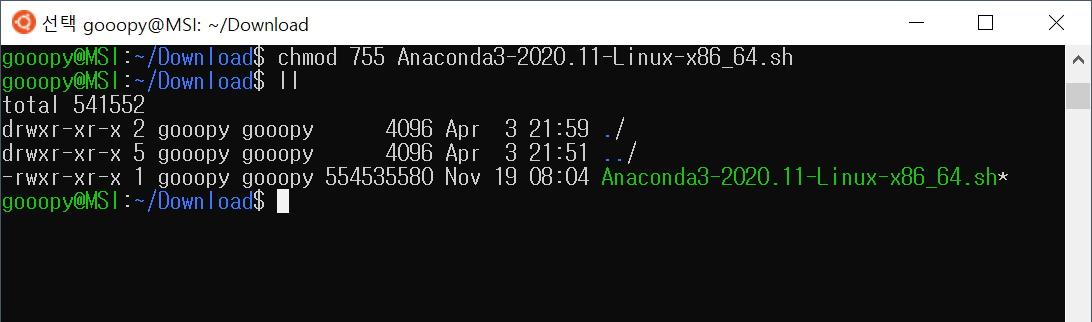
- 권한이 부여되어 파일의 색이 녹색으로 바뀐 것을 볼 수 있다.
- 해당 파일을 실행해보자.
./Anaconda3-2020.11-Linux-x86_64.sh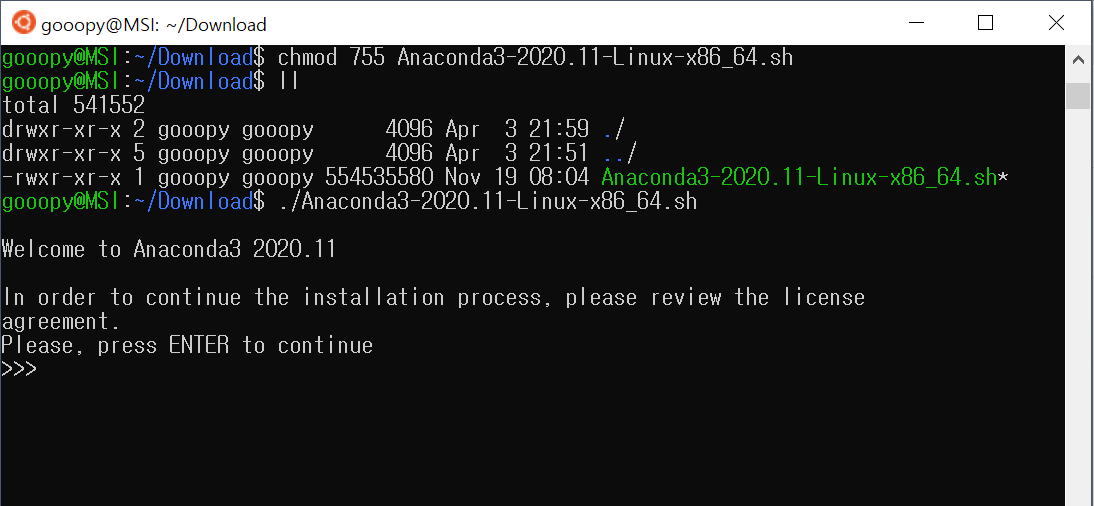
- Enter를 눌러, 쭉 진행해보자.
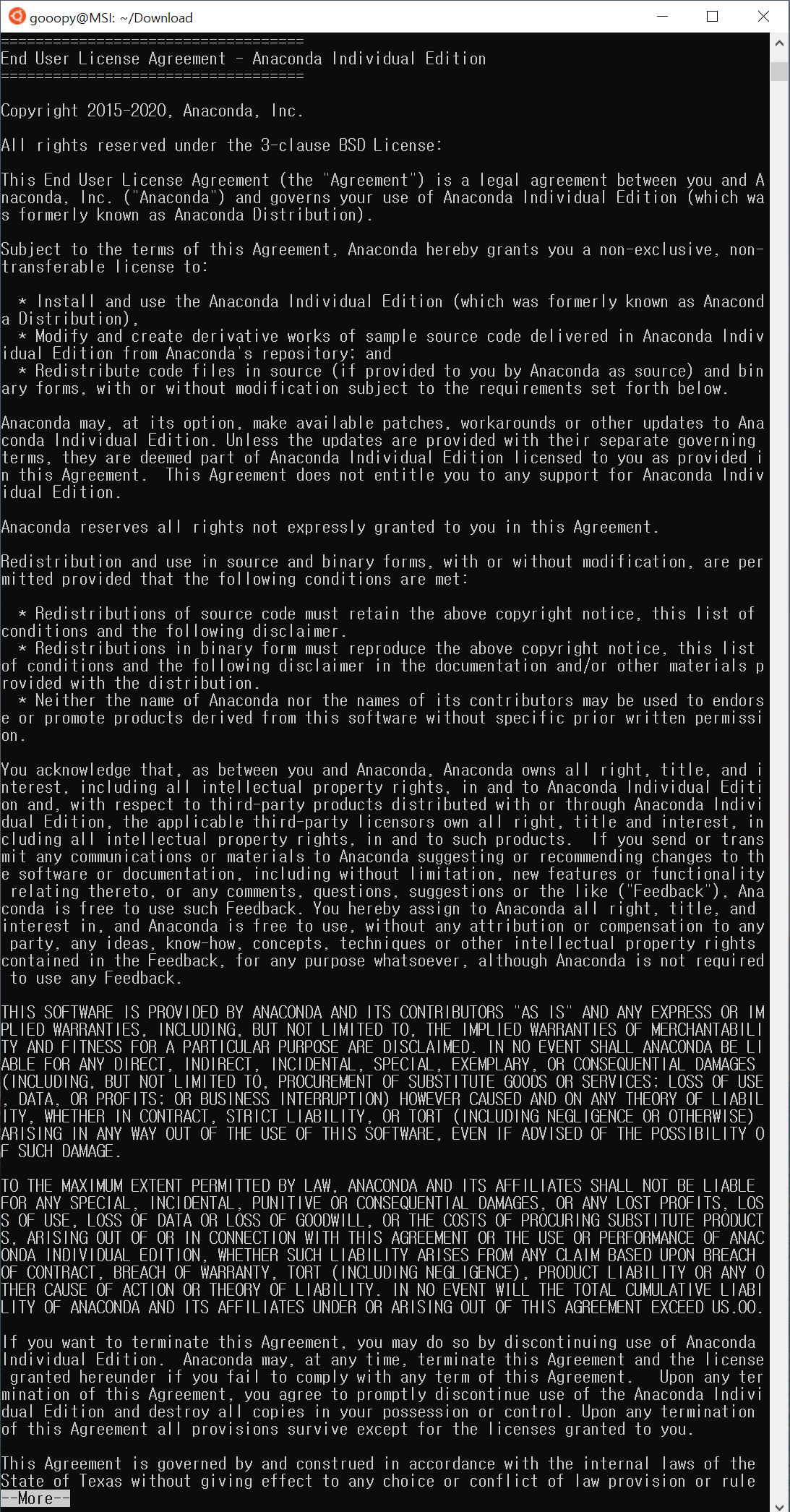
- 뭔가 엄청나게 많은 글이 뜨는데, 아나콘다 설치에 대한 약관이므로, 계속 엔터를 눌러 약관을 끝까지 내려주자.
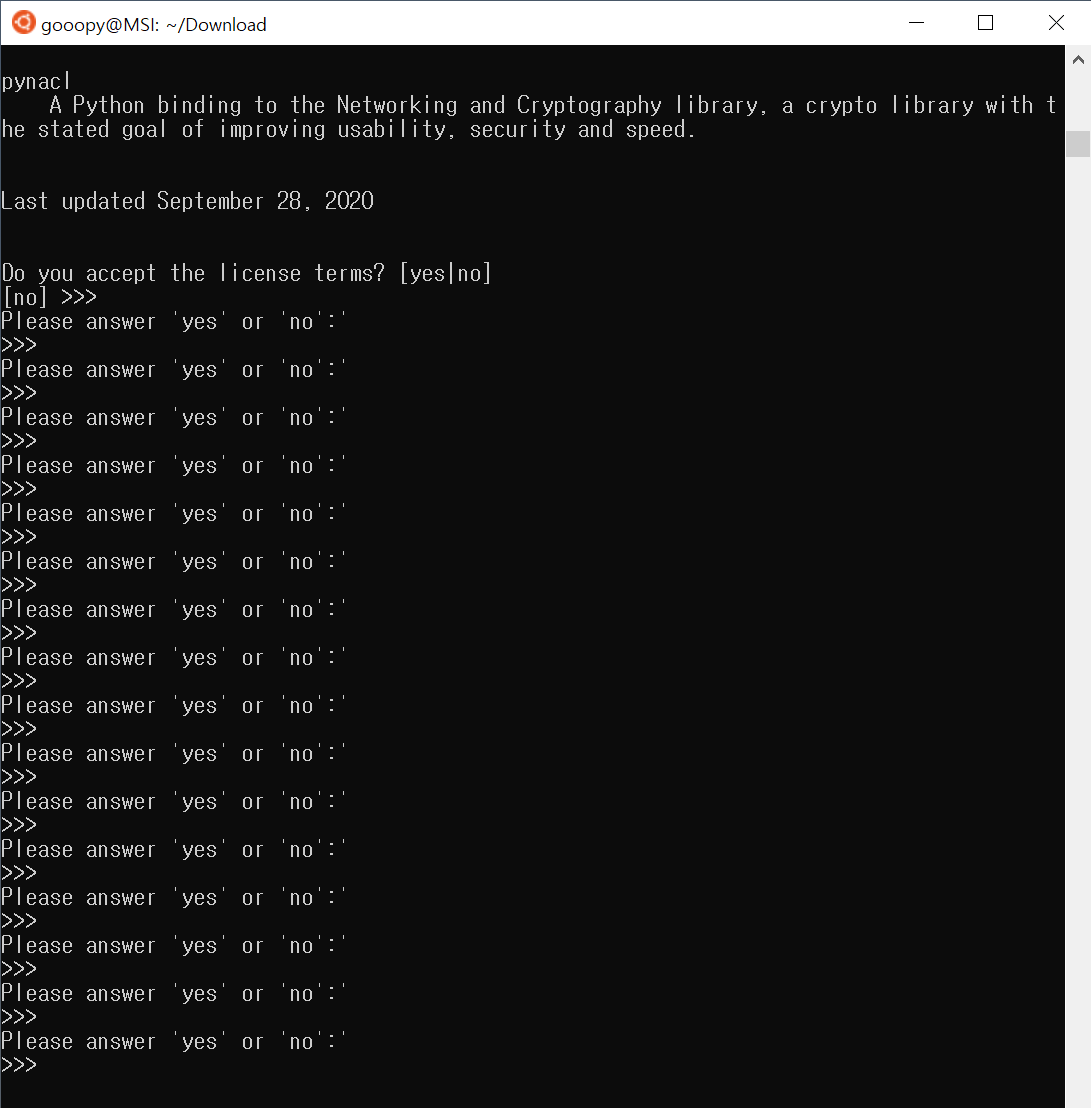
- yes를 입력하여 설치를 진행해주자.
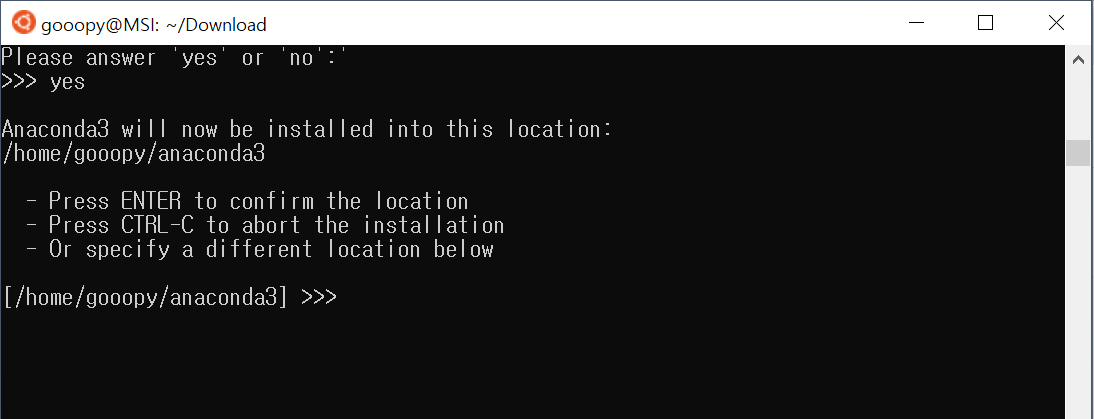
- Enter를 눌러서 아래 경로에 아나콘다를 설치해주자
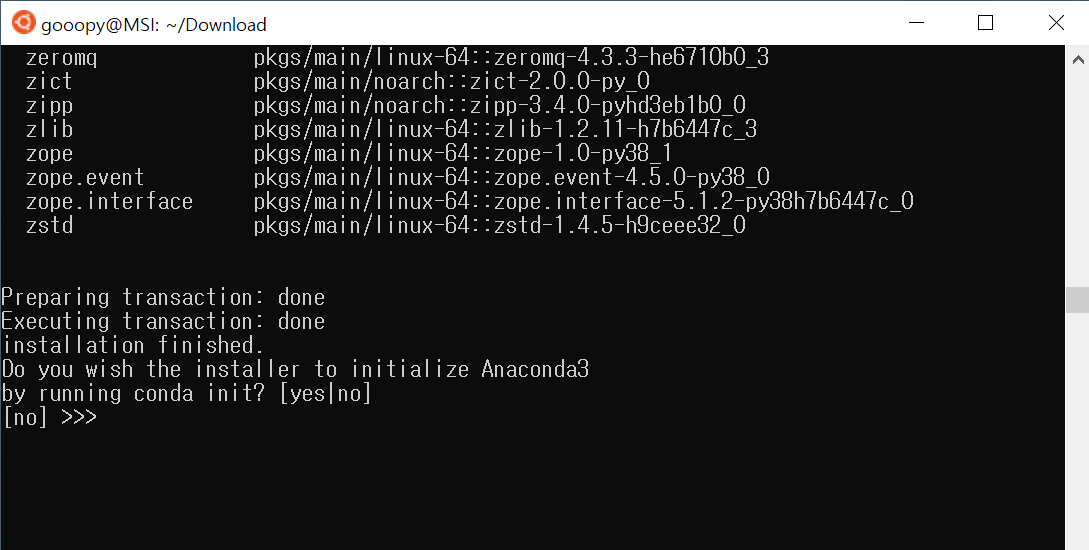
- yes를 입력해서, conda init 명령어로 Anaconda를 초기화 해주자.
3.4. 아나콘다 PATH 설정
- 위 과정까지 진행했다면, linux를 종료했다가 다시 키거나, bashrc를 실행하여 PATH를 설정해줘야 한다.
source ~/.bashrc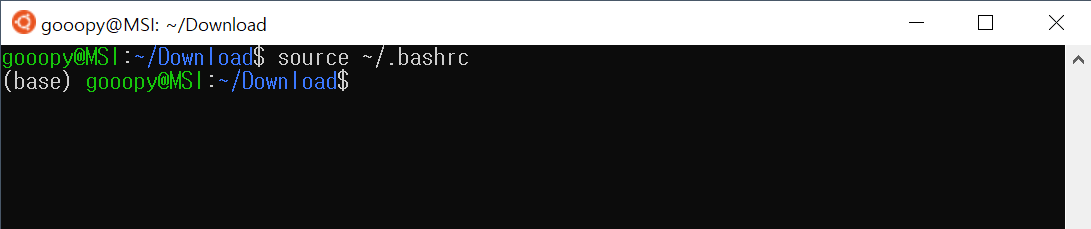
- 위 코드를 진행하면, 맨 왼쪽의 녹색 이름 옆에 (base)라는 글이 붙은 것을 볼 수 있다.
- 이는, 아나콘다 쉘이 실행된 것으로, 성공적으로 아나콘다가 설치 및 실행된 것을 볼 수 있다.
- 초기 화면으로 빠져나와, 설치된 아나콘다를 확인해보자.
cd
ll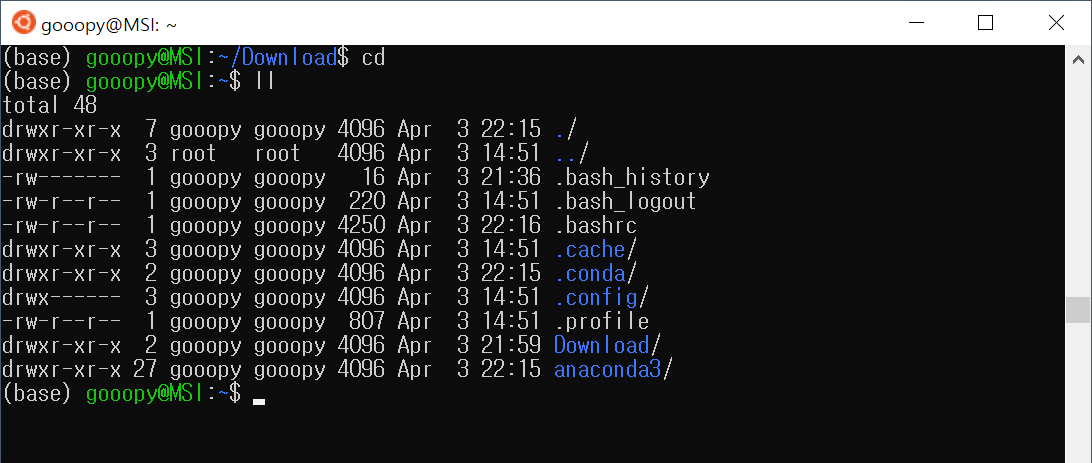
- 위 사진을 보면, 성공적으로 anaconda3가 설치된 것을 볼 수 있다.
지금까지 윈도우에 리눅스 기반 가상머신을 설치하고, 해당 가상머신에 아나콘다를 설치해보았다. 위 과정은 아나콘다 설치 파일을 다운로드하는 과정까지만 인터넷이 필요하며, 이후의 과정에서는 오프라인으로 진행해도 된다.
즉, 위 과정은 이후 분석 서버에 환경을 구축할 때도 다시 한번 진행되는 내용이다.
다음 포스트에서는 아나콘다 가상 환경을 만들고, 이를 압축하여, 외부로 내보내는 방법에 대해 알아보도록 하겠다.
'Python > 설치 및 환경설정' 카테고리의 다른 글
| Python 리눅스 서버에 분석 환경 구축3 - 가상환경 활성화와 주피터 노트북 (0) | 2021.04.06 |
|---|---|
| Python 리눅스 서버에 분석 환경 구축2 - 가상환경 만들고 내보내기 (0) | 2021.04.05 |
| Python 텐서플로우(Tensorflow)와 tensorflow-gpu 설치(Windows) (2) | 2020.06.28 |
| Python 오프라인 환경에서 파이썬 패키지를 설치해보자. (2) | 2020.06.26 |
| Python 필요한 모듈들을 설치해보자 (0) | 2020.06.26 |